API文档
HDFS API官方文档:https://hadoop.apache.org/docs/r3.3.1/api/index.html
环境配置
将Hadoop的Jar包解压到非中文路径(例如D:\hadoop\hadoop-2.7.2)
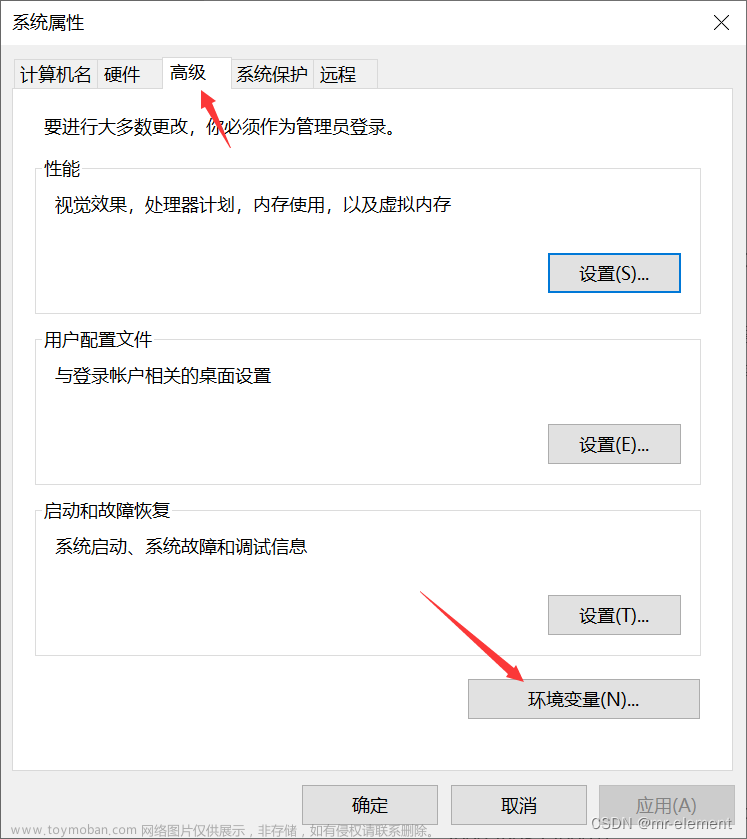
配置HADOOP_HOME环境变量

配置Path环境变量

API操作
准备工作
创建一个[Maven]工程HdfsClientDemo
引入hadoop-client依赖
<dependencies>
<dependency>
<grupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
创建HdfsClient 类文章来源:https://www.toymoban.com/news/detail-788373.html
创建文件夹
public class HdfsClient {
//创建目录
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
//连接的集群nn地址
URI uri = new URI("hdfs://node1:8020");
//创建一个配置文件
Configuration configuration = new Configuration();
//用户
String user = "atguigu";
//1、获取到了客户端对象
FileSystem fileSystem = FileSystem.get(uri, configuration, user);
//2、创建一个文件夹
fileSystem.mkdirs(new Path("/xiyou/huaguoshan"));
//3、关闭资源
fileSystem.close();
}
}
上面这样写代码有点冗余,我们通过AOP切面将初始化和关流的操作拆分出来,后续只需要关注核心逻辑就可以了。
实际开发中这样设计也不太好,建议搞个工厂类文章来源地址https://www.toymoban.com/news/detail-788373.html
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 连接的集群nn地址
URI uri = new URI("hdfs://node1:8020");
// 创建一个配置文件
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
// 用户
String user = "atguigu";
// 1、获取到了客户端对象
fs = FileSystem.get(uri, configuration, user);
}
@Test
public void testMkdir() throws URISyntaxException, IOException, InterruptedException {
//创建一个文件夹
fs.mkdirs(new Path("/xiyou/huaguoshan2"));
}
@After
public void close() throws IOException {
// 3、关闭资源
fs.close();
}
}
文件上传
@Test
public void testPut() throws IOException {
// 参数解读,参数1:表示删除原数据、参数2:是否允许覆盖、参数3:原数据路径、参数4:目的地路径
fs.copyFromLocalFile(false, true, new Path("D:\\bigData\\file\\sunwukong.txt"), new Path("hdfs://node1/xiyou/huaguoshan"));
}
文件下载
//文件下载
@Test
public void testGet() throws IOException {
//参数的解读,参数一:原文件是否删除、参数二:原文件路径HDFS、参数三:Windows目标地址路径、参数四:crc校验
// fs.copyToLocalFile(false, new Path("hdfs://node1/xiyou/huaguoshan2/sunwukong.txt"), new Path("D:\\bigData\\file\\download"), false);
fs.copyToLocalFile(false, new Path("hdfs://node1/xiyou/huaguoshan2/"), new Path("D:\\bigData\\file\\download"), false);
// fs.copyToLocalFile(false, new Path("hdfs://node1/a.txt"), new Path("D:\\"), false);
}
文件删除
//删除
@Test
public void testRm() throws IOException {
//参数解读,参数1:要删除的路径、参数2:是否递归删除
//删除文件
//fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"),false);
//删除空目录
//fs.delete(new Path("/xiyou"), false);
//删除非空目录
fs.delete(new Path("/jinguo"), true);
}
文件的更名和移动
//文件的更名和移动
@Test
public void testmv() throws IOException {
//参数解读,参数1:原文件路径、参数2:目标文件路径
//对文件名称的修改
fs.rename(new Path("/input/word.txt"), new Path("/input/ss.txt"));
//文件的移动和更名
fs.rename(new Path("/input/ss.txt"), new Path("/cls.txt"));
//目录更名
fs.rename(new Path("/input"), new Path("/output"));
}
获取文件详细信息
//获取文件详细信息
@Test
public void fileDetail() throws IOException {
//获取所有文件信息
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//遍历文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
//获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
到了这里,关于HDFS相关API操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!