问题来源:
在进行 pytorch 的本地 GPU 版本安装过程中屡次碰壁,第一个问题是在 pytorch 官网给的下载命令行执行不成功,第二个是成功在本地 GPU 下载 pytorch 后执行将向量值挪到 cuda 0 上时系统报错,内容为标题所示,这两个问题的具体解决方案如下所述。
解决方法一:
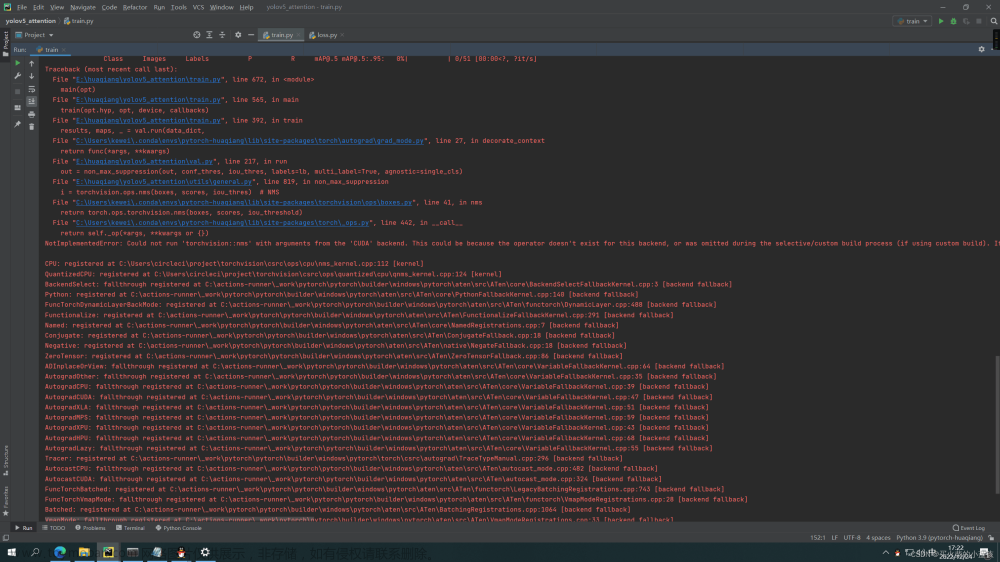
首先对于第一个问题,由于我本地下载的 cuda version 为11.7,但是由于 pytorch 官网没有更新到 cuda 11.7 版本对应的 pytorch,最高版本只有 cuda 11.6 对应的 pytorch,故我选择下载 cuda 11.6 对应的 pytorch 版本。值得注意的是,若你的本地 cuda 也同样为 11.x,则不应该下载 cuda 10.x 对应的 pytorch,如果这样的话后面可能会出现一些难以预测的 bug。挑选完 cuda 版本后,将生成的命令行粘贴到 Anaconda Powershell Prompt 上运行,发现一直报错,运行截图如下:

很纳闷,为何官网给的命令行会运行不起来?后来经过查询资料发现,是因为不能直接下载该版本 cuda 对应的 pytorch,故我在网上找到了手动下载 torch 以及对应的 torchvision 的网址并进行下载。
对于 torch 的下载网址为: https://download.pytorch.org/whl/torch_stable.html。下载你本机的 python 版本对应的 torch 版本到指定文件夹下,直接在该文件夹下打开 cmd,在命令行中执行如下命令:pip install ***.whl。python 版本与 torch 、 torchvision 版本的对应关系如下图所示:

分别对 torch 与 torchvision 都执行如上所述的操作后,打开 anaconda powershell prompt,输入如下命令:
>python
>>>import torch
>>>a = torch.ones((3,1)) //创建一个长度为 3 值为 1 的矩阵
>>>a = a.cuda(0) //将该矩阵挪到 cuda 0 也即时本机的 GPU 上
若如上命令行执行过程中均无报错则表明本机上成功安装了 torch 与对应的 torchvision。
解决方法二:
若解决方法一无法解决报错问题,则尝试第二种解决方法。
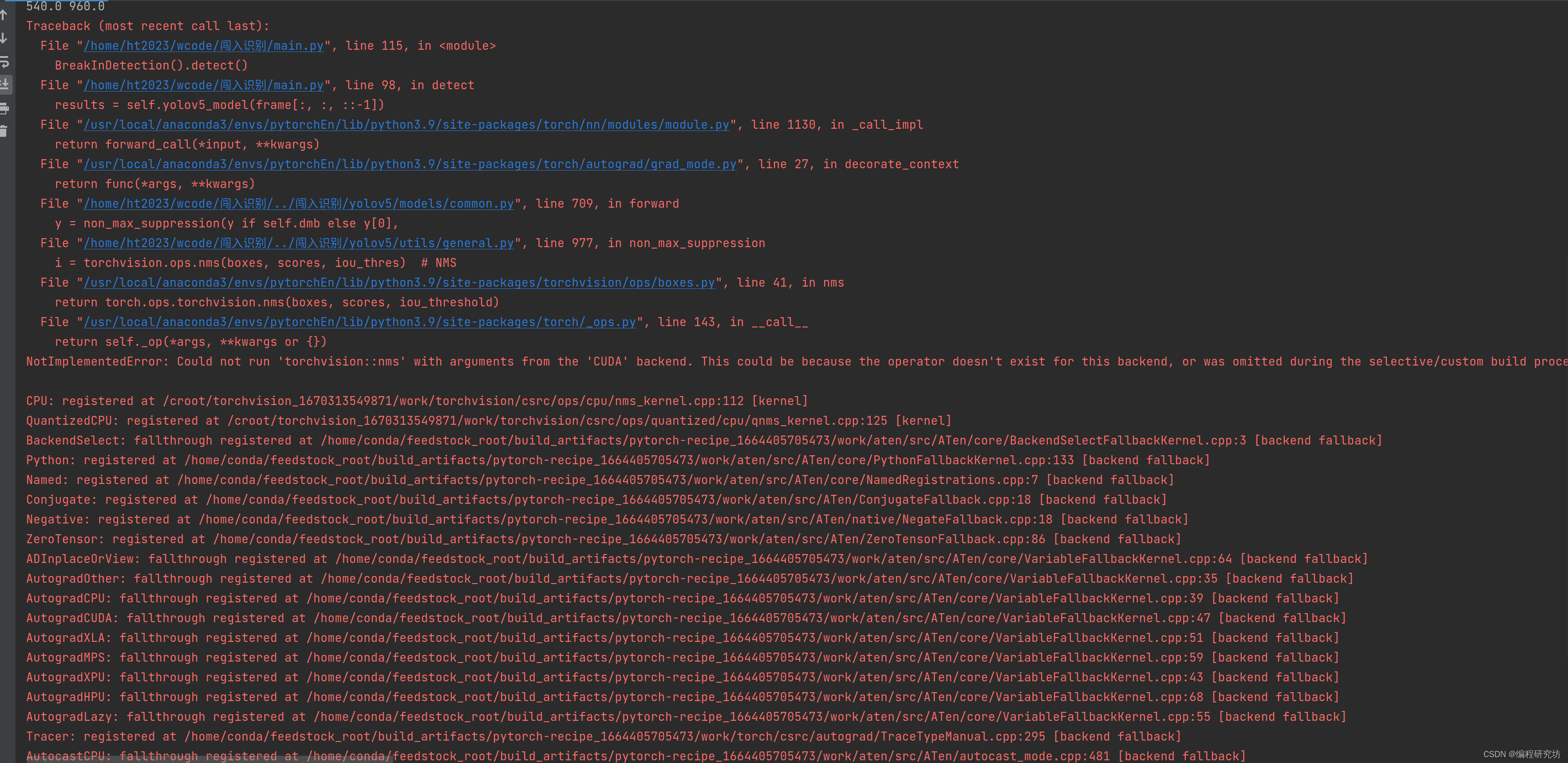
有可能在执行解决方法一最后的命令行时,发生如下报错:

这种情况很大可能是因为 torch 与 CUDA 的版本不兼容导致的,为了验证这一假设,可以在终端输入如下命令:

若和我一样,输出的结果是 False 的话,就表示引起报错的原因是 torch 与 CUDA 的版本不兼容导致的。此时首先查看 CUDA 版本,在终端输入如下命令:
nvcc -V
输出结果如下图所示

可以看到我本机的 CUDA 版本是 11.7。很多网友喜欢去英伟达控制面板上找 CUDA 的版本信息,但是有些情况下在英伟达控制面板上看到的 CUDA 版本信息可能与此处看到的不一,以此为准!
接着访问 Pytorch 的官网,找到与你本机 CUDA 对应版本的 Pytorch,并进行安装,具体操作如下:

若你的 CUDA 版本没有出现在官网给出可选的选项范围内,则进入下载其他版本的入口进行历史版本的下载:
 文章来源:https://www.toymoban.com/news/detail-788558.html
文章来源:https://www.toymoban.com/news/detail-788558.html
下载完后,解决了 CUDA 与 torch 版本不兼容问题,重复执行前面报错的那条命令,发现执行成功,错误解决。文章来源地址https://www.toymoban.com/news/detail-788558.html
到了这里,关于AssertionError:Torch not compiled with CUDA enabled的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!