一、MapReduce是什么?
MapReduce是一个开源的分布式软件框架,可以让你很容易的编写程序(继承Mapper和Reducer,重写map和reduce方法)去处理大数据。你只需要简单设置下参数提交下,框架会为你的程序安排任务,监视它们并重新执行失败的任务。下面让我们跟着官网来学习下吧
Apache Hadoop 3.3.6 – MapReduce Tutorial
二、运行流程大致描述
1、用户通过 job.waitForCompletion(true); 进行提交任务到集群,集群立即返回作业运行状态,并返回客户端监控该作业的信息
2、集群为作业分配相应的资源,并把程序移动到数据所在的节点或最近的节点
3、Map阶段处理数据,可以对相同key的数据做合并处理
4、shuffle阶段将map输出的数据被拉取到Reduce程序所在节点
5、Reduce阶段处理数据
6、将Reduce阶段结果输出到提交时设定的目录中
三、输入和输出
MapReduce框架仅对<Key,Value>对进行操作,即该框架将对作业的输入视为一组<Key,Value>对,并生成一组<Key,Value>对作为作业的输出。如下:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
四、WordCount 示例分析
我们通过一个MapReduce应用程序的例子来了解它是如何工作的。WordCount是一个简单的应用程序,可以计算给定输入集中每个单词的出现次数。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}1、输入数据制作并上传
$ vi file01.txt
Hello World Bye World
$ vi file02.txt
Hello Hadoop Goodbye Hadoop
$ hadoop fs -put file*.txt /user/hhs/wordcount/input/
2、运行作业
hadoop jar wc.jar WordCount /user/hhs/wordcount/input /user/hhs/wordcount/output
wc.jar:程序打成的jar包
WordCount:主程序包名.类名
/user/hhs/wordcount/input:输入数据所在路径
/user/hhs/wordcount/output:输出数据所在路径
3、结果查看
$ hadoop fs -cat /user/hhs/wordcount/output/part-r-00000
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
4、过程分析
Mapper实现通过map方法一次处理一行,由指定的TextInputFormat进行支持。然后通过StringTokenizer将行拆分并发出一个键值对<<word>,1>。map端输出结果为:
第一个输入文件file01.txt经过map处理后输出:
< Hello, 1>
< World, 1>
< Bye, 1>
< World, 1>
第二个输入文件file02.txt经过map处理后输出:
< Hello, 1>
< Hadoop, 1>
< Goodbye, 1>
< Hadoop, 1>
job.setCombinerClass(IntSumReducer.class); //指定了一个组合器,每个map的输出会按照key进行排序,并进行本地聚合,组合器设置的类可以和Reduce阶段用的类一样,也可以另外实现,但都需要继承Reducer。经过组合器处理后的结果如下
第一个输入文件map端最终输出:
< Bye, 1>
< Hello, 1>
< World, 2>
第二个输入文件map端最终输出:
< Goodbye, 1>
< Hadoop, 2>
< Hello, 1>
Reducer通过reduce方法只对值进行求和,这些值是每个键(即本例中的单词)的出现次数。输出结果为:
< Bye, 1>
< Goodbye, 1>
< Hadoop, 2>
< Hello, 2>
< World, 2>
五、核心类说明
1、Mapper
Mapper中的map方法是将输入的<Key,Value> 映射成 一组中间<Key,Value>,中间<Key,Value>不需要和输入<Key,Value>类型相同,输入的一个<Key,Value>也可以映射出0个或多个<Key,Value>。
Hadoop MapReduce框架为作业的InputFormat生成的每个InputSplit生成一个map任务。
job.setMapperClass(Class) 为作业传递具体的map实现,框架为该任务的InputSplit中的每个<Key,Value>调用map() ,并通过context.write() 来进行输出。自己编写的Mapper类可以通过setup()、cleanup() 来进行前置和后置处理。
应用程序可以使用计数器来报告其统计信息。
中间<Key,Value>随后由框架分组,并传递给Reducer以确定最终输出。用户可以通过Job.setGroupingComparatorClass(Class)指定一个比较器来控制分组。
map阶段会根据输出按每个Reducer进行排序和分区。分区总数与作业的Reduce任务数相同。用户可以通过实现自定义分区器来控制哪些<Key,Value>流向哪个Reducer。
用户可以选择通过Job.setCombinaterClass(Class)指定一个组合器来执行中间输出的本地聚合,这样会减少Map端输出量,相应的也会减少到Reduce端的传输量。
Map端也可以设置是否压缩中间结果。
那么一个作业会产生多少Map任务呢?
Map任务数量通常由输入文件的块数量决定,默认情况下是一个块对应一个Map任务。用户也可以通过mapreduce.input.fileinputformat.split.minsize来进行调节。
2、Reducer
Reducer中的reduce方法将对一个key的所有value来进行处理。
reduce任务的个数可以通过job.setNumReduceTasks(int)设置。
Reducer有三个主要阶段:shuffle、sort和reduce。
a、shuffle
Reducer的输入是map端的排序输出。在这个阶段,框架通过HTTP获取所有map端输出的相关分区。
b、sort
和shuffle同时发生并处理,在此阶段,框架按key对Reducer输入进行分组(因为不同的map可能输出相同的key)。
也可以通过Job.setSortComparatorClass(Class)指定一个Comparator,用来对value进行二次排序
c、reduce
job.setReducerClass(Class) 为作业传递具体的reduce实现,每个key调用一次reduce方法,并通过context.write() 来进行输出,输出结果不排序。自己编写的Reducer类可以通过setup()、cleanup() 来进行前置和后置处理。
那么一个作业会产生多少Reduce任务呢?
reduce任务数量似乎是0.95或1.75乘以(<节点数量>*<每个节点的最大容器数量>)。在0.95的情况下,所有的reduce都可以立即启动,并在map任务完成时开始传输map输出。使用1.75,速度更快的节点将完成第一轮reduce,并启动第二波reduce,从而更好地完成负载平衡。
reduce次数的增加增加了框架开销,但增加了负载平衡并降低了故障成本。
上面的缩放因子略小于整数,以便在框架中为推测任务和失败任务保留一些reduce的插槽。
如果不需要reduce阶段处理,那么reduce任务的数量就是0,map任务的输出也就是作业的结果。
3、Partitioner
分区器是用来对map任务输出的key进行分区,默认的分区器是HashPartitioner。
分区总数与作业的reduce任务数相同。因此,分区器可以控制将中间结果发送到m个reduce任务中的哪个任务进行处理。
4、Counter
Counter是MapReduce应用程序报告其统计信息的工具。
Mapper和Reducer实现可以使用Counter来报告统计信息。
六、作业配置
通过WordCount示例程序,我们可以看到我们可以通过job设置程序的主类、Mapper的处理类、Reducer的处理类、Combiner的处理类、输出结果类型、输入文件路径、输出文件路径。
此外还可以设置一些可选配置,比如比较器、要放在DistributedCache中的文件、是否要压缩中间和/或作业输出(以及如何压缩)、是否可以以推测的方式执行作业任务(setMapInvestivalExecution(布尔值)/setReduceSpeculativeExecution(boolean)),每个任务的最大尝试次数(setMaxMapAttempts(int)/setMaxReduceAttempts(int))等
当然,可以使用Configuration.set(String,String)/Configuration.get(String)
来设置/获取应用程序所需的任意参数。
七、执行环境设置
1、作业内存设置
mapreduce.map.memory.mb和mapreduce.reduce.memory.mb: 为每个map/reduce任务向调度程序请求的内存量,单位兆字节(mb),该值必须大于或等于传递给JavaVM的-Xmx,否则VM可能无法启动。默认值为-1。如果未指定或为非正,则根据mapreduce.map.java.opts、mapreduce.reduce.java.opts和mapreduce.job.heap.memory-mb.ratio推断。如果也未指定java opts,则将其设置为1024即1G。
2、Map阶段参数
map端的输出记录将被序列化到环形缓冲区中,元数据将被存储到记帐缓冲区中。当序列化缓冲区或元数据超过阈值时,缓冲区的内容将被排序并在后台写入磁盘,同时map继续向缓冲区输出记录。如果其中一个缓冲区在溢出过程中完全填充,map线程将阻塞。map完成后,所有剩余的记录都会写入磁盘,磁盘上的所有段都会合并到一个文件中。最大限度地减少溢出到磁盘的次数可以减少map时间,但同样也会占用map端内存。可以通过以下参数调节:
mapreduce.task.io.sort.mb 默认值100 对文件进行排序时要使用的缓冲区内存总量,以兆字节为单位。
mapreduce.map.sort.spill.percent 默认值0.80 序列化缓冲区中的阈值。一旦到达,线程将开始在后台将内容溢写到磁盘。
3、Shuffle/Reduce阶段内存参数
每个reduce通过HTTP将分区器分配给它的输出提取到内存中,并定期将这些输出合并到磁盘。如果map输出时指定了压缩,则每个输出都会解压缩到内存中。下面选项可以影响reduce之前数据合并到磁盘的频率,以及reduce期间分配给map输出的内存。
mapreduce.task.io.soft.factor 指定磁盘上要同时合并的段数。它限制了合并期间打开的文件和压缩编解码器的数量。如果文件数超过此限制,则合并将分几次进行。
mapreduce.reduce.merge.inmem.thresholds 在合并到磁盘之前提取到内存中的已排序映射输出的数量。与前面注释中的溢出阈值一样,这不是定义分区单元,而是定义触发器。在实践中,这通常被设置为非常高(1000)或禁用(0),因为在内存段中进行合并通常比从磁盘进行合并更快
mapreduce.reduce.shuffle.merge.percent 在内存内合并开始之前,获取的map输出的内存阈值,表示为分配给在内存中存储map输出的存储器的百分比。
mapreduce.reduce.shuffle.input.buffer.percent 内存的百分比,相对于通常在mapreduce.reduce.java.opts中指定的最大堆大小,可以在shuffle期间分配给存储map输出。
mapreduce.reduce.input.buffer.percent 相对于最大堆大小的内存百分比,在reduce过程中可以保留map输出。当reduce开始时,map输出将被合并到磁盘,直到剩余的输出低于此定义的资源限制为止。默认情况下,在reduce开始最大化reduce可用的内存之前,所有map输出都会合并到磁盘。
八、任务提交和监控
作业是用户与ResourceManager交互的主要界面。
Job提供了提交作业、跟踪作业进度、访问组件任务的报告和日志、获取MapReduce集群的状态信息等功能。
工作提交过程包括:
1、检查作业的输入和输出规格
2、计算作业的InputSplit值,也就是确定map任务数量
3、如有必要,为作业的DistributedCache设置必要的记帐信息
4、将作业的jar和配置复制到HDFS上的MapReduce系统目录中。
5、将作业提交到ResourceManager,并监视其状态(可选)
对于复杂的任务通常需要多个MapReduce程序链接执行,直接将上一个MapReduce的输出作为下一个MapReduce的输入即可。这里我们主要区分两种提交方式:
1、Job.submit():将作业提交到集群并立即返回。
2、Job.waitForCompletion(布尔值):将作业提交到集群并等待其完成。
九、作业输入
InputFormat描述MapReduce作业的输入规范。主要做了以下几点:
1、验证作业的输入规范。
2、将输入文件拆分为逻辑InputSplit实例,然后将每个InputSplit分配给一个单独的Mapper。
3、提供RecordReader实现,用于从逻辑InputSplit中收集输入记录以供map处理。
基于文件的InputFormat实现(通常是FileInputFormat的子类,默认是TextInputFormat)的默认行为是根据输入文件的总大小(以字节为单位)将输入拆分为逻辑InputSplit实例。输入文件在HDFS中的块大小被视为输入拆分的上限。下限通过mapreduce.input.fileinputformat.split.minsize设置。
显然,基于输入大小的逻辑拆分对于map来说是不可读的,因为必须遵守记录边界。这个问题通过RecordReader来解决,它负责处理记录边界,并向单个任务提供逻辑InputSplit的面向记录的视图。
如果用框架默认的TextInputFormat,且输入文件中有扩展名为.gz的输入文件,会使用适当的CompressionCodec自动对其进行解压缩,但是每个压缩文件都只能由一个map进行处理。
十、作业输出
OutputFormat(默认是TextOutputFormat)描述了MapReduce作业的输出规范,主要做了以下几点:
1、验证作业的输出规范;例如,检查输出目录是否不存在。
2、提供用于写入作业输出文件的RecordWriter实现。将结果输出到HDFS。
OutputCommitter
OutputCommitter描述了MapReduce作业的任务输出的提交,主要做了以下几点:
1、在初始化期间设置作业。例如,在作业初始化期间为作业创建临时输出目录。
2、作业完成后清理作业。例如,在作业完成后删除临时输出目录。
3、设置任务临时输出。
4、检查任务是否需要提交,如果任务失败/终止,输出将被清除
RecordWriter
RecordWriter将<key,value>输出到HDFS。
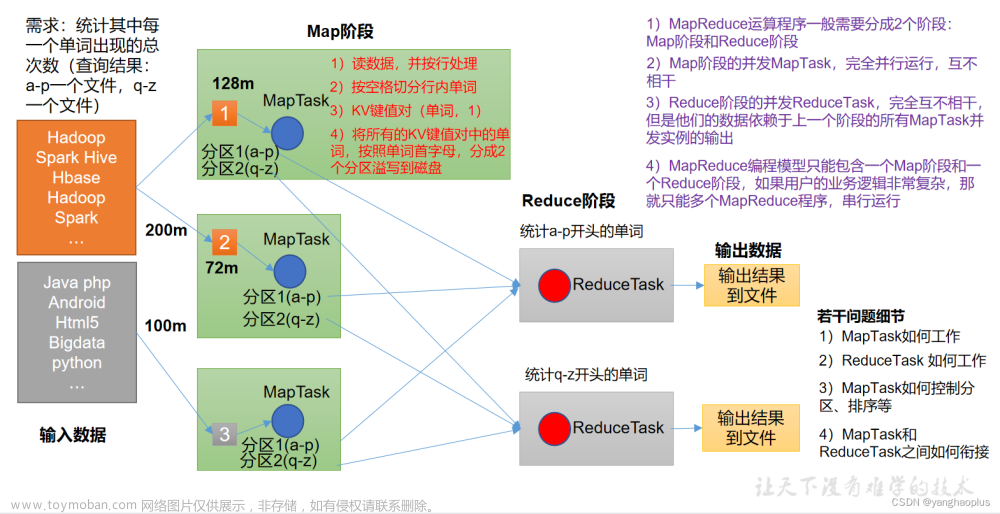
十一、计算流程图
我们通过以上的分析来画下MapReduce的计算流程图文章来源:https://www.toymoban.com/news/detail-788659.html
 文章来源地址https://www.toymoban.com/news/detail-788659.html
文章来源地址https://www.toymoban.com/news/detail-788659.html
到了这里,关于Hadoop-MapReduce使用说明的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![【Hadoop】- MapReduce概述[5]](https://imgs.yssmx.com/Uploads/2024/04/857929-1.png)