写在前面:本文为个人整理手册,有错误的地方欢迎指正,参考链接较多,重点参考,侵权删
什么是Selenium?
通俗的解释:
引用:Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。 Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。 Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行
官方点的解释:
Selenium是最广泛使用的开源Web UI(用户界面)自动化测试套件之一。它最初由Jason Huggins于2004年开发,作为Thought Works的内部工具。 Selenium支持跨不同浏览器,平台和编程语言的自动化。 Selenium可以轻松部署在Windows,Linux,Solaris和Macintosh等平台上。 此外,它支持iOS(iOS,Windows Mobile和Android)等移动应用程序的OS(操作系统)。 Selenium通过使用特定于每种语言的驱动程序支持各种编程语言。Selenium支持的语言包括C#,Java,Perl,PHP,Python和Ruby。目前,Selenium Web驱动程序最受Java和C#欢迎。 Selenium测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代Web浏览器中运行。 Selenium支持的浏览器包括Internet Explorer,Mozilla Firefox,Google Chrome和Safari。
可以查看参考链接,获得很多不同的理解
安装环境
selenium
pip install selenium即可
webdriver
本人使用的是谷歌驱动: chromedriver.exe ,下载链接
注!!!webdriver需要对照目前使用的浏览器版本下载相应的驱动版本 chromedriver与chrome版本映射表 其他浏览器的版本对应
将下载好的链接放在安装好的python主目录下就安装OK啦

demo.py
from selenium import webdriver
browser = webdriver.Chrome()#webdriver.Firefox() webdriver.Ie()
browser.get('http://www.baidu.com/')# get方法会一直等到页面被完全加载,然后才会继续程序
能打开百度链接就算成功
使用指南
启动浏览器
普通方式启动
例子等同于 demo.py
Headless方式启动
Headless Chrome 是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行你的程序。相比于现代浏览器,Headless Chrome 更加方便测试 web 应用,获得网站的截图,做爬虫抓取信息等。相比于较早的 PhantomJS,SlimerJS 等,Headless Chrome 则更加贴近浏览器环境。
Headless Chrome 对Chrome版本要求: 官方文档中介绍,mac和linux环境要求chrome版本是59+,而windows版本的chrome要求是60+,同时chromedriver要求2.30+版本。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
chrome_options = webdriver.ChromeOptions()# 使用headless无界面浏览器模式
chrome_options.add_argument('--headless') # 增加无界面选项
chrome_options.add_argument('--disable-gpu') # 如果不加这个选项,有时定位会出现问题
webdriver = webdriver.Chrome(chrome_options=chrome_options)# 启动浏览器,获取网页源代码
mainUrl = "https://www.taobao.com/"
webdriver.get(mainUrl)
print(f"browser text = {browser.page_source}")
webdriver.quit()
加载配置启动浏览器
Selenium操作浏览器是默认不加载任何配置的(简而言之就是模拟登录自己的浏览器账号)
下面是关于加载Chrome配置的方法:
用Chrome地址栏输入
chrome://version/,查看自己的“个人资料路径”,然后在浏览器启动时,调用这个配置文件,代码如下:#coding=utf-8 from selenium import webdriver option = webdriver.ChromeOptions() option.add_argument(r'--user-data-dir=C:\Users\yourUserName\AppData\Local\Google\Chrome\User Data') #设置成用户自己的数据目录 #注:必须是以 User Data 结尾 driver=webdriver.Chrome(chrome_options=option)
而加载Firefox配置的方法有些不同: 浏览器版本与Driver对应 浏览器版本与Driver对应 2 查看浏览器版本信息:右上角三条横线 --> 帮助 --> 排障信息 能看浏览器版本,也可以看配置文件目录
# coding=utf-8 from selenium import webdriver profile_directory = r'C:\Users\yourUserName\AppData\Roaming\Mozilla\Firefox\Profiles\xxxx.default'# 配置文件地址 profile = webdriver.FirefoxProfile(profile_directory)# 加载配置配置 driver = webdriver.Firefox(profile)# 启动浏览器配置 # ( 作者没试过 )
元素定位
引用:对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。一个对象就是一个人一样,他会有各种的特征(属性),如比我们可以通过一个人的身份证号,姓名,或者他住在哪个街道、楼层、门牌找到这个人。那么一个对象也有类似的属性,我们可以通过这个属性找到这对象。
可用函数
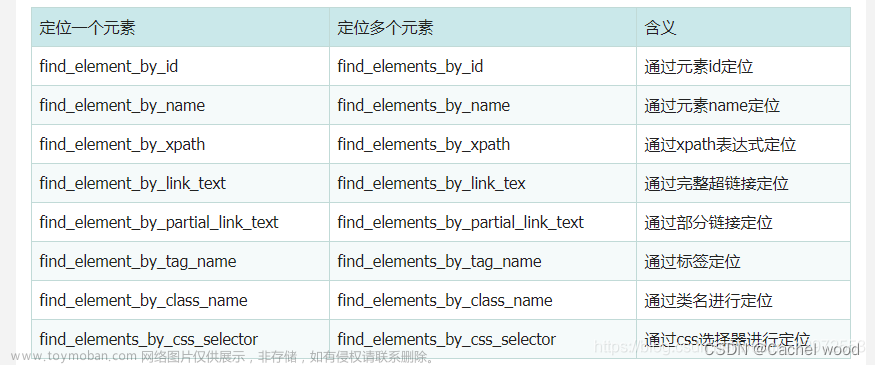
老版本 webdriver 提供了一系列的对象定位方法,常用的有以下几种:
inputTag = find_element_by_id('value') #id 定位 inputTag = find_element_by_class_name('value') #class定位 inputTag = find_element_by_name('value') #name定位 inputTag = find_element_by_link_text('value') #link定位 inputTag = find_element_by_partial_link_text('value') #partial_link定位 inputTag = find_element_by_tag_name('value') #tag定位 inputTag = find_element_by_xpath('value') #xpath定位 inputTag = find_element_by_css_selector('value') #css定位新版本 webdriver 压缩了这些方法:( 查找类型和上面的对应 )
inputTag = driver.find_element(By.ID,'value') inputTag = driver.find_element(By.CLASS_NAME,'value') inputTag = driver.find_element(By.NAME,'value') inputTag = driver.find_element(By.LINK_TEXT,'value') inputTag = driver.find_element(By.PARTIAL_LINK_TEXT,'value') inputTag = driver.find_element(By.TAG_NAME,'value') inputTag = driver.find_element(By.XPATH,'value') inputTag = driver.find_element(By.CSS_SELETOR,'value')
元素定位之后会结合操作测试对象来使用,例如点击含有 baidu.com 的链接
inputTag = driver.find_element(By.PARTIAL_LINK_TEXT,'value') inputTag.click() inputTag.text # 返回元素中的内容
填充表单
我们已经知道了怎样向文本框中输入文字,但是有时候我们会碰到<select> </select>标签的下拉框,直接点击下拉框中的选项不一定可行

Selenium 专门提供了 Select 类来处理下拉框。WebDriver 中提供了一个叫 Select 的方法,可以帮助我们完成这些事情:
from selenium.webdriver.support.ui import Select # 导入 Select 类
select = Select(driver.find_element(By.NAME,'status')) # 找到 name 的选项卡
select.select_by_index(1) # _index 索引从 0 开始
select.select_by_value("0") # _value 是 option 标签的一个属性值,并不是显示在下拉框中的值
select.select_by_visible_text(u"未审核") # _visible_text 是在 option 标签文本的值,是显示在下拉框的值
select.deselect_all() # 全部取消选择
class含有空格时 解决方法
在实际进行元素定位时,经常发现class name是有多个class组合的复合类,中间以空格隔开。如果直接进行定位会出现报错,可以通过以下方式处理:
class属性唯一但是有空格,选择空格两边唯一的那一个
若空格隔开的class不唯一可以通过索引进行定位 self.driver.find_elements_by_class_name('table-dragColumn')[0].click()
通过css方法进行定位(空格以‘.’代替)
self.driver.find_element(By.CSS_SELECTOR,'.dtb-style-1.table-dragColumns').click()#前面加(.) 空格地方用点(.)来代替 self.driver.find_element(By.CSS_SELECTOR,'class="dtb-style-1 table-dragColumns').click() # 包含整个类
参考代码:
# 方法一:取单个class属性
driver.find_element(By.CLASS_NAME,"dlemail").send_keys("yoyo")
driver.find_element(By.CLASS_NAME,"dlpwd").send_keys("12333")
# 方法二:定位一组取下标定位(乃下策)
driver.find_elements(By.CLASS_NAME,"j-inputtext")[0].send_keys("yoyo")
driver.find_elements(By.CLASS_NAME,"j-inputtext")[1].send_keys("12333")
# 方法三:css定位
driver.find_element(By.CSS_SELECTOR,".j-inputtext.dlemail").send_keys("yoyo")
driver.find_element(By.CSS_SELECTOR,".j-inputtext.dlpwd").send_keys("123")
# 方法四:取单个class属性也是可以的
driver.find_element(By.CSS_SELECTOR,".dlemail").send_keys("yoyo")
driver.find_element(By.CSS_SELECTOR,".dlpwd").send_keys("123")
# 方法五:直接包含空格的CSS属性定位大法
driver.find_element(By.CSS_SELECTOR,"[class='j-inputtext dlemail']").send_keys("yoyo")
报错处理
定位元素过程中经常会遇到找不到元素的问题,出现该问题一般都是以下因素导致:
-
元素定位方法不对
-
页面存在 iframe 或 内嵌窗口 --->(需要切换到相应 iframe 或 内嵌窗口 )
-
页面超时 ---> (设置等待时间)
操作测试对象
一般来说,webdriver 中比较常用的操作对象的方法有下面几个:
click —— 点击对象
send_keys —— 在对象上模拟按键输入
clear —— 清除对象的内容,如果可以的话
submit —— 提交对象的内容,如果可以的话
text —— 用于获取元素的文本信息
键盘事件
模拟键盘的一系列操作 要先导入
from selenium.webdriver.common.keys import Keys
可用函数
test = driver.find_element_by_id("sousuo")#寻找到目标元素(假设为账号密码登录框)
test.clear() # 清除原本可能有的字符串
test.send_keys("fnngj") # 模拟键盘输入 "fnngj"
test.send_keys(Keys.TAB) # 模拟键盘输入 TAB 键
test.send_keys(Keys.ENTER)# 模拟键盘输入 Enter 键,等同于 定位按钮.点击按钮
#键盘组合键的用法:
test.send_keys(Keys.CONTROL,'a')# 模拟键盘输入 Ctrl+'a' 选中全部
Keys.TAB # TAB 键
Keys.CONTROL # Ctrl 键
Keys.ENTER # Enter 键
Tips:定位在账号框,tab转入密码框,也能达到清除默认字符串的目的
鼠标事件
模拟鼠标的操作(鼠标事件一般包括鼠标右键、双击、拖动、移动鼠标到某个元素上等等) 要先导入
from selenium.webdriver.common.action_chains import ActionChains( ActionChains类 )#ActionChains常用方法: perform() #执行行为;(需要是所有 ActionChains 中存储的) context_click() #右击; double_click() #双击; drag_and_drop() #拖动; move_to_element() #鼠标悬停。
可用函数
#双击
qqq = driver.find_element_by_xpath("xxx") #定位到 driver 浏览器中要双击的元素
ActionChains(driver).double_click(qqq).perform() #对 driver 浏览器中定位的 qqq 元素执行 双击操作
#拖放
element = driver.find_element_by_name("source") # 定位元素的原位置
target = driver.find_element_by_name("target") #定位元素要移动到的目标位置
ActionChains(driver).drag_and_drop(element, target).perform()#执行元素的移动操作
#移动到 ac 位置
ac = driver.find_element_by_xpath('element') #定位元素的位置
ActionChains(driver).move_to_element(ac).perform()
# 单击
ac = driver.find_element_by_xpath("elementA")
ActionChains(driver).move_to_element(ac).click(ac).perform()
#右击
ac = driver.find_element_by_xpath("elementC")
ActionChains(driver).move_to_element(ac).context_click(ac).perform()
#左键单击hold住
ac = driver.find_element_by_xpath('elementF')
ActionChains(driver).move_to_element(ac).click_and_hold(ac).perform()
执行JS脚本
简易上手版
js = 'alert(1)' driver.execute_script(js) #写好js代码,直接执行就行了
使用参数
使用 Javascript 语句时,可以动态传入参数,元素对象 使用 Javascript 语句中使用占位符“argument[n]”来表示取第几个参数,如:
js = "arguments[0].setAttribute('style', arguments[1]);" # 这里埋设两个参数,一个是元素对象,另一个是样式字符串。
element = driver.find_element(By.ID,"kw") #设置两个参数
style = "background: red; border: 2px solid yellow;"
driver.execute_script(js, element, style) #使用 js 脚本,传入 js 语句和两个参数,按顺序携带参数
带返回值
js = 'return document.documentElement.scrollHeight;' # 在JS语句前加上return字样,如获取页面高度: page_height = driver.execute_script(js) # 执行该后便可以拿到其返回值: print(page_height) # page_height == 890
浏览器操作
基本操作
browser.maximize_window()#最大化显示
browser.minimize_window()#最小化显示
#设置窗口大小
browser.set_window_size(480, 800) #设置浏览器宽480、高800显示
#浏览器前进后退
browser.forword() #前进
browser.back() #后退
browser.save_screenshot("baidu.png")# 浏览器界面截图
browser.close() # 关闭当前页面,如果只有一个页面,会关闭浏览器
browser.quit() # 关闭浏览器
driver.switch_to.window("this is window name")# 切换窗口
#或者使用 window_handles 方法来获取每个窗口的操作对象
for handle in driver.window_handles:
driver.switch_to_window(handle)
for cookie in driver.get_cookies():
print("%s -> %s" % (cookie['name'], cookie['value'])) # 获取页面每个Cookies值
driver.delete_cookie("CookieName")# 依据名字删除 cookie
driver.delete_all_cookies()# 删除所有 cookie
弹窗处理
alert = driver.switch_to_alert() # 当页面出现了弹窗提示,处理这个提示或者获取提示信息的方法
等待加载
有时候为了保证脚本运行的稳定性,需要脚本中添加等待时间。
某些元素需要该元素加载完成才能定位
selenium 有三种等待方式:
强制等待
准确的说这种等待方式并不是 selenium 提供的,需要引用 time 模块 import time 这种方式是使脚本的运行在 time.sleep(3)时强制停止3秒运行,这时候就可以等浏览器加载(脚本的停止不会影响浏览器的加载) 调试代码时很有用,但是会严重影响脚本的运行的高效性(比如说暂停10s,但其实浏览器在4s左右就加载完成了)
隐性等待
selenium 提供的 implicitly_wait() 方法可以方便的实现智能等待 implicitly_wait(30) 的处理方式比 time.sleep() 更智能
from selenium import webdriver driver.implicitly_wait(30) # 隐性等待,最长等30秒
implicitly_wait() 方法是设置了一个最长等待时间,如果在规定的时间内,整个网页加载完成,则执行下一步,否则等到设置的最大时长后,继续执行下一步相对于time.sleep()来说确实智能了很多,但是仍然不算是足够智能,有时候我们需要定位的元素一开始就能够加载完毕,但是因为其他原因,有一些我们不关心也用不上的元素加载时间过长,也会导致我们等待时间超过我们的理想值。
PS:需要特别说明的是:隐性等待对整个driver的周期都起作用,所以只要设置一次即可,而不是像
time.sleep()一样,需要等待时都使用一遍
显性等待
如果我们想要我们关心的,需要查询,定位的元素一加载好就继续执行,下一步的话,就需要用到WebDriverWait类,配合该类提供的until()和until_not()方法,就能够依据脚本的需求,灵活的等待了
它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
导入WebDriverWait:from selenium.webdriver.support.ui import WebDriverWait 关于 WebDriverWait 的详细介绍放在部分函数详解 这里给出一个例子:
WebDriverWait(driver, timeout=3).until(lambda d: d.find_element(By.TAG_NAME, "h1"))依照 tag_name查找元素,对应查找的元素加载完成后立刻继续执行,否则等到超时再继续运行
Tips:隐式等待和显示等待都存在时,超时时间取二者中较大的
多层框架/层级定位
如果定位的元素位于 iframe 标签里的话, webdriver 提供了一个 switch_to_frame 方法,可以很轻松的来切换 iframe 或者 窗口。
browser.switch_to_frame("f1") # 找到 id = f1 的 iframe 标签并切换
browser.switch_to_window("f1")# 找到 id = f1 的窗口并切换
#或者
browser.switch_to.frame("f1")#支持的python版本不同
browser.switch_to.window("f1")
Expected Conditions解析
Expected Conditions解析 Webdriver Exception速查表 和 Xpath&Css定位方法速查表 就直接引用大佬文章了
Expected Conditions的使用场景有2种:
-
直接在断言中使用
-
与 WebDriverWait 配合使用,动态等待页面上元素出现或者消失
相关方法:
title_is ---> #判断当前页面的title是否精确等于预期 title_contains ---> # 判断当前页面的title是否包含预期字符串 presence_of_element_located ---> #判断某个元素是否被加到了dom树里,并不代表该元素一定可见 visibility_of_element_located ---> #判断某个元素是否可见.可见代表元素非隐藏,并且元素的宽和高都不等于0 visibility_of ---> #跟上面的方法做一样的事情,只是上面的方法要传入locator,这个方法直接传定位到的element就好了 presence_of_all_elements_located ---> #判断是否至少有1个元素存在于dom树中。举个例子,如果页面上有n个元素的class都是'column-md-3',那么只要有1个元素存在,这个方法就返回True text_to_be_present_in_element ---> #判断某个元素中的text是否包含了预期的字符串 text_to_be_present_in_element_value ---> #判断某个元素中的value属性是否包含了预期的字符串 frame_to_be_available_and_switch_to_it ---> #判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False invisibility_of_element_located ---> #判断某个元素中是否不存在于dom树或不可见 element_to_be_clickable ---> #判断某个元素中是否可见并且是enable的,这样的话才叫clickable staleness_of ---> #等某个元素从dom树中移除,注意,这个方法也是返回True或False element_to_be_selected ---> #判断某个元素是否被选中了,一般用在下拉列表 element_selection_state_to_be ---> #判断某个元素的选中状态是否符合预期 element_located_selection_state_to_be ---> #跟上面的方法作用一样,只是上面的方法传入定位到的element,而这个方法传入locator alert_is_present ---> #判断页面上是否存在alert,这是个老问题,很多同学会问到
示例: 判断title:title_is()、title_contains()
首先导入expected_conditions模块 由于这个模块名称比较长,所以为了后续的调用方便,重新命名为EC了(有点像数据库里面多表查询时候重命名) 打开博客首页后判断title,返回结果是True或False
from selenium.webdriver.support import expected_conditions as EC title = EC.title_is(u'百度') # 判断title完全等于 print(title(driver)) title1 = EC.title_contains(u'百度')# 判断title包含 print(title1(driver)) r1 = EC.title_is(u'百度')(driver) # 另外一种写法 r2 = EC.title_contains(u'百度')(driver)
报错
报错解决
AttributeError: 'WebDriver' object has no attribute 'find_element_by_id' 解决方案:
增加导入包
from selenium.webdriver.common.by import By然后将左侧函数格式改为右侧即可,赋值是方便二次调用,可选
| 旧版本函数格式 | 功能 | 新版本函数格式 |
|---|---|---|
| inputTag = driver.find_element_by_id('value') | ID查找 | inputTag = driver.find_element(By.ID,'value') |
| inputTags = driver.find_element_by_class_name('value') | 类名查找 | inputTag = driver.find_element(By.CLASS_NAME,'value') |
| inputTag = driver.find_element_by_name('value') | name属性查找 | inputTag = driver.find_element(By.NAME,'value') |
| inputTag = driver.find_element_by_tag_name('value') | 标签名查找 | inputTag = driver.find_element(By.TAG_NAME,'value') |
| inputTag = driver.find_element_by_xpath('value') | xpath查找 | inputTag = driver.find_element(By.XPATH,'value') |
| inputTag = driver.find_element_by_css_selector('value') | CSS选择器 | inputTag = driver.find_element(By.CSS_SELETOR,'value') |
| inputTag = driver.find_element_by_link_text() | link 文本(完整搜索) | inputTag = driver.find_element(By.LINK_TEXT,'value') |
| inputTag = driver.find_element_by_partial_link_text() | link text (部分搜索) | inputTag = driver.find_element(By.PARTIAL_LINK_TEXT,'value') |
Message: no such element: Unable to locate element: {"method":"css selector","selector":"[id="1"]"} 解决方案:
可能是Web页面的DOM树还没加载完,如果程序不是阻塞执行,那么是存在DOM树还未加载完,但是程序已经往下跑了的可能性的。解决方案很简单,让程序等待一会,等到DOM树加载完成在执行后续操作。
可以使用 time.sleep() 等待或者使用 WebDriverWait 等待指定元素加载完成
from selenium.webdriver.support.wait import WebDriverWaitWebDriverWait(driver, timeout=3).until(lambda d: d.find_element(By.TAG_NAME, "h1"))
'WebDriver' object has no attribute 'switch_to_frame' webdriver 提供了 switch_to_frame 方法,但是由于支持的 python 版本不同,需要切换为 browser.switch_to.frame("f1")
Webdriver Exception速查表
webdriver在使用过程中可能会出现各种异常,我们需要了解该异常并知道如何进行异常处理。
| 异常 | 描述 |
|---|---|
| WebDriverException | 所有webdriver异常的基类,当有异常且不属于下列异常时抛出 |
| InvalidSwitchToTargetException | 下面两个异常的父类,当要switch的目标不存在时抛出 |
| NoSuchFrameException | 当你想要用switch_to.frame()切入某个不存在的frame时抛出 |
| NoSuchWindowException | 当你想要用switch_to.window()切入某个不存在的window时抛出 |
| NoSuchElementException | 元素不存在,一般由find_element与find_elements抛出 |
| NoSuchAttributeException | 一般你获取不存在的元素属性时抛出,要注意有些属性在不同浏览器里是有不同的属性名的 |
| StaleElementReferenceException | 指定的元素过时了,不在现在的DOM树里了,可能是被删除了或者是页面或iframe刷新了 |
| UnexpectedAlertPresentException | 出现了意料之外的alert,阻碍了指令的执行时抛出 |
| NoAlertPresentException | 你想要获取alert,但实际没有alert出现时抛出 |
| InvalidElementStateException | 下面两个异常的父类,当元素状态不能进行想要的操作时抛出 |
| ElementNotVisibleException | 元素存在,但是不可见,不可以与之交互 |
| ElementNotSelectableException | 当你想要选择一个不可被选择的元素时抛出 |
| InvalidSelectorException | 一般当你xpath语法错误的时候抛出这个错 |
| InvalidCookieDomainException | 当你想要在非当前url的域里添加cookie时抛出 |
| UnableToSetCookieException | 当driver无法添加一个cookie时抛出 |
| TimeoutException | 当一个指令在足够的时间内没有完成时抛出 |
| MoveTargetOutOfBoundsException | actions的move操作时抛出,将目标移动出了window之外 |
| UnexpectedTagNameException | 获取到的元素标签不符合要求时抛出,比如实例化Select,你传入了非select标签的元素时 |
| ImeNotAvailableException | 输入法不支持的时候抛出,这里两个异常不常见,ime引擎据说是仅用于linux下对中文/日文支持的时候 |
| ImeActivationFailedException | 激活输入法失败时抛出 |
| ErrorInResponseException | 不常见,server端出错时可能会抛 |
| RemoteDriverServerException | 不常见,好像是在某些情况下驱动启动浏览器失败的时候会报这个错 |
Xpath&Css定位方法速查表
| 描述 | Xpath | Css |
|---|---|---|
| 直接子元素 | //div/a | div > a |
| 子元素或后代元素 | //div//a | div a |
| 以id定位 | //div[@id='idValue']//a | div#idValue a |
| 以class定位 | //div[@class='classValue']//a | div.classValue a |
| 同级弟弟元素 | //ul/li[@class='first']/following- | ul>li.first + li |
| 属性 | //form/input[@name='username'] | form input[name='username'] |
| 多个属性 | //input[@name='continue' and | input[name='continue'][type='button |
| 第4个子元素 | //ul[@id='list']/li[4] | ul#list li:nth-child(4) |
| 第1个子元素 | //ul[@id='list']/li[1] | ul#list li:first-child |
| 最后1个子元素 | //ul[@id='list']/li[last()] | ul#list li:last-child |
| 属性包含某字段 | //div[contains(@title,'Title')] | div[title*="Title"] |
| 属性以某字段开头 | //input[starts-with(@name,'user')] | input[name^="user"] |
| 属性以某字段结尾 | //input[ends-with(@name,'name')] | input[name$="name"] |
| text中包含某字段 | //div[contains(text(), 'text')] | 无法定位 |
| 元素有某属性 | //div[@title] | div[title] |
| 父节点 | //div/.. | 无法定位 |
| 同级哥哥节点 | //li/preceding-sibling::div[1] | 无法定位 |
部分函数详解
WebDriverWait()
webdriver中的等待——主要讲解WebDriverWait()_腰椎间盘没你突出的博客-CSDN博客_webdriverwait
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver: 传入WebDriver实例,即我们上例中的driver timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间) poll_frequency: 调用until或until_not中的方法的间隔时间,默认是0.5秒 ignored_exceptions: 忽略的异常,如果在调用until或until_not的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException。
WebDriverWait() 一般由until()或until_not()方法配合使用,下面是until()和until_not()方法的说明
Until(method,message=’’): 调用该方法提供的驱动程序作为一个参数,直到返回值为True。 Until_not(method,message=‘’):调用该方法提供的驱动程序作为一个参数,值得注意的是 与until相反,until是当某元素出现或什么条件成立则继续执行, until_not是当某元素消失或什么条件不成立则继续执行
method: 在等待期间,每隔一段时间(__init__中的 poll_frequency )调用这个传入的方法,直到返回值不是False message: 如果超时,抛出TimeoutException,将message传入异常
看了以上内容基本上很清楚了,调用方法如下:
WebDriverWait(driver, 超时时长, 调用频率, 忽略异常).until(可执行方法, 超时时返回的信息)
这里需要特别注意的是until或until_not中的可执行方法method参数,很多人传入了WebElement对象,如下:
WebDriverWait(driver, 10).until(driver.find_element_by_id('kw')) # 错误
这是错误的用法,这里的参数一定要是可以调用的,即这个对象一定有 call() 方法,否则会抛出异常:
TypeError: 'xxx' object is not callable
你也可以用selenium提供的 expected_conditions 模块中的各种条件,也可以用WebElement的 is_displayed() 、is_enabled()、is_selected() 方法,或者用自己封装的方法都可以。 from selenium.webdriver.support import expected_conditions as EC文章来源:https://www.toymoban.com/news/detail-788677.html
locator = (By.ID,'kw') WebDriverWait(driver,10).until(EC.title_is(u"百度一下,你就知道"))'''判断title,返回布尔值''' WebDriverWait(driver,10).until(EC.title_contains(u"百度一下"))'''判断title,返回布尔值''' WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,'kw'))) '''判断某个元素是否被加到了dom树里,并不代表该元素一定可见,如果定位到就返回WebElement''' WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.ID,'su'))) '''判断某个元素是否被添加到了dom里并且可见,可见代表元素可显示且宽和高都大于0''' WebDriverWait(driver,10).until(EC.visibility_of(driver.find_element(by=By.ID,value='kw'))) '''判断元素是否可见,如果可见就返回这个元素''' WebDriverWait(driver,10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'.mnav'))) '''判断是否至少有1个元素存在于dom树中,如果定位到就返回列表''' WebDriverWait(driver,10).until(EC.visibility_of_any_elements_located((By.CSS_SELECTOR,'.mnav'))) '''判断是否至少有一个元素在页面中可见,如果定位到就返回列表''' WebDriverWait(driver,10).until(EC.text_to_be_present_in_element((By.XPATH,"//*[@id='u1']/a[8]"),u'设置')) '''判断指定的元素中是否包含了预期的字符串,返回布尔值''' WebDriverWait(driver,10).until(EC.text_to_be_present_in_element_value((By.CSS_SELECTOR,'#su'),u'百度一下')) '''判断指定元素的属性值中是否包含了预期的字符串,返回布尔值''' WebDriverWait(driver,10).until(EC.frame_to_be_available_and_switch_to_it(locator)) '''判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False''' #注意这里并没有一个frame可以切换进去 WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.CSS_SELECTOR,'#swfEveryCookieWrap'))) '''判断某个元素在是否存在于dom或不可见,如果可见返回False,不可见返回这个元素''' #注意#swfEveryCookieWrap在此页面中是一个隐藏的元素 WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='u1']/a[8]"))).click() '''判断某个元素中是否可见并且是enable的,代表可点击''' #WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='wrapper']/div[6]/a[1]"))).click() #WebDriverWait(driver,10).until(EC.staleness_of(driver.find_element(By.ID,'su'))) '''等待某个元素从dom树中移除''' #这里没有找到合适的例子 WebDriverWait(driver,10).until(EC.element_to_be_selected(driver.find_element(By.XPATH,"//*[@id='nr']/option[1]"))) '''判断某个元素是否被选中了,一般用在下拉列表''' WebDriverWait(driver,10).until(EC.element_selection_state_to_be(driver.find_element(By.XPATH,"//*[@id='nr']/option[1]"),True)) '''判断某个元素的选中状态是否符合预期''' WebDriverWait(driver,10).until(EC.element_located_selection_state_to_be((By.XPATH,"//*[@id='nr']/option[1]"),True)) '''判断某个元素的选中状态是否符合预期''' instance = WebDriverWait(driver,10).until(EC.alert_is_present()) '''判断页面上是否存在alert,如果有就切换到alert并返回alert的内容''' instance.accept()
参考链接
https://www.jianshu.com/p/1531e12f8852 重点参考链接 https://www.jianshu.com/p/6c82c965c014 Selenium教程 selenium之 chromedriver与chrome版本映射表(更新至v2.46)_huilan_same的博客-CSDN博客_chromedriver版本 webdriver浏览器版本驱动对应以及下载 - peachlf - 博客园 webdriver中的等待——主要讲解WebDriverWait()_腰椎间盘没你突出的博客-CSDN博客_webdriverwait Selenium2 Python 自动化测试实战学习笔记(二)_WEL测试的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-788677.html
到了这里,关于Python Selenium/WebDriver 操作手册新版的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!