项目场景:
为支撑开源LLM大模型的私有化部署,需要单机多个不同型号GPU的混合使用,度娘、GPT4和机器售后都不知道如何解决,自己动手解决,mark一下。
问题描述
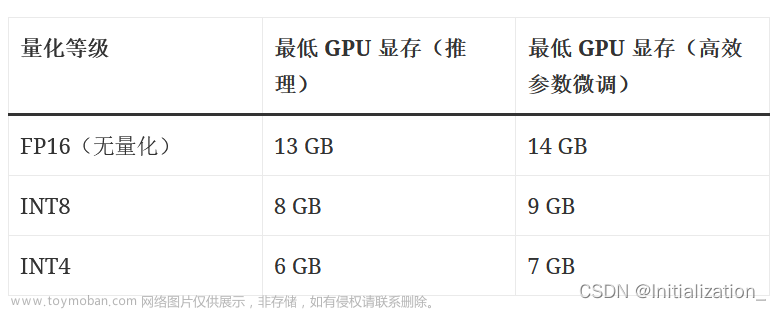
有2台深度学习的工作站,分别有2张3090和2张4090,Qwen-14B-Chat轻松跑起,知识库检索等应用效果还可以,想提升到Qwen-72B-int4(官方要求最低48G显存),于是把4张卡集中到同一台机器(多级多卡也是可以的,但不是每个框架都支持分布式GPU),过程中遇到一些坑,度娘无混卡的案例,gpt4无帮助,2台工作站和4张gpu都是联想供货的,问售后技术的,说没有试过,不知道怎么弄😶,最终还是自己动手解决问题。
fastgpt的同学们说有需求,看到网上还是无案例,就分享一下吧,毕竟有好多年无写技术blog了。
解决方案:
首先是单卡和同型号多卡的安装步骤,网上资源很多,这里简单总结一下:
1、显卡驱动
2、粗大安装(cuda)
3、cudnn安装
4、多GPU驱动安装
5、验证
关键点:2张3090和2张4090的混合使用,关键就是第1步的显卡驱动安装,根据你多张显卡型号,到https://www.nvidia.cn/Download/index.aspx?lang=cn找一个4卡都支持的驱动版本,如下图:

理论上同一个驱动支持的各种显卡,比如4090和2060混插都可以,有这些卡的同学可以尝试一下。
ps:插显卡后注意看看显卡风扇的转速,我试过插4卡后出现1张显卡风扇转速异常导致的不能开机的情况。
1、显卡驱动
sudo vim /etc/modprobe.d/blacklist.conf
blacklist nouveau
options nouveau modeset=0
sudo update-initramfs -u
sudo apt-get remove --purge nvidia*
##原来2卡的时候安装了驱动,如果看不到4张卡或者驱动不支持4张卡的型号,需要删除一下原来的驱动
sudo telinit 3
sudo chmod 777 NVIDIA-Linux-x86_64-535.146.02.run
##给你下载的驱动赋予可执行权限,才可以安装,这里
sudo ./NVIDIA-Linux-x86_64-535.146.02.run -no-x-check -no-nouveau-check -no-opengl-files
sudo service gdm3 start
sudo telinit 5
nvidia-smi 看到4张卡
这里要确认一下,uncorr. ECC 都要是 off或者N/A, 即是纠错关闭的状态,游戏卡为了帧数性能都是关闭该选项的,特斯拉卡应该是开启,貌似4090才有这个纠错的开关,开启了游戏和训练推理,会出现闪退情况。
!!!不要忘了这个哦
vim ~/.bashrc
export CUDA_VISIBLE_DEVICES=0,1,2,3
source ~/.bashrc
##修改环境变量
2、cuda安装
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.7.1/local_installers/cuda-repo-ubuntu2004-11-7-local_11.7.1-515.65.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-7-local_11.7.1-515.65.01-1_amd64.deb
sudo cp /var/cuda-repo-ubuntu2004-11-7-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
vim ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.7/lib64
export PATH=$PATH:/usr/local/cuda-11.7/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.7
source ~/.bashrc
##修改环境变量
3、cudnn安装
(https://developer.nvidia.com/rdp/cudnn-archive#a-collapse881-118) #下载 解压
cd /usr/local/cuda-11.7
sudo chmod 777 include
sudo cp cudnn--archive/include/cudnn.h /usr/local/cuda-11.7/include
sudo cp cudnn--archive/lib/libcudnn /usr/local/cuda-11.7/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda-11.7/lib64/libcudnn*
sudo cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
4、多GPU驱动安装
wget https://developer.nvidia.com/compute/machine-learning/nccl/secure/2.14.3/ubuntu2004/x86_64/nccl-local-repo-ubuntu2004-2.14.3-cuda11.7_1.0-1_amd64.deb
sudo cp /var/nccl-local-repo-ubuntu2004-2.14.3-cuda11.7/nccl-local-44000BE4-keyring.gpg /usr/share/keyrings/
sudo dpkg -i nccl-local-repo-ubuntu2004-2.14.3-cuda11.7_1.0-1_amd64.deb
sudo apt install libnccl2=2.14.3-1+cuda11.7 libnccl-dev=2.14.3-1+cuda11.7文章来源:https://www.toymoban.com/news/detail-789020.html
5、验证
我机器上有paddle和pytorch环境,任意一个都有验证的代码,已paddle为例:
import paddle
paddle.utils.run_check()
验证通过了,可以炼丹啦。
最近在做基于开源LLM的RAG应用,有兴趣的同学们沟通分享哇。文章来源地址https://www.toymoban.com/news/detail-789020.html
到了这里,关于支撑开源LLM大模型的私有化部署,需要单机多个不同型号GPU混合使用的同学看过来的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!