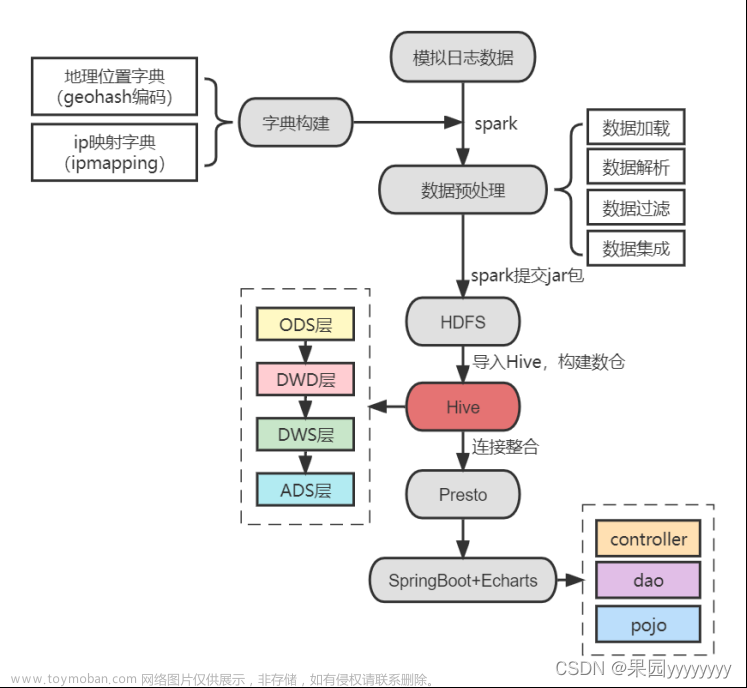
第1关:2018年点击量最高的10个网站域名文章来源:https://www.toymoban.com/news/detail-789067.html
---------- 禁止修改 ----------
drop database if exists mydb cascade;
---------- 禁止修改 ----------
---------- begin ----------
---创建mydb数据库
create database mydb;
---使用mydb数据库
use mydb;
---创建表db_search
create table db_search(
id string comment '用户编号',
key string comment '搜索关键词',
ranking string comment '该URL在返回结果中的排名',
or_der string comment '点击顺序',
url string comment '域名',
time string comment '时间'
)row format delimited fields terminated by ' ';
---导入数据:/root/data.txt
load data local inpath '/root/data.txt' into table db_search;
--查询2018年点击量最多的10个网站域名
select url,count(*) cnt from db_search where year(time)='2018'
group by url order by cnt desc limit 10;
---------- end ----------第2关:同一种搜索词,哪个网站域名被用户访问最多文章来源地址https://www.toymoban.com/news/detail-789067.html
---------- 禁止修改 ----------
drop database if exi到了这里,关于educoder中Hive综合应用案例 — 用户搜索日志分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!