搜索引擎的坑
ES 搜索引擎系列文章汇总:
一、别只会搜日志了,求你懂点原理吧
二、ES 终于可以搜到”悟空哥“了!
三、1W字|40 图|硬核 ES 实战
本文主要内容如下:

搜索引擎现在是用得越来越多了,比如我们日志系统中用到的 ELK 就用到了搜索引擎 Elasticsearch(简称 ES)。
那对于搜索这种技术来说,最看重的是搜索的结果的准确性和搜索的响应时间。ES 的准确性可以通过 倒排索引算法来保证,那响应时间就需要磁盘或缓存来支持了,那么磁盘和缓存会带来哪些坑呢? ( 其实不论是分布式的,还是单机模式下的搜索引擎都会遇到这个问题。 )
一、ES 慢查询之坑
Elasticsearch 是现如今用的最广泛的搜索引擎。它是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
1.1 工作原理:
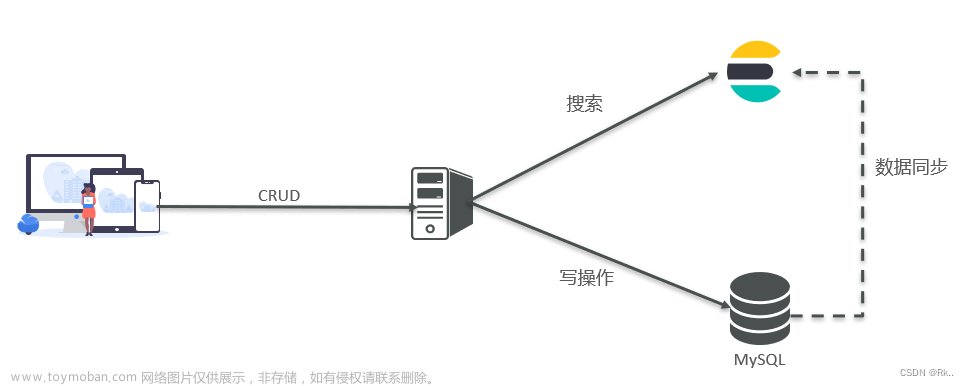
ES 的工作原理:往 ES 里写数据时,实际是写到磁盘文件,查询时,操作系统会将磁盘文件里的数据自动缓存 filesystem cache 里面。如果给 filesystem cache 更多的内存,尽量让内存可以容纳所有的 idx segment file 索引数据文件,则搜索的时候走内存,性能较好。

坑:首先如果访问磁盘那一定很慢,而走缓存会快很多。但如果很多没用的字段数据都丢到缓存里面,则会浪费缓存的空间,所以很多数据还是存在磁盘里面的,那么大部分查询走的数据库,则会带来性能问题。
1.2 案例
ES 节点 3 台机器,每台机器 32 G 内存,总内存 96 G,给 ES JVM 堆内存是 16 G,那么剩下来给 cache 的是 16 G,总共 ES 集群的的 cache 占用内存 48 G ,如果所有的数据占据磁盘空间 600 G,那么每台机器的数据量是 200 G,而查询时,有 150 G 左右的的数据是走磁盘查询的,那么走 cache 的概率是 48 G/ 600 G = 8%,也就是说大量查询是走磁盘的。
1.3 避坑指南:
1.3.1 存储关键信息

-
将数据中索引字段存到 cache,比如 一行数据有 name、gender、age、city、job 字段,而检索这条数据只需要 name 和 gender 就可以查询出数据,那么 cache 就只需要存 id、name 和 gender 字段。别把所有字段都丢到 cache 里面,纯属浪费空间,资源是有限的。
-
那剩下的字段怎么检索出来?可以把其他字段存到 mysql/hbase 里面。
-
hbase 特点:适用于海量数据的在线存储。缺点是不能进行复杂的搜索。根据 name 和 gender 字段从 ES 中拿到 100 条数据 ( 包含 doc id ) ,然后根据 doc id 再去 hbase 中查询每个 doc id 对应的完整数据,将结果组装后返回给前端 ( 需要考虑分页的情况 ) 。
1.3.2 数据预热
- 将访问量高的数据或者即将访问量高的数据放到 filesystem cache 里面。
- 每隔一段时间就从数据库访问下数据,然后同步到 filesystem cache 里面。
1.3.3 冷热分离
- 不常访问的数据和经常访问的数据进行隔离。比如 3 台机器存放冷数据的索引,另外 3 台存放热数据的索引。
1.3.4 避免使用关联查询
- ES 中的关联查询是比较慢的,性能不佳,尽量避免使用。
二、ES 架构之坑
通常情况下,我们会使用 ES 的集群模式,在集群规模不大的情况下,性能还算可以,但如果集群规模变得很大,则会遇到集群瓶颈,也就是说集群扩大,性能提升甚微,甚至不增反降。
ES 的集群也是采用中心化的分布式架构,整个集群只有一个是 Master 节点。而它的职责非常重要:负责整个集群的元数据管理,元数据包含全局的配置信息、索引信息、节点信息,如果元数据发生改变,则需要 master 节点将变更信息发布到集群的其他节点。
另外因为 master 节点的任务处理是单线程的,所以每次处理任务时,需要等待全部节点接收到变更信息,并处理完变更的任务后,才算完成了变更任务。

那么这样的架构会带来什么问题:
-
响应时间问题。如果元数据发生了改变,但某节点
假死,比如 JVM 的内存爆了,但是进程还活着,那么响应 master 节点的时间会非常长,今而影响单个同步信息任务的完成时间。 - 任务恢复问题。有大量恢复任务的时候,任务需要排队,恢复时间变长。
- 任务回调问题。任务执行完成后,需要回调大量 listener 处理元数据变更。如果分片的数据很大,则处理时间会到 10 秒级,严重影响了集群的恢复能力。
解决方案:采用 ES 的 tribe node 特性实现 ES 多集群。文中后面会介绍下 tribe node 的原理。
三、业务场景的坑
ES 的被广泛应用到多个场景,比如查询日志、查询商品资料、数据聚合等。而这些场景的需求又有非常大的差异,这也是一个坑。
- **场景一:前端首页搜索功能。**比如搜索商品,数据实时写入的频率不高,但是读的频率很高。

- **场景二:日志检索的功能。**日志系统中,我们一般都是 ELK 这种架构模式,对实时写入要求很高,而查询的次数其实不多,毕竟查询日志多工作还是开发和运维人员来做。

- 场景三:监控、分析的功能。ES 也会被运用到需要监控数据和分析数据的场景中,而这种场景又是对 ES 的内存要求比较高,因为这些分析功能是在内存中完成的,若内存出现太大的压力,则会造成系统的垃圾回收,可能出现短暂的服务抖动。
解决方案:按业务场景划分 ES 集群,同样采用 ES tribe node 功能。
四、ES Tribe Node 方案
ES tribe node 功能原理图如下所示:

- 有两个 ES 集群,每个集群都有多个 ES 节点。
- Logstash 负责日志搜集。
- Kibana 负责客户端查询,将查询命令传送到 ES Tribe Node。
- ES Tribe Node 还承担了集群管理的职责。
后续我们再来聊聊 ES Tribe Node 的底层原理和用法~
参考资料:
https://www.infoq.cn/article/SbfS6uOcF_gW6FEpQlLK
https://www.elastic.co/guide/en/elasticsearch/reference/2.0/modules-tribe.html文章来源:https://www.toymoban.com/news/detail-789571.html
advance-java文章来源地址https://www.toymoban.com/news/detail-789571.html
到了这里,关于搜索引擎 Elasticsearch 的三大坑的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!