GPT实战系列-简单聊聊LangChain搭建本地知识库准备

LangChain 是一个开发由语言模型驱动的应用程序的框架,除了和应用程序通过 API 调用, 还会:
-
数据感知 : 将语言模型连接到其他数据源
-
具有代理性质 : 允许语言模型与其环境交互
LLM大模型相关文章:
GPT实战系列-简单聊聊LangChain
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
GPT实战系列-大话LLM大模型训练
GPT实战系列-探究GPT等大模型的文本生成
GPT实战系列-Baichuan2等大模型的计算精度与量化
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
LangChain是什么?
构建本地的行业、专家知识库,就需要LangChain 支持常见角色和用途。
-
个人助理(personal assistants) : 主要的 LangChain 使用用例。个人助理需要采取行动、记住交互并具有您的有关数据的知识。
-
问答(question answering) : 第二个重大的 LangChain 使用用例。仅利用一些文档中的信息来构建答案,回答特定文档中的问题。
除LangChain外,还需要什么?
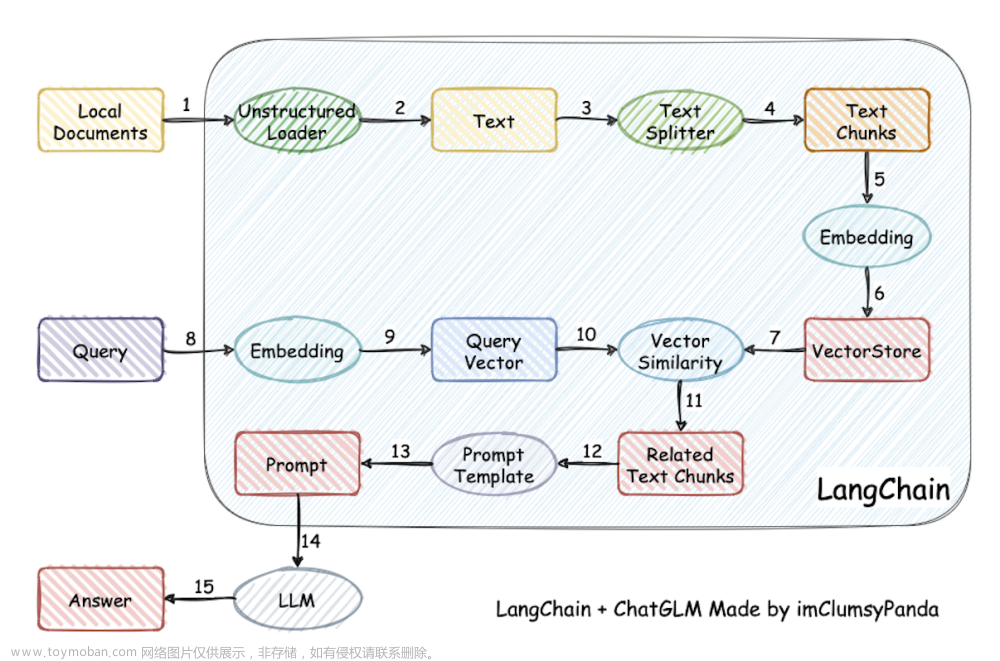
首先需要把文本转换为文本向量,即自然语言处理常常要用的Embedding技术,Text2Vector。
常见的Embedding接口有 OpenAI,Sentence Transformers,BGE, Huggingface,ModelScope,TensorFlowHub
例如,OpenAI提供接口,需要翻墙:
from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings()
SentenceTransformer的接口:
from langchain.embeddings import HuggingFaceEmbeddings, SentenceTransformerEmbeddings embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2") # Equivalent to SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
Huggingface接口,直接下载需要翻墙。
没有梯子怎么办?如有需要可以单独写篇。
from langchain.embeddings import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings()
ModelScope,非常适合国内,不用翻墙。
from langchain.embeddings import ModelScopeEmbeddings model_id = "damo/nlp_corom_sentence-embedding_english-base" embeddings = ModelScopeEmbeddings(model_id=model_id)
Tensorflow hub,需要安装tensorflow组件。现在用pytorch,就很少使用tensorflow。
from langchain.embeddings import TensorflowHubEmbeddings embeddings = TensorflowHubEmbeddings()
One more thing
文本向量直接比较就不足以推广,还需要加上向量数据库。
向量数据库也有很多,选几个熟悉的,比如FAISS,Chroma,Milvus,Redis,Deep Lake等等。
例如 FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.document_loaders import TextLoader
loader = TextLoader("../../../state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
后面基于LangChain做一些好玩的本地专家库测试吧。
觉得有用 收藏 收藏 收藏
点个赞 点个赞 点个赞
End
GPT专栏文章:
GPT实战系列-简单聊聊LangChain
GPT实战系列-ChatGLM3本地部署CUDA11+1080Ti+显卡24G实战方案
GPT实战系列-LangChain + ChatGLM3构建天气查询助手
大模型查询工具助手之股票免费查询接口
GPT实战系列-简单聊聊LangChain
GPT实战系列-大模型为我所用之借用ChatGLM3构建查询助手
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(二)
GPT实战系列-P-Tuning本地化训练ChatGLM2等LLM模型,到底做了什么?(一)
GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案
GPT实战系列-Baichuan2本地化部署实战方案
GPT实战系列-Baichuan2等大模型的计算精度与量化
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章来源:https://www.toymoban.com/news/detail-789672.html
GPT实战系列-探究GPT等大模型的文本生成-CSDN博客文章来源地址https://www.toymoban.com/news/detail-789672.html
到了这里,关于GPT实战系列-简单聊聊LangChain搭建本地知识库准备的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!