python正则模块介绍
标准库模块 re
模块方法
# 将正则表达式样式编译成一个正则对象。一般用于多次使用正则对象的场景
re.compile(pattern)
# 扫描string字符串并查找符合patten样式的第一个位置,返回对应的 Match 结果,否则返回 None
re.search(patten, string)
# 如果 string 开头的零个或多个字符与正则表达式 pattern 匹配,返回对应的 Match 结果,否则返回 None
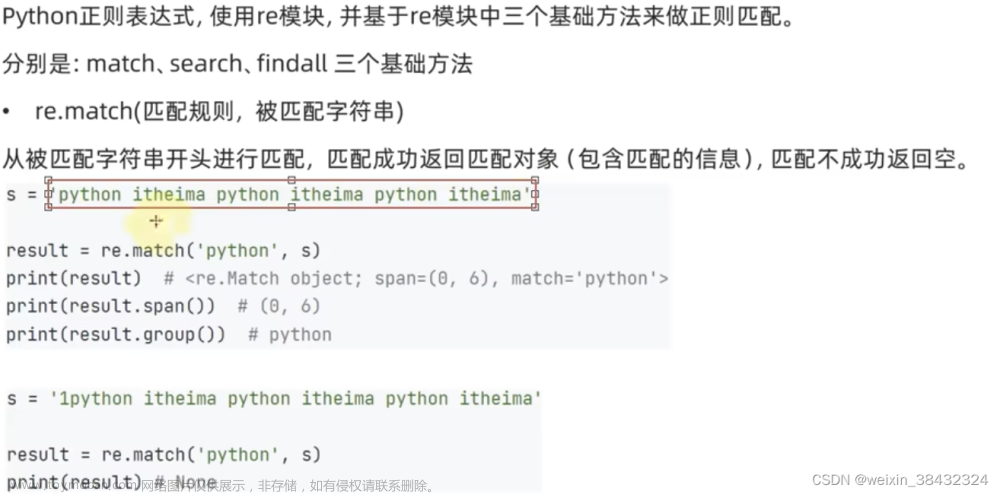
re.match(patten, string)
# 整个string余表达式patten样式匹配,返回对应的 Match 结果,否则返回 None
re.fullmatch(patten, string)
match结果指的是返回的Match对象,Match对象的group方法可以取出匹配到的结果
正则表达式语法
^: 指开头
$:指结尾
+:表示匹配一次或多次
?:表示匹配0或1次
*:表示匹配0或任意次
{n}:表示匹配指定次数
{m,}:至少匹配m次
{m, n}:匹配m至n次
.:匹配除‘\n’以外的任意单个字符
\d: 数字
\w:包括下划线的任何单词字符,等价于[a-zA-Z0-9_]
\W:非单词字符
\s:空白字符,包括空格、制表符、换页符等
\b:单词边界,例如,“
er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”\B:非单词边界
a|b:匹配a或b
(patten):匹配并获取结果
(?:patten):匹配但不获取结果
(?P<name>patten):匹配并获取结果,并命名为name,便于match.group进行获取查询
示例
compile + search
>>> import re
>>> pattern = "\d+"
>>> obj = re.compile(pattern)
>>> res = obj.search("a12b13c14")
>>> res
<re.Match object; span=(1, 3), match='12'>
match
>>> re.match("\w\d+", "a12b13c14")
<re.Match object; span=(0, 3), match='a12'>>>> re.match("\d+", "a12b13c14")
None
>>>
group
>>> res = re.match("(\w+):(\d+)", "bob:3,allen:10")
>>> res.group
<built-in method group of re.Match object at 0x1071b6780>>>> res.group(0)
'bob:3'
>>> res.group(1)
'bob'
>>> res.group(2)
'3'
常见的正则表达式写法
| 正则表达式 | 场景 |
| \d{4}-\d{2}-\d{2} | 形如 YYYY-MM-DD样式的日期格式 |
| ^[A-Z][a-z ]+ | 以大写字母开头,且单词其他部分为小写 |
| [a-zA-Z] | 匹配英文字母 |
| ^w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$ |
|
| [\u2E80-\u9FFF] | 汉字 |
参考文档
正则表达式手册文章来源:https://www.toymoban.com/news/detail-789831.html
re --- 正则表达式操作 — Python 3.12.1 文档文章来源地址https://www.toymoban.com/news/detail-789831.html
到了这里,关于2.1 python文本处理-正则表达式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!