云原生专栏大纲
为什么使用TIDB
从后端视角、运维视角和基础架构视角来看,使用 TiDB 作为数据库系统可以获得分布式架构、高可用性、强一致性、事务支持、水平扩展、高性能、简化运维、灵活的扩展和配置、集成的监控和告警等优势。这些优势使得 TiDB 成为处理大规模数据和高并发请求的理想选择,并能够满足复杂的业务需求和运维要求。
后端视角
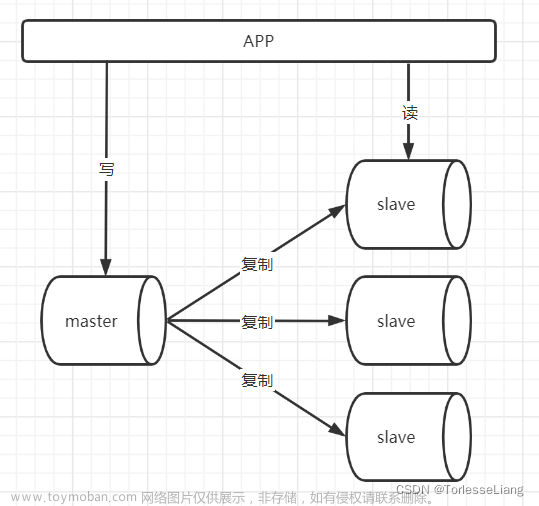
- 分布式架构和高可用性:TiDB 是一个分布式数据库系统,采用分布式架构和数据分片技术,可以将数据分布在多个节点上。这种架构使得 TiDB 具有高可用性和容错性,即使某个节点发生故障,系统仍然可以继续提供服务,确保业务的连续性。
- 强一致性和事务支持:TiDB 提供强一致性和事务支持,符合 ACID 特性。它使用分布式一致性协议来保证数据的一致性,在多节点之间实现事务的隔离和提交。这使得 TiDB 可以处理复杂的业务逻辑和数据一致性要求。
-
水平扩展和高性能:TiDB 具有水平扩展和负载均衡的能力。通过添加更多的节点,可以实现数据的水平分片和负载均衡,提供更高的吞吐量和更低的延迟。这使得 TiDB 能够处理大规模数据和高并发请求,满足高性能的需求。
运维视角
- 简化运维工作:TiDB 提供了简化运维的功能,减少了运维人员的工作量。它具有自动化的故障检测和恢复机制,可以自动处理节点故障和数据复制等问题。此外,TiDB 还提供了集中式的管理界面和命令行工具,使得运维人员可以方便地监控和管理整个数据库集群。
- 灵活的扩展和配置:TiDB 具有灵活的扩展和配置选项。它支持在线扩容和缩容,可以根据负载情况动态调整集群的规模。此外,TiDB 还提供了丰富的配置选项,使得运维人员可以根据具体需求进行优化和调整,以获得最佳的性能和资源利用率。
-
集成的监控和告警:TiDB 集成了监控和告警功能,可以实时监控数据库集群的状态和性能指标,并根据预设的规则和阈值触发告警通知。这使得运维人员可以及时发现和解决潜在的问题,保证系统的稳定性和可靠性。
基础架构视角
- 分布式数据存储和计算:TiDB 的分布式架构使得数据可以分布在多个节点上,实现了分布式的数据存储和计算。这种架构可以提供更好的数据并行性和负载均衡,支持处理大规模数据和高并发请求。
- 弹性扩展和容错性:TiDB 具有弹性扩展和容错性的特点。通过添加更多的节点,可以实现系统的弹性扩展,以适应不断增长的数据和负载。同时,TiDB 的分布式架构还具有容错性,即使某个节点发生故障,系统仍然可以继续提供服务。
- 云原生和容器化支持:TiDB 支持云原生和容器化部署。它可以与容器编排平台(如 Kubernetes)集成,实现弹性伸缩和自动化管理。这使得 TiDB 可以更好地适应云环境和容器化部署的需求。
TiDB Operator 简介
TiDB Operator 是一个用于在 Kubernetes 上部署和管理 TiDB 集群的工具。TiDB 是一个开源的分布式关系型数据库,具有高可用性、可扩展性和水平扩展的特性,适用于处理大规模的数据和高并发的工作负载。
TiDB Operator 的主要功能是简化 TiDB 集群的部署、管理和运维。它基于 Kubernetes 的自定义资源定义(Custom Resource Definition,CRD)和控制器模式,提供了一组自定义资源和控制器,用于描述和操作 TiDB 集群的各个组件和配置。
以下是 TiDB Operator 的一些主要特点和功能:
- 自动化部署和扩展:TiDB Operator 可以自动化地部署和扩展 TiDB 集群。您可以通过定义 TiDBCluster 自定义资源来描述集群的拓扑结构、副本数量、存储配置等参数,TiDB Operator 将根据这些参数自动创建和管理相应的 Kubernetes 资源。
- 可靠的运维功能:TiDB Operator 提供了一些可靠的运维功能,包括自动备份和恢复、滚动升级、自动故障转移等。它可以监控集群的状态和健康状况,并根据需要执行相应的操作,以确保集群的高可用性和稳定性。
- 灵活的配置和扩展:TiDB Operator 允许您通过自定义资源和配置文件来灵活地配置和扩展 TiDB 集群。您可以定义 TiDBCluster、TiDBMonitor、BackupSchedule 等自定义资源来指定集群的各种配置和行为,以满足特定的需求。
- 监控和告警:TiDB Operator 集成了 Prometheus 和 Grafana,可以提供集群的实时监控指标和可视化。您可以通过自定义资源 TiDBMonitor 来配置监控规则和告警策略,以及在集群出现问题时发送告警通知。
TiDB Operator 简化了在 Kubernetes 上部署和管理 TiDB 集群的过程,提供了自动化的部署、可靠的运维功能和灵活的配置选项。它使得使用 TiDB 在容器化环境中更加便捷和高效。您可以访问TiDB Operator 简介 GitHub - pingcap/tidb-operator
通过之前文章《8.云原生存储之Ceph集群》介绍ceph部署也使用了Operator,简单总结Operator就是一个部署控制器,主要用于简化部署过程。
软件版本要求
| 软件名称 | 版本 |
|---|---|
| Docker | Docker CE 18.09.6 |
| Kubernetes | v1.12.5+ |
| CentOS | CentOS 7.6,内核要求为 3.10.0-957 或之后版本 |
| Helm | v3.0.0+ |
上篇中已经讲述了centos升级操作
Kubernetes Master 节点的配置取决于 Kubernetes 集群中 Node 节点个数,节点数越多,需要的资源也就越多。节点数可根据需要做微调。
| Kubernetes 集群 Node 节点个数 | Kubernetes Master 节点配置 |
|---|---|
| 1-5 | 1vCPUs 4GB Memory |
| 6-10 | 2vCPUs 8GB Memory |
| 11-100 | 4vCPUs 16GB Memory |
| 101-250 | 8vCPUs 32GB Memory |
| 251-500 | 16vCPUs 64GB Memory |
| 501-5000 | 32vCPUs 128GB Memory |
部署tidb
- 添加tidb应用仓库

- 查看应用仓库提供的应用

- 在 Kubernetes 上快速上手 TiDB
部署前先在kubesphere中创建如下项目(对应k8s中命名空间)
# 部署crd
kubectl create -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.5.1/manifests/crd.yaml
# 部署tidb-operator,可在ks应用仓库部署
helm install --namespace tidb-admin tidb-operator pingcap/tidb-operator --version v1.5.1
# 查看部署情况
kubectl get pods --namespace tidb -l app.kubernetes.io/instance=tidb-operator
# 部署 TiDB 集群。可以在应用仓库部署,注意修改storageClassName
kubectl -n tidb apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.5.1/examples/basic-cn/tidb-cluster.yaml
# 部署独立的 TiDB Dashboard
kubectl -n tidb apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.5.1/examples/basic-cn/tidb-dashboard.yaml
# 部署 TiDB 集群监控
kubectl -n tidb apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.5.1/examples/basic-cn/tidb-monitor.yaml
- kubesphere中查看部署情况


- 暴露tidb相关服务

部署后会创建basic-tidb(svc),通nodeport暴露服务发现会重置导致不能访问,此处小编自己创建tidb-svc暴露服务进行测试如下:
- grafana监控面板集群监控,账号密码admin



- dashboard

TIDB工具
helm仓库 https://charts.pingcap.org/包括应用如下:文章来源:https://www.toymoban.com/news/detail-790151.html
| 应用名称 | 描述 |
|---|---|
| tidb-operator | 用于在 Kubernetes 上部署和管理 TiDB 集群的操作符。它提供了自动化的部署、扩展和运维功能,简化了 TiDB 集群的管理流程。 |
| tidb-cluster | 用于定义和配置 TiDB 集群的 Helm Chart。通过 tidb-cluster,您可以指定 TiDB、TiKV 和 PD 组件的数量、资源配置、存储设置等参数,以创建一个完整的 TiDB 集群。 |
| tidb-backup | 提供了对 TiDB 集群进行备份和恢复的功能。tidb-backup 可以根据预定的计划自动备份 TiDB 集群,并支持从备份中恢复数据。 |
| tidb-drainer | 用于从 MySQL 或者 TiDB 集群中抓取 Binlog,并将其转发到其他目标(如 Kafka 或者 TiDB 集群)。tidb-drainer 可以用于实时数据分析、数据同步等场景。 |
| tidb-lightning | 提供了快速导入大量数据到 TiDB 集群的功能。tidb-lightning 可以将数据从各种数据源(如 MySQL、CSV 文件等)导入到 TiDB 集群中,以加快数据导入速度。 |
| tikv-importer | 用于将数据从其他数据库引擎(如 RocksDB)迁移到 TiKV。tikv-importer 提供了高效的数据迁移工具,可以将数据转换为 TiKV 的格式并导入到 TiDB 集群中。 |
| tikv-operator | 用于在 Kubernetes 上部署和管理 TiKV 集群的操作符。tikv-operator 可以自动创建和管理 TiKV 实例,提供了高可用性和可扩展性的分布式存储解决方案。 |
| diag | 提供了 TiDB 集群的诊断和故障排查工具。diag 可以帮助您分析和解决 TiDB 集群中的性能问题、错误和故障。 |
| br-federation | 用于在分布式 TiDB 集群中进行备份和恢复的工具。br-federation 可以协调多个 TiDB 集群之间的备份和恢复操作,提供了跨集群的数据保护和恢复能力。 |
helm常用命令
| helm install | 安装一个 Helm 包 | helm install my-release stable/mysql |
|---|---|---|
| helm upgrade | 升级已安装的 Helm 包 | helm upgrade my-release stable/mysql |
| helm uninstall | 卸载一个已安装的 Helm 包 | helm uninstall my-release |
| helm list | 列出已安装的 Helm 包 | helm list |
| helm status | 显示已安装的 Helm 包的状态 | helm status my-release |
| helm rollback | 回滚到先前的 Helm 包版本 | helm rollback my-release 1 |
| helm search | 搜索可用的 Helm 包 | helm search repo mysql |
| helm repo add | 添加一个 Helm 仓库 | helm repo add stable https://charts.helm.sh/stable |
| helm repo update | 更新已添加的 Helm 仓库 | helm repo update |
| helm repo list | 列出已添加的 Helm 仓库 | helm repo list |
| helm dependency update | 更新 Helm 依赖 | helm dependency update my-chart |
| helm lint | 检查 Helm Chart 的语法和最佳实践 | helm lint my-chart |
| helm template | 生成 Helm Chart 的模板文件 | helm template my-chart |
| helm history | 显示已安装 Helm 包的历史版本 | helm history my-release |
| helm plugin install | 安装 Helm 插件 | helm plugin install https://example.com/helm-plugin.tar.gz |
| helm plugin list | 列出已安装的 Helm 插件 | helm plugin list |
| helm plugin uninstall | 卸载已安装的 Helm 插件 | helm plugin uninstall my-plugin |
| helm env | 显示 Helm 的环境变量信息 | helm env |
TIDB学习推荐资料
小编推荐学习最好还是阅读官网TiDB 产品文档,官网提供的PFD文档TiDB on Kubernetes 用户文档.pdf,tidb-github。除上述学习途径,小编推荐b站上的tidb教程,配套 资料已上传到gitee。文章来源地址https://www.toymoban.com/news/detail-790151.html
到了这里,关于11.云原生分布式数据库之TIDB的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!