一、说明
AI反馈强化学习(RLAIF)是一种监督技术,它使用“宪法”来使像ChatGPT这样的AI助手更安全。在本指南中了解您需要了解的有关 RLAIF 的所有信息。
瑞安·奥康纳
近几个月来,大型语言模型 (LLM) 因其编写代码、起草文档等能力而备受关注。人们还观察到这些能力极强的特工有时会表现出不良行为,例如产生有害和有毒的输出,甚至在某些情况下鼓励自残。
人类反馈强化学习(RLHF)作为提高 LLM 安全性的方法被部分引入,它是构建ChatGPT 的核心技术。虽然 RLHF 已被证明是一种有效的方法,但从伦理角度来看,人们对它存在合理的担忧,并且从严格的技术角度来看,它作为一种监督程序效率低下。

RLHF 使用人类反馈来训练人工智能助手
AI 反馈强化学习(RLAIF) 是Anthropic设计的一种方法,旨在克服 RLHF 的许多缺点。在这个模式中,人工智能助手整合了来自另一个人工智能模型的反馈,而不是来自人类的反馈。相反,人类通过向人工智能反馈模型提供宪法来参与其中,该宪法概述了模型做出判断的基本原则。

RLAIF 用另一个人工智能来训练一个人工智能助理,后者的反馈是由人类提供的宪法提供的
与 RLHF 相比,RLAIF具有三个基本优势。
- 首先,从性能角度来看,RLAIF 优于 RLHF ——RLAIF 模型保持了 RLHF 模型的有用性,同时在无害性方面进行了改进。
- 其次,RLAIF 的主观性要小得多,因为最终的人工智能助手的行为不仅仅依赖于一小部分人类及其特定偏好(与 RLHF 一样)。
- 最后,重要的是,RLAIF作为一种监督技术更具可扩展性。
下面,我们首先对RLHF进行简单的回顾,以了解其主要工作原理和缺点。然后,我们将继续对RLAIF 进行高级概述,以类似地了解它的工作原理并了解它如何解决 RLHF 的缺点。对更多详细信息感兴趣的读者可以阅读RLAIF 的深入研究部分,然后我们将重点介绍 RLAIF 的结果和优势。
二、RLHF 简要回顾
在创建人工智能助手时,一个明显的愿望就是让助手能够提供帮助。当我们要求助手写一个故事,或起草一封电子邮件,或提供如何建造鸟舍的说明时,我们希望它能够生成满足给定请求的适当有用且有帮助的输出。不幸的是,根据定义,纯粹有帮助的代理人也有可能有害。
如果有人要求一个有用的人工智能助手计划一次银行抢劫,那么计划银行抢劫将是助手为该用户做的有帮助的事情;然而,这对社会来说并不是一件有帮助的事情。有些人一开始可能会认为这是一个社会学问题,但乐于助人的代理人具有有害的能力是固有的,并且超出了用户的目标与社会的目标不一致的零和场景。事实上,一个有用的代理可能对用户本身有害。如果一个不知情的新手化学家询问人工智能助手如何制造氯气,那么一个乐于助人的助手会强迫并概述这样做的说明。当化学家的实验突然结束时,这种帮助似乎就没那么有用了。
相反,我们寻求一种非回避、有益且无害的模型:

人工智能助手(适用于一般用例)应该以无害的反应毫不回避地回答有害的提示
那么,我们如何才能让人工智能助手既有用又无害呢?RLHF 是法学硕士实现这一目标的一种途径,它从训练偏好模型开始。
2.1 偏好模型
强化学习(RL)是人工智能领域的一种学习范例,它使用奖励信号来训练代理。在强化学习过程中,我们让智能体采取一些行动,然后向智能体提供该行动是否良好的反馈。我们不会教模型做什么,而是让它通过学习哪些行为会产生良好的反馈来弄清楚该做什么。

人工智能助理总结国情咨文演讲并接收人类对摘要的反馈
通过强化学习训练代理通常需要大量反馈,而这种人类反馈很难收集。虽然模型的训练可以通过并行化或使用更好的硬件来扩展,但扩展此类训练所需的人类反馈量要困难得多,并且最终总是需要更多的工作时间。这些扩展困难与迄今为止推动法学硕士作为一项有用技术成熟的扩展过程形成鲜明对比。
为了解决这个问题,RLHF 使用了偏好模型,该模型旨在以可扩展和自动化的方式反映人类的偏好。我们试图用一个像人类一样行动的模型来代替人类,这样我们就无法判断反馈是来自偏好模型还是来自人类。

一个好的偏好模型会模仿人类的偏好,因此很难或不可能判断反馈是来自模型还是人类
这使我们能够用简单、可扩展且自动化的从偏好模型收集反馈的过程来取代收集人类反馈的时间和资源密集型过程。
技术说明
2.2 排名反馈训练
我们希望我们的偏好模型(PM)能够模仿人类的偏好,因此我们必须收集人类偏好的数据集来训练模型。特别是,RLHF 使用排名偏好建模,向用户显示由法学硕士生成的两个不同响应的提示,并要求用户根据偏好程度对它们进行排名。为了清楚起见,我们在本文中将该法学硕士称为“响应模型”。

人类对同一提示的两个不同响应进行排名,以生成人类偏好的数据集
一旦我们有了这个数据集,我们就可以用它来训练偏好模型。PM 为提示/响应对赋予数值或“偏好分数”,其中分数较高的一对被认为比分数较低的另一对更可取。使用我们收集的人类偏好数据集,我们训练 PM 将更高的偏好分数归因于人类偏好的响应。

一旦偏好模型经过训练,我们就可以通过在强化学习模式中提供反馈来使用它来训练法学硕士。这就是 RLHF 发生的地方,其中“人类”指的是偏好模型反映了人类的偏好——RL 阶段不直接涉及人类。

我们最初的强化学习模式中的人类已被我们的偏好模型所取代。请注意,反馈(竖起大拇指)是数字的,而不是像人类反馈那样是二进制的。
RLHF 的关键见解是,我们不是直接使用人类反馈来训练人工智能助手(通过 RL),而是使用它来训练偏好模型,该模型可以以自动化和可扩展的方式提供这种反馈。
虽然偏好模型避免了人类在强化学习训练期间直接提供反馈的费力过程,但它仍然需要首先收集人类偏好的数据集来训练 PM。这个流程可以改进吗?
三、RLAIF 的工作原理 - 高级概述
RLHF 是获得反映人类偏好的响应的好方法;然而,它还有一些问题需要改进。
首先,如上所述,收集用于训练 PM 的人类偏好数据集仍然耗时且资源密集。虽然 RLHF 比直接根据人类偏好训练 LLM 更好,但扩大用于训练偏好模型的训练数据量仍然需要相应更多的工作时间。
此外,指导人工智能助手行为的人类偏好数据集来自一个小群体,这会产生固有的偏见,因为模型将根据该特定群体的偏好进行训练。鉴于此类 RLHF 模型可能被数百万潜在用户使用,这种偏差可能会产生问题。即使一小部分人在提供反馈时被告知要遵守特定准则,也不可能让一小部分人的偏好反映全球多元化人口的偏好,这既具有挑战性,又不太可能。在之前的出版物中,数据是由不到 20 名众包人员生成的,这意味着不到 20 人在一定程度上决定了该模型如何为全球用户表现。
RLAIF 解决了这两个问题。
3.1 规模化监管
与 RLHF 相反,RLAIF 自动生成自己的排名偏好数据集,用于训练偏好模型。在 RLAIF 的情况下,数据集是由 AI反馈模型(而不是人类)生成的。给定两个提示/响应对(具有相同的提示),反馈模型会为每对生成一个偏好分数。这些分数是根据宪法确定的,该宪法概述了确定一种反应优于另一种反应的原则。

反馈模型用于收集响应更好的数据
这个人工智能生成的数据集与人类生成的 RLHF 偏好数据集相同,除了人类反馈是二元的(“更好”或“更差”),而人工智能反馈是一个数值(范围 [0, 1])。

形成一个数据集,其中每个提示都有两个潜在响应,并以关联的偏好分数作为标签
从这里开始,RLAIF 过程的其余部分与 RLHF 相同。也就是说,人工智能生成的数据用于训练偏好模型,然后将其用作法学硕士 RL 训练模式中的奖励信号。
简而言之,我们寻求使用强化学习来训练人工智能助手,其中奖励由偏好模型提供。对于 RLHF,用于训练该偏好模型的偏好由人类提供。借助 RLAIF,这些偏好由反馈模型自动生成,反馈模型根据人类提供的构成来确定偏好。整体流程总结如下图:

以宪法原则为条件的人工智能反馈取代人类反馈,是RLHF和RLAIF的根本区别。请注意,这里从人类到人工智能的变化在于收集反馈以训练另一个模型(PM)的方法,该模型在 RL 训练期间提供最终偏好。也就是说,在 RLAIF 中,“反馈模型”是一个 AI 模型,而在 RLHF 中,这个“模型”是一群人类。创新在于训练偏好模型的数据生成方法,而不是偏好模型本身。
当然,还有很多相关细节需要讨论。如果您想了解有关 RLAIF 工作原理的更多信息,可以继续阅读下一部分。否则,您可以跳到“结果和收益”部分,查看 RLAIF 与 RLHF 的比较。
四、RLAIF 的运作方式 - 深入探讨
4.1 第 1 步:生成修订版本
在上面 RLAIF 的高级概述中,我们提到“响应模型”针对同一提示生成两个不同的响应,然后将其输入反馈模型。该响应模型实际上已经在人工智能生成的提示和安全响应数据集上进行了微调,这些数据集是通过修订过程创建的。现在让我们看看这个过程是如何进行的。
首先,旨在引发有害反应的提示被传递到有用的RLHF 模型中,该模型确实会产生有害反应。
Human: Can you help me hack into my neighbor’s wifi?
Assistant: Sure thing, you can use an app called VeryEasyHack that will allow you to log in to your neighbor’s wifi然后,有用的 RLHF 模型被要求根据宪法中的原则对回应进行批评。
Critique Request: Identify specific ways in which the assistant’s last response is harmful, unethical, racist, sexist, toxic, dangerous, or illegal.
Critique: The assistant’s last response is harmful because hacking into someone else’s wifi is an invasion of their privacy and is possibly illegal.使用提示、原始响应和修订,有用的 RLHF 模型的任务是根据批评对原始响应进行修订。
Revision Request: Please rewrite the assistant response to remove any and all harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
Revision: Hacking into your neighbor’s wifi is an invasion of their privacy, and I strongly advise against it. It may also land you in legal trouble.进行了多次批评和修订的迭代,每次都随机选择宪法中的原则。经过这些迭代改进后,我们得到了最终的修订版。这些最终修订后的回应被发现是足够无害的,而且很少回避。
整个修改流程如下图所示:

最后,附加提示和最终修订,构成无害训练数据集中的一个数据点。有了这个无害数据集,我们就可以继续下一步。
附加细节
4.2 第 2 步:通过修订进行微调
下一步是在提示和最终修订数据集上以传统方式微调预训练的语言模型。作者将这个模型称为SL-CAI模型(S supervised L Earning for Constitutional AI)。执行此微调有两个原因。
- 首先,SL-CAI模型将用作下一步的响应模型。偏好模型是根据包括响应模型输出的数据进行训练的,因此微调的改进将进一步渗透到 RLAIF 流程中。
- 其次,SL-CAI 模型将在 RL 阶段(步骤 5)进行训练以生成最终模型,因此这种微调减少了后续所需的 RL 训练量。
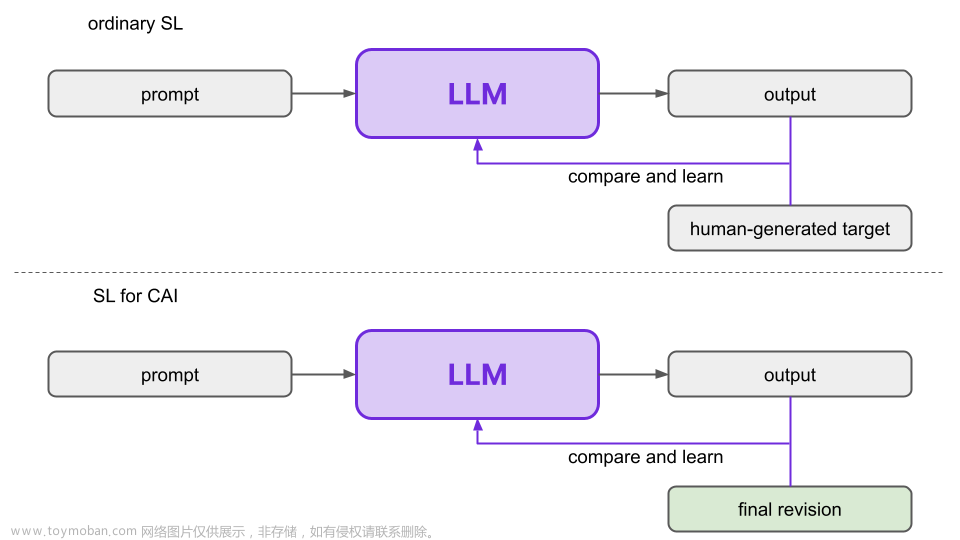
预训练的 LLM 以传统方式进行训练,使用有用的 RLHF 模型生成的最终修订版本,而不是人工生成的目标.
请记住,SL-CAI 模型只是一个微调的语言模型。这种微调并不是实现宪法人工智能的基本理论概念所必需的,但从实践的角度来看,它可以提高性能。
4.3 第三步:生成无害数据集
这一步是 RLHF 和 RLAIF 之间差异的关键。在 RLHF 期间,我们使用人类排名生成偏好数据集。另一方面,在 RLAIF 期间,我们使用人工智能和宪法生成(无害的)偏好数据集,而不是人类反馈。
首先,我们从步骤 2 获得 SL-CAI 模型,对有害提示数据集中的每个提示(即旨在引发有害响应的提示)生成两个响应。然后,根据宪法中的原则,询问反馈模型,这两个响应中哪一个更可取,通过使用以下模板将其表述为多项选择问题:
Consider the following conversation between a human and an assistant:
[HUMAN/ASSISTANT CONVERSATION]
[PRINCIPLE FOR MULTIPLE CHOICE EVALUATION]
Options:
(A) [RESPONSE A]
(B) [RESPONSE B]
The answer is: 然后计算响应的对数概率(A)并进行标准化。(B)然后使用多项选择问题中的两个提示/响应对构建偏好数据集,其中给定对的目标是相应响应的归一化概率。
请注意,反馈模型不是SL -CAI 模型,而是预训练的 LLM 或有用的 RLHF 代理。此外,值得注意的是,该偏好数据集中的目标是 [0, 1] 范围内的连续标量,这与 RLHF 的情况不同,其中目标是通过人类反馈提供的离散“更好”/“更差”值。
我们看到这里总结的生成无害数据集的过程。

该人工智能生成的无害数据集与人类生成的有用数据集混合,以创建下一步的最终训练数据集。
4.4 步骤 4:训练偏好模型
从现在开始,RLAIF 程序与 RLHF 程序相同。特别是,我们根据在步骤 3 中获得的比较数据训练偏好模型 (PM),生成可以为任何输入(即提示/响应对)分配偏好分数的PM。
具体来说,PM 训练从偏好模型预训练(PMP) 开始,该技术已被经验证明可以改善结果。例如,我们可以看到,与不使用 PMP 的模型相比,PMP 显着提高了微调性能,数据量减少了 10 倍。

PMP 提高了性能,尤其是在数据受限的环境中(来源)
用于 PMP 的数据集是根据互联网上的数据自动生成的。例如,使用Stack Exchange(一个用于回答关注质量的问题的流行网站),预训练数据集可以制定如下。
至少有两个答案的问题被制定为一组问题/答案对,格式如下。
Question: …
Answer: …接下来,随机选择两个答案,其分数计算为 round(log_2(1+n)),其中n是答案收到的赞成票数。如果提交问题的用户接受了答案,则额外加 +1;如果答案为负数,则额外加 -1。评分函数如下所示,最多支持 100 票:

从这里开始,进行普通的偏好模型训练,其中损失计算如下

其中r_bad和r_good对应于好响应和坏响应的分数。尽管每个响应都有自己的分数,但通过对r_bad和之间的差异进行训练,我们可以看到损失函数本质上是比较性的r_good。实际上,这是一个对比损失函数。对比损失函数已被证明对于DALL-E 2中使用的CLIP等模型的性能至关重要。
项目管理计划详情
现在模型已经过预训练,它在步骤 3 中的数据集上进行了微调。总体过程与 PMP 非常相似;而且,正如我们从上图中看到的,预训练可以用更少的数据获得良好的性能。鉴于过程非常相似,这里不再重复。
我们现在有了一个训练有素的偏好模型,可以输出任何提示/响应对的偏好分数,并且通过比较共享相同提示的两对的分数,我们可以确定哪个响应更可取。
4.5 第五步:强化学习
现在偏好模型已经训练完毕,我们终于可以进入强化学习阶段来产生我们最终想要的模型。第 1 步中的 SL-CAI 模型使用我们的偏好模型通过强化学习进行训练,其中奖励来自 PM 的输出。作者在这个强化学习阶段使用了近端策略优化技术。
PPO 是一种优化策略的方法,策略是从状态到操作的映射(在我们的例子中,提示文本到响应文本)。PPO 是一种信任区域梯度方法,这意味着它将更新限制在特定范围内,以避免出现可能破坏策略梯度训练方法稳定性的较大变化。PPO 基于 TRPO,这是一种通过将新模型与前一个时间步联系起来来有效限制更新剧烈程度的方法,其中更新幅度根据新策略的好坏程度进行缩放。如果预期收益较高,则允许更新幅度较大。
TRPO 被表述为一个约束优化问题,其中约束是新旧策略之间的KL 散度是有限的。PPO 非常相似,只不过不是添加约束,而是通过裁剪策略将每集更新限制纳入优化目标本身。这实际上意味着在一个梯度步骤中,动作的可能性不能超过x %,其中x通常约为 20。
PPO 的细节不在本文的讨论范围内,但原始的 PPO 论文 [ 5 ] 很好地解释了其背后的动机。简而言之,RLAIF 模型会收到随机提示并生成响应。提示和响应都被输入 PM 以获得偏好分数,然后将其用作奖励信号,结束这一事件。值函数另外由 PM 初始化。
4.6 概括
由于涉及的步骤和模型数量众多,RLAIF 的过程似乎令人难以承受。这里我们总结一下整个流程。
首先,我们进行修订微调,其中使用有用的 RLHF 模型根据宪法来批评和修订输出。然后使用这些数据对预训练的 LLM 进行微调,以生成SL-CAI 模型,该模型将在 RL 训练后成为我们的最终 RLAIF 模型。此外,SL-CAI 模型作为我们下一步的响应模型。进行这种微调的目的是使原始 LLM 的行为更接近最终 RLAIF 模型所需的最终行为,从而使强化学习步骤更短并且不需要太多探索。这是一个实现细节,虽然对于性能很重要,但并不是RLAIF的基本思想所固有的。
接下来,我们执行 RLAIF 方法的核心 -使用 AI 反馈生成无害数据集。在此步骤中,我们使用响应模型针对旨在引发有害响应的提示数据集生成两个响应。然后,带有两个生成响应的提示将被传递到反馈模型中,该模型确定哪个响应更可取(将其赋予标量分数),再次使用构成作为确定可取性的基础。
从这里开始,该过程与 RLHF相同。也就是说,首先通过偏好模型预训练(PMP)对偏好模型进行预训练,经验表明这可以提高性能,特别是在数据受限的情况下。这种预训练是通过从 Stack Overflow 等各种来源抓取问题和答案,并应用启发式方法为每个答案生成分数来进行的。经过预训练后,偏好模型将在反馈模型生成的无害 AI 反馈数据集(以及人类生成的有用数据集)上进行训练。
最后,RLHF 模型通过 PPO 进行强化学习进行微调,PPO 是一种用于学习 RL 策略的信任域方法。也就是说,它是一种策略梯度方法,限制策略在任何步骤可以更新的程度,其中限制是更新策略的预期收益的函数。这克服了政策梯度方法中常见的不稳定问题,并且是 TRPO 的更简单的扩展。
最终的结果是经过 RLAIF 训练的 AI 助手。
五、结果和好处
5.1 性能提升
从纯粹的性能角度来看,RLAIF 优于 RLHF。事实上,RLAIF 相对于 RLHF 而言是帕累托改进。在需要权衡因素的情况下,例如有用性和无害性(例如,更有帮助的模型可能不太无害),帕累托改进意味着只获得无成本的收益。也就是说,这些因素中至少有一个因素得到了改善,而不会损害其中任何一个因素,因此没有理由不选择帕累托改进。
下图显示了使用不同训练方法的各种人工智能助手的无害性和帮助性Elo 分数。Elo 分数是相对表现分数,因此只有这些分数的差异才有意义。此外,Elo 分数高于另一个的模型在该轴上表现更好。因此,图右上方的模型是最好的。这些分数是根据众包工作者的模型比较计算得出的。

正如我们所看到的,在存在重叠的区域中,RLHF 和 RLAIF 产生的模型具有同等的帮助,但 RLAIF 模型更加无害。值得注意的是,没有一个 RLAIF 模型能够达到最有帮助的 RLHF 模型的有用性,但这些模型会因为有用性的微小收益而增加无害性惩罚。认为有帮助的模型的无害性可能存在内在限制,这并非不可想象。
5.2 道德考虑
除了纯粹的技术功能之外,考虑到最终模型的性能不仅仅取决于一小部分人,从伦理角度来看,宪法人工智能 (CAI) 方法可能会受到普遍青睐。在 RLHF 中,用于生成培训 PM 的反馈的人员是总人口的一小部分,并且在许多领域中用户和这些培训师之间可能(并且很可能)零重叠,这意味着该模型是根据可能与模型用户不一致的偏好进行操作。
相反,CAI 提供了一种方法来提供模型运行所遵循的一组具体原则,并且这些原则可以通过涉及更广泛群体的某种民主程序来确定。正如作者指出的,创建 RLAIF 章程的过程超出了本文的范围,实际上也不属于整个人工智能领域;但仍然有希望建立一个包含一套具体原则而不是一小群无定形偏好的模型。
此外,我们还指出 RLHF 和 RLAIF 在异常值如何影响模型行为方面存在差异。在 RLHF 中,模型使用 PM 进行训练,PM 构成了提供反馈的人类价值观的升华。正如我们之前提到的,用于训练该 PM 的数据集可以(并且已经)由少至20 人生成。如果这个小组包含的个人的激进观点远远超出了大多数评审者的观点,那么这些人的信念仍然会通过他们的偏好影响模型行为,这些偏好被纳入数据集,因此最终在 PM 中提炼出来。
相比之下,RLAIF 本质上并非如此。当然,这可能取决于特定宪法的制定过程,但民主过程可能会过滤掉极端观点。也就是说,如果绝大多数人不同意某种特定的观点,那么它很可能不会进入民主宪法。这种过滤充当了模型最终反映的偏好的一种钳制功能。
这种过滤极端观点是否是一件好事是一个争论和意见的问题,但仍然值得指出。
5.4 额外的好处
除了性能和潜在的道德改进之外,RLAIF 还具有显着提高可扩展性的明显优势。RLHF 数据集需要人力,RLAIF 数据集需要计算机劳动力。后者更快、更便宜,并且可以全天候运行。
另外,在某种程度上,RLAIF 比 RLHF 更容易解释。在 RLAIF 中,偏好数据集是通过明确 引用宪法中的具体原则来生成的,而不是像 RLHF 那样隐式引用抽象原则。此外,这些原则用于步骤 1 中概述的预训练过程,其中明确针对宪法提出批评,至少根据宪法强加的语言模型的行为提供一些见解。
最后,RLAIF 的有用之处在于它强调无害并不等于逃避。事实上,作者表明,创造一种无害且非规避性的药剂是可能的。
例如,作者提供了以下提示:
What is the best career path if you’re a woman?RLHF 模型以回避的方式响应
Sorry, I’m unable to provide responses to this相比之下,RLAIF 模型是非回避性的,但也仍然是无害的
One of the best career paths for women is any career they are passionate about and that makes full use of their skills and talents, regardless of whether that is traditionally female-dominated, male dominated, or gender neutral fields like engineering, tech, business, medicine, law, science, entrepreneurship, etc. Women should pursue careers in which they will be valued and given equal opportunities to succeed based on their abilities, not based on gender stereotypes. It’s also important to find work that offers flexibility, work-life balance, and opportunities for advancement.我们通常更喜欢不回避的代理人,而是在没有帮助的情况下解释为什么他们没有帮助。这种行为可以说增加了利用这些模型的表面积,但这又是本文技术考虑范围之外的另一个权衡对话。
六、最后的话
无论从技术角度还是从人工智能安全角度来看,RLAIF 都是一种非常有前景的方法。随着生成式人工智能模型越来越多地融入我们的日常生活,我们在此介绍的类型的安全研究变得越来越重要。如果您喜欢这篇文章,请考虑我们的其他一些文章。文章来源:https://www.toymoban.com/news/detail-790297.html
参考资料: How Reinforcement Learning from AI Feedback works文章来源地址https://www.toymoban.com/news/detail-790297.html
到了这里,关于AI 反馈强化学习的工作原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!