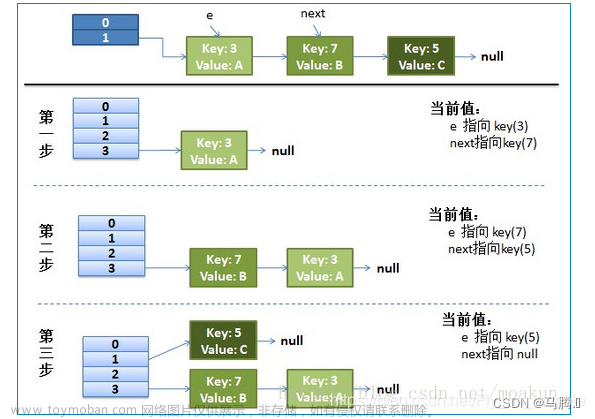
✔️典型解析
在JDK 1.7中,ConcurrentHashMap使用了分段锁技术,即将哈希表分成多个段,每个段拥有一个独立的锁。这样可以在多个线程同时访问哈希表时,只需要锁住需要操作的那个段,而不是整个哈希表,从而提高了并发性能。
虽然JDK 1.7的这种方式可以减少锁竞争,但是在高并发场景下,仍然会出现锁亮争,从而导致性能下降。
在JDK 1.8中,ConcurrentHashMap的实现方式进行了改进,使用分段锁 (思想)和“CAS+Synchronized”的机制来保证线程安全。在JDK 1.8中,ConcurrentHashMap会在添加元素时,如果某个段为空,那么使用CAS操作来添加新节点;如果段不为空,使用Synchronized锁住当前段,再次尝试put。这样可以避免分段锁机制下的锁粒度太大,以及在高并发场景下,由于线程数量过多导致的锁竞争问题,提高了并发性能。
分段锁其实是一种思想。1.7中的”分段锁”和1.8中的”分段锁"不是一回事儿,而当我们说1.7的分段锁,一般特指是他的Segment,而1.8中我们指的是一种分段加锁的思想,加锁的时候只对当前段加锁,而不是整个map加锁。
ConcurrentHashMap 是 Java 并发包(java.util.concurrent)中的一个类,它为多线程环境中的高并发访问提供了高效的解决方案。ConcurrentHashMap 通过分段锁机制和动态调整等技术,在保证线程安全的同时,也提供了很高的并发性能。
以下是 ConcurrentHashMap 保证线程安全的几个关键点:
- 分段锁机制:ConcurrentHashMap 使用了分段锁的技术,将数据分成多个段(Segment),每个段都是一个小的哈希表。当一个线程访问某个段的时候,只会锁定这个段,不会阻塞其他段的访问。这样,多个线程可以同时访问不同的段,从而实现高并发。
- 锁分离:除了传统的互斥锁,ConcurrentHashMap 还使用了分离锁(Striped Locking)。这是一种锁的优化技术,允许多个线程同时获取同一把锁的不同部分,提高了并发性能。
- 动态调整:ConcurrentHashMap 在运行过程中会根据实际负载情况动态调整段的大小。当某个段负载过高时,会分裂出新的段;当某个段负载过低时,会合并相邻的段。这种动态调整可以保证在各种负载情况下,都能提供高效的并发性能。
- CAS操作:ConcurrentHashMap 使用 CAS(Compare-and-Swap)操作来保证线程安全。CAS 是一种无锁的原子操作,可以在不阻塞线程的情况下,安全地更新内存中的变量。
-
红黑树:为了解决哈希冲突,ConcurrentHashMap 在链表长度超过一定阈值时,会将链表转换为红黑树。红黑树是一种自平衡的二叉查找树,可以在 O(log n) 的时间复杂度下完成查找、插入和删除操作。
这些机制和技术共同作用,使得ConcurrentHashMap在多线程环境下提供了高效的并发访问,同时也保证了线程安全。
看一个示例
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* @author xinbaobaba
* 演示ConcurrentHashMap在多线程环境中的线程安全性和高性能。
* 将使用多个线程同时对ConcurrentHashMap进行读和写操作,并观察其表现
*/
public class ConcurrentHashMapComplexExample {
public static void main(String[] args) {
// 创建一个ConcurrentHashMap对象
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
// 创建一个线程池
ExecutorService executor = Executors.newFixedThreadPool(5);
// 启动多个线程同时进行读和写操作
for (int i = 0; i < 10; i++) {
executor.execute(() -> {
try {
// 随机等待一段时间,模拟异步操作
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 随机选择一个键进行读写操作
String key = "key" + (int) (Math.random() * 10);
if (Math.random() > 0.5) {
// 有50%的概率进行写操作,即添加一个键值对
map.put(key, "value" + key);
} else {
// 50%的概率进行读操作,即获取一个键的值
String value = map.get(key);
System.out.println("Read value for key " + key + ": " + value);
}
});
}
// 关闭线程池,等待所有线程执行完毕
executor.shutdown();
try {
if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {
executor.shutdownNow(); // 强制关闭线程池
}
} catch (InterruptedException e) {
executor.shutdownNow(); // 强制关闭线程池
}
}
}
示例中,创建了一个包含5个线程的线程池。每个线程随机等待一段时间后,执行一个读或写操作。读操作使用map.get方法获取键的值,而写操作使用
map.put方法添加一个键值对。由于ConcurrentHashMap是线程安全的,因此这些读和写操作可以并发执行,而不会互相干扰。最后,我们等待所有线程执行完毕,并关闭线程池。
趁热打铁,我们来看一个实际应用中的Demo:
import java.util.concurrent.ConcurrentHashMap;
/**
* Demo之如何使用ConcurrentHashMap实现一个线程安全的银行账户转账系统
*/
public class BankAccountTransferSystem {
private final ConcurrentHashMap<String, Integer> accounts;
public BankAccountTransferSystem() {
accounts = new ConcurrentHashMap<>();
// 初始化账户余额
accounts.put("Alice", 1000);
accounts.put("Bob", 2000);
}
public void transfer(String from, String to, int amount) {
int fromBalance = accounts.get(from);
if (fromBalance >= amount) {
int toBalance = accounts.get(to);
accounts.put(from, fromBalance - amount);
accounts.put(to, toBalance + amount);
System.out.println("Transfer successful: " + amount + " from " + from + " to " + to);
} else {
System.out.println("Insufficient funds: " + amount + " from " + from);
}
}
}
Demo中,创建了一个名为BankAccountTransferSystem的类,它使用ConcurrentHashMap来存储账户信息,包括账户名和账户余额。类中的transfer方法用于执行转账操作,它接受三个参数:转出账户名、转入账户名和转账金额。在执行转账操作之前,我们首先获取转出账户的当前余额,并检查是否足够支付转账金额。如果余额足够,则从转出账户中扣除转账金额,并将相同金额添加到转入账户中。最后,我们打印出转账是否成功的消息。由于ConcurrentHashMap是线程安全的,因此多个线程可以同时调用transfer方法来执行转账操作,而不会出现数据不一致的问题。这个例子可以应用于在线银行系统、电子支付平台等需要高并发、高可靠性的金融应用场景。
✔️ 拓展知识仓
✔️ 什么是CAS(Compare And Swap)
CAS是Compare And Swap的缩写,直译为“比较并交换”。CAS是现代CPU广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。CAS是一种原子操作,用于实现多线程同步的原子指令。在多线程并发中,CAS能够保证共享资源的原子性操作。具体来说,它比较一个内存位置的值,并且只有当该值与预期值相等时,才会修改这个内存位置的值为新值。CAS返回操作是否成功,如果内存位置原来的值用于判断是否CAS成功。
在Java并发应用中,CAS通常用于实现无锁的解决方案,这是一种基于乐观锁的操作。相对于synchronized或Lock等锁机制,CAS是一种轻量级的实现方案。当多个线程同时对某个资源进行CAS操作时,只有一个线程能够操作成功,而其他线程则只收到操作失败的信号。CAS不会阻塞其他线程,而是在操作失败时重新读取数据并进行比较。
在并发编程中,CAS的优势在于它可以避免使用重量级锁所带来的性能开销,并且能够在多线程并发的情况下保证共享资源的原子性操作。然而,CAS也有一些缺点,例如循环时间长开销大、只能保证一个共享变量的原子操作以及对多个共享变量操作时不能保证原子性等。
CAS是一种轻量级锁机制,用于实现多线程同步的原子指令,它比较并交换内存中的共享数据,保证了新的值总是基于最新的信息计算。在并发编程中,CAS可以避免使用重量级锁所带来的性能开销,并且能够在多线程并发的情况下保证共享资源的原子性操作。
✔️CAS和互斥量有什么区别
CAS(Compare-and-Swap)和 互斥量(Mutex)都是多线程编程中常用的同步原语,但它们的工作机制和适用场景有所不同。
- 工作机制:
- CAS 是一种原子操作,用于实现无锁的同步。它比较并交换内存中的共享数据,只有当该值与预期值相等时,才会修改这个内存位置的值为新值。CAS 操作可以保证共享资源的原子性操作。
- 互斥量则是一种锁机制,用于保护共享资源的访问,确保同一时刻只有一个线程可以访问被保护的代码或数据。互斥量通过阻塞线程的方式来避免同时被多个线程访问。
- 适用场景:
- CAS 适用于实现无锁的同步,适用于读多写少的场景,可以避免线程阻塞和唤醒的开销。
- 互斥量适用于需要保护共享资源的访问的场景,可以防止数据竞争和线程间的冲突。
- 性能:
- CAS 通常比互斥量具有更好的性能,因为它避免了线程阻塞和唤醒的开销。在读多写少的场景下,使用 CAS 可以减少线程间的竞争和上下文切换的开销。
- 互斥量可能会引起线程阻塞,导致性能下降。但是,互斥量可以保证共享资源的完整性和一致性。
CAS 和互斥量都是重要的同步原语,它们的选择取决于具体的场景和需求。在读多写少、对性能要求较高的场景下,可以考虑使用 CAS;在需要保护共享资源、保证一致性和完整性的场景下,可以使用互斥量。
✔️如何使用CAS和互斥量
一个简单的Java程序示例,说明如何使用CAS和互斥量:
import java.util.concurrent.atomic.AtomicInteger;
public class CASExample {
private AtomicInteger value = new AtomicInteger(0);
public void increment() {
// 使用CAS实现原子性增1操作
int expectedValue = value.get();
int newValue = expectedValue + 1;
while (!value.compareAndSet(expectedValue, newValue)) {
expectedValue = value.get();
newValue = expectedValue + 1;
}
}
public static void main(String[] args) {
CASExample example = new CASExample();
// 创建多个线程并发地调用increment方法
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
example.increment();
}
}).start();
}
}
}
使用
AtomicInteger来作为共享变量,通过CAS(Compare-and-Swap)操作来实现原子性增1操作。compareAndSet方法会比较当前值和预期值是否相等,如果相等则将值更新为新值,并返回true表示操作成功;否则,返回false表示操作失败。在失败时,我们再次获取当前值并尝试更新,直到成功为止。这样可以保证多个线程并发地调用increment方法时,共享变量的值能够正确地增加。
下面是一个使用互斥量(Mutex)的示例:
import java.util.concurrent.locks.Mutex;
import java.util.concurrent.locks.ReentrantMutex;
public class MutexExample {
private final Mutex mutex = new ReentrantMutex();
private int sharedResource = 0;
public void accessResource() {
mutex.lock(); // 获取互斥量锁
try {
// 访问或修改共享资源
sharedResource++;
System.out.println("Accessed shared resource: " + sharedResource);
} finally {
mutex.unlock(); // 释放互斥量锁
}
}
public static void main(String[] args) {
MutexExample example = new MutexExample();
// 创建多个线程并发地调用accessResource方法
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
example.accessResource();
}
}).start();
}
}
}
使用
ReentrantMutex作为互斥量。在访问共享资源之前,先通过lock()方法获取互斥量锁,确保同一时刻只有一个线程可以访问共享资源。在访问完成后,通过unlock()方法释放互斥量锁。这种方式可以避免多个线程同时访问共享资源导致的冲突和数据不一致问题。
✔️CAS和Synchronized的区别
CAS(Compare-and-Swap)和 Synchronized 是Java中两种处理线程同步的重要机制,它们在使用场景、实现原理和优缺点上存在显著的区别。
- 使用场景:CAS常用于实现轻量级的锁,适用于并发较低的情况。Synchronized则常用于高并发的情况,它会阻塞没有获得锁的线程,等待持有锁的线程释放锁。
- 实现原理:CAS是一种乐观锁机制,在操作一个值时,会先比较预期值和内存值是否相等,如果相等则更新内存值,否则就继续循环比较和交换。而Synchronized的实现机制更复杂,它会锁定被访问对象,防止其他线程访问。
- 原子性:CAS保证的是单个变量的原子性操作,而无法保证整个代码块的原子性。相比之下,Synchronized可以保证整个代码块的原子性。
- CPU开销:由于CAS机制不需要阻塞线程,所以其CPU开销较小,适用于并发较低的情况。而Synchronized在并发较高的情况下表现更佳,但其CPU开销较大,因为需要阻塞等待锁的线程。
总的来说,CAS和Synchronized都是用于处理线程同步的重要机制,各有其使用场景、实现原理、原子性以及CPU开销方面的特点。在实际应用中,需要根据具体需求选择使用哪种机制。
下面我们使用Demo来帮助理解:
- CAS示例:
import java.util.concurrent.atomic.AtomicInteger;
/**
* 使用Java代码对CAS和Synchronized进行讲解的
*/
public class CASExample {
private AtomicInteger value = new AtomicInteger(0);
public void increment() {
int expectedValue = value.get();
int newValue = expectedValue + 1;
while (!value.compareAndSet(expectedValue, newValue)) {
expectedValue = value.get();
newValue = expectedValue + 1;
}
}
public static void main(String[] args) throws InterruptedException {
CASExample example = new CASExample();
Thread t1 = new Thread(() -> { example.increment(); });
Thread t2 = new Thread(() -> { example.increment(); });
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final Value: " + example.value); // 输出:Final Value: 2
}
}
在这个示例中,使用了
AtomicInteger类,它提供了CAS操作。increment方法通过循环使用compareAndSet方法来实现原子性增1操作。如果预期值与内存值相等,则将内存值更新为新值;否则,继续循环获取预期值并尝试更新。由于使用了CAS操作,两个线程可以并发地调用increment方法,最终共享变量的值为2。
- Synchronized示例:
public class SynchronizedExample {
private int sharedResource = 0;
public void accessResource() throws InterruptedException {
synchronized (this) { // 获取当前对象的锁
sharedResource++;
System.out.println("Accessed shared resource: " + sharedResource);
Thread.sleep(100); // 模拟耗时操作
} // 释放锁
}
public static void main(String[] args) throws InterruptedException {
SynchronizedExample example = new SynchronizedExample();
Thread t1 = new Thread(() -> { example.accessResource(); });
Thread t2 = new Thread(() -> { example.accessResource(); });
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final Value: " + example.sharedResource); // 输出:Final Value: 2
}
}
在这个示例中,我们使用了
synchronized关键字来实现线程同步。在accessResource方法中,通过synchronized (this)获取当前对象的锁。这样,在同一时刻只有一个线程可以访问共享资源。由于使用了同步机制,两个线程会交替执行,最终共享变量的值为2。
✔️ConcurrentHashMap的优缺点
ConcurrentHashMap是Java中一个线程安全的哈希表实现,它支持高并发的读写操作。以下是ConcurrentHashMap的优缺点:
优点:
- 线程安全:ConcurrentHashMap提供了线程安全的操作,可以在多线程环境下使用,而不需要额外的同步措施。
- 高并发性能:通过分段锁机制,ConcurrentHashMap可以将整个哈希表分成多个段,每个段由独立的线程进行操作,从而大大提高了并发性能。
- 高效性能:ConcurrentHashMap在读写操作上具有较高的性能,尤其是在读操作方面,因为它不需要加锁就可以访问数据。
缺点:
- 无法保证顺序:由于ConcurrentHashMap采用哈希表结构,其迭代顺序并不固定,因此在某些情况下无法保证结果的顺序。
- 不适合作为队列使用:ConcurrentHashMap不适合用作队列或栈等需要先进先出(FIFO)或后进先出(LIFO)的数据结构,因为其迭代顺序并不符合这些数据结构的特性。
- 无法进行精确控制:由于ConcurrentHashMap采用分段锁机制,无法对整个哈希表进行精确控制,因此在某些情况下可能会存在数据不一致的问题。
ConcurrentHashMap适用于需要高并发读写的场景,尤其适合读操作较多的场景。如果需要保证结果的顺序或者作为队列使用,或者需要精确控制整个数据结构,那么应该考虑其他同步措施或使用其他数据结构。
✔️能用ConcurrentHashMap实现队列吗??
尽管ConcurrentHashMap适用于高并发的读写操作,但它不适合用作队列。队列是一种先进先出(FIFO)的数据结构,要求数据的顺序是按照入队顺序进行的。而ConcurrentHashMap的迭代顺序并不固定,因此无法保证数据的顺序。
如果你需要实现一个线程安全的队列,可以考虑使用Java提供的java.util.concurrent.BlockingQueue接口。BlockingQueue接口提供了线程安全的队列操作,包括入队、出队、等待和中断等操作,非常适合实现多线程之间的通信和协作。
下面是使用BlockingQueue实现队列的示例代码:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class ConcurrentQueue<T> {
private final BlockingQueue<T> queue = new LinkedBlockingQueue<>();
public void enqueue(T item) throws InterruptedException {
queue.put(item); // 入队操作,如果队列已满则阻塞等待
}
public T dequeue() throws InterruptedException {
return queue.take(); // 出队操作,如果队列为空则阻塞等待
}
}
Demo中,使用
LinkedBlockingQueue作为队列的实现,它是一个基于链接节点的、可伸缩的阻塞队列。enqueue方法使用put方法将元素加入队列,如果队列已满则阻塞等待;dequeue方法使用take方法从队列中取出元素,如果队列为空则阻塞等待。通过这种方式,可以实现线程安全的队列操作。
✔️终极环节(源码解析)
ConcurrentHashMap将哈希表分成多个段,每个段拥有一个独立的锁,这样可以在多个线程同时访问哈希表时,只需要锁住需要操作的那个段,而不是整个哈希表,从而提高了并发性能。下面是ConcurrentHashMap中分段锁的代码实现:
static final class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this .hash = hash;
this .key = key;
this.val = val;
this .next = next;
}
//..........
}
static final class Segment<K,V> extends Reentrantlock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
}
在上面的代码中,我们可以看到,每个 Segment 都是ReentrantLock的实现,每个Segment包含一个HashEntry数组,每个HashEntry则包合一个key-value键值对。
接下来再看下在JDK 1.8中,下面是ConcurrentHashMap中CAS+Synchronized机制的代码实现:文章来源:https://www.toymoban.com/news/detail-790431.html
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
//对 key 的 hashCode 进行扰动
int hash = spread(key.hashCode());
int binCount = 0;
// xun环操作
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果 table 为 null 或长度为 0,则进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 如果哈希槽为空,则通过 CAS 操作尝试插入新节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab,i, null,new Node<K,V>(hash , key, value, null)))
break;
}
//如果哈希槽处已经有节点,且 hash 值为 MOVED,则说明正在进行扩容,需要帮助迁移数据
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 如果哈希槽处已经有节点,且 hash 值不为 MOVED,则进行链表/红黑树的节点遍历或插入操作
else {
V oldVal = null;
// 加锁,确保只有一个线程操作该节点的链表/红黑树
synchronized (f) {
if (tabAt(tab, i) == f) {
// 遍历链表,找到相同 key 的节点,更新值或插入新节点
binCount = 1;
for (Node<k,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K ,V> pred = e;
if ((e = e.next) == null) {
// 将新节点插入到链表末尾
if (casNext(pred, new Node<K,V>(hash, key.value, null))) {
break;
}
}
}
}
// 历红黑树,找到相同 key 的节点,更新值或插入新节点
else if (f instanceof TreeBin) {
Node<k,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value:
}
}
}
}
//如果插入或更新成功,则进行可能的红黑树化操作
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) {
treeifyBin(tab,i);
}
//如果替换旧值成功,则返回旧值
if (oldVal != null)
return oldVal;
break;
}
}
}
在上述代码中,如果某个段为空,那么使用CAS操作来添加新节点: 如果某个段中的第一个节点的hash值为MOVED,表示当前段正在进行扩容操作,那么就调用helpTransfer方法来协助扩容:否则,使用Synchronized锁住当前节点,然后进行节点的添加操作。文章来源地址https://www.toymoban.com/news/detail-790431.html
到了这里,关于【昕宝爸爸小模块】ConcurrentHashMap是如何保证线程安全的的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!