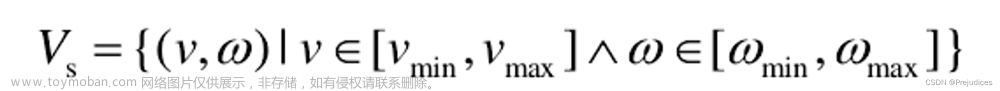代理模型是指在分析和优化设计过程中可替代那些比较复杂和费时的数值分析的近似数学模型,也称为响应面模型、近似模型或元模型。代理模型方法可以大大提高优化设计效率、降低优化难度,并有利于实现并行优化设计。在现有代理模型方法中,源于地质统计学的Kriging模型是一种具有代表性的方法,本文对Kringing代理模型理论进行了一些推导。
1.1 代理模型问题的基本描述
对于一个有
m
m
m个设计变量的优化问题,假定需要建立未知函数
y
:
R
m
→
R
y: \R^m\rightarrow\R
y:Rm→R 对设计变量
x
=
[
x
1
x
2
.
.
.
x
m
]
T
∈
R
m
\mathbf{x}=[x_1 \ \ x_2 \ \ ... \ \ x_m]^T \in \R^m
x=[x1 x2 ... xm]T∈Rm 的代理模型。为此,首先采用试验设计方法在设计空间中进行抽样(如LHS方法或均匀采样方法),得到
n
n
n 个样本点:
S
=
[
x
(
1
)
x
(
2
)
.
.
.
x
(
n
)
]
∈
R
n
×
m
(1)
\mathbf{S} = [\mathbf x^{(1)} \ \ \mathbf x^{(2)} \ \ ... \ \ \mathbf x^{(n)}] \in \R^{n \times m} \tag 1
S=[x(1) x(2) ... x(n)]∈Rn×m(1)
对上述
n
n
n 个样本点通过试验或者数值仿真得到其
n
n
n 个响应值:
y
s
=
[
y
(
1
)
y
(
2
)
.
.
.
y
(
n
)
]
T
=
[
y
(
x
(
1
)
)
y
(
x
(
2
)
)
.
.
.
y
(
x
(
n
)
)
]
T
∈
R
n
(2)
\mathbf{y}_s=[y^{(1)} \ \ y^{(2)} \ \ ... \ \ y^{(n)}]^T=[y(\mathbf{x^{(1)}}) \ \ y(\mathbf{x} ^{(2)}) \ \ ... \ \ y(\mathbf{x} ^{(n)})]^T \in \R ^n \tag 2
ys=[y(1) y(2) ... y(n)]T=[y(x(1)) y(x(2)) ... y(x(n))]T∈Rn(2)
所有样本点和对应的响应值构成样本数据集
(
S
,
y
s
)
(\mathbf {S,y_s})
(S,ys),基于样本点数据集可以构建代理模型,这里主要介绍Kriging模型的建立方法。
说明:
如果一个样本对应多个响应值(目标函数),则需要对它们分别建立代理模型,或建立同时输出多个目标函数的代理模型。
1.2 Kriging模型及其预估值
Kriging模型是一种插值模型,其插值结果为已知样本响应值的线性加权,即:
y
^
(
x
)
=
∑
i
=
1
n
ω
(
i
)
y
(
i
)
(3)
\hat{y}(\mathbf{x})= \sum_{i=1}^n\omega^{(i)}y^{(i)} \tag3
y^(x)=i=1∑nω(i)y(i)(3)
因此,只要给出加权系数
ω
=
[
ω
(
1
)
ω
(
2
)
.
.
.
ω
(
n
)
]
T
\boldsymbol{\omega}=[\omega ^{(1)} \ \ \omega^{(2)} \ \ ... \ \ \omega ^{(n)}]^T
ω=[ω(1) ω(2) ... ω(n)]T 的值,就可以得到设计空间中任意点的响应值。为了计算加权系数,Kriging模型引入统计学假设:将未知函数看成是某个高斯静态随机过程的具体实现,该静态随机过程定义为:
Y
(
x
)
=
β
0
+
Z
(
x
)
(4)
Y(\mathbf x)=\beta_0 + Z(\mathbf x) \tag 4
Y(x)=β0+Z(x)(4)
上式中,
β
0
\beta_0
β0 为未知常数,也被称为全局趋势模型,代表
Y
(
x
)
Y(\mathbf x)
Y(x)的数学期望值;
Z
(
⋅
)
Z(\cdot )
Z(⋅) 是均值为零、方差为
σ
2
\sigma ^2
σ2 的静态随机过程。在设计空间不同位置处,这些随机变量存在一定的相关性(协方差),表示为:
C
o
v
[
Z
(
x
)
,
Z
(
x
′
)
]
=
σ
2
R
(
x
,
x
′
)
(5)
Cov[Z(\mathbf x),Z(\mathbf {x'})]=\sigma^2R(\mathbf x, \mathbf {x'}) \tag 5
Cov[Z(x),Z(x′)]=σ2R(x,x′)(5)
上式中:
R
(
x
,
x
′
)
R(\mathbf x,\mathbf x')
R(x,x′) 为“相关函数”(类比相关系数),相关函数只与样本的空间距离有关,且满足距离为零时等于1,距离为无穷大时等于 0,相关性随着距离的增大而减小。
基于上述假设,Kriging模型寻找最优加权系数
ω
\boldsymbol{\omega}
ω ,使得均方差( 用
Y
s
=
[
Y
(
1
)
Y
(
2
)
…
Y
(
n
)
]
\mathbf Y_s=\begin {bmatrix} Y^{(1)} & Y^{(2)} & \ldots & Y^{(n)} \end {bmatrix}
Ys=[Y(1)Y(2)…Y(n)] 替换
y
s
=
[
y
(
1
)
y
(
2
)
…
y
(
n
)
]
\mathbf y_s=\begin {bmatrix} y^{(1)} & y^{(2)} \ldots & y^{(n)} \end {bmatrix}
ys=[y(1)y(2)…y(n)] )
M
S
E
(
y
^
(
x
)
)
=
E
[
(
ω
T
Y
s
−
Y
(
x
)
)
2
]
(6)
MSE(\hat y (\mathbf x))=E[(\boldsymbol \omega^T\mathbf Y_s -Y(\mathbf x))^2] \tag6
MSE(y^(x))=E[(ωTYs−Y(x))2](6)
最小,并满足如下插值条件(或无偏条件):
E
[
∑
i
=
1
n
ω
(
i
)
Y
(
x
(
i
)
)
]
=
E
(
Y
(
x
)
)
(7)
E[\sum_{i=1}^n\omega^{(i)}Y(\mathbf x^{(i)})]=E(Y(\mathbf x)) \tag 7
E[i=1∑nω(i)Y(x(i))]=E(Y(x))(7)
采用拉格朗日乘数法,令:
L
(
ω
,
λ
)
=
E
[
(
ω
T
Y
s
−
Y
(
x
)
)
2
]
+
μ
{
E
[
∑
i
=
1
n
ω
(
i
)
Y
(
x
(
i
)
)
]
−
E
(
Y
(
x
)
)
}
(8)
L(\omega,\lambda)=E[(\boldsymbol\omega^TY_s-Y(\mathbf x))^2] + \mu \{E[\sum_{i=1}^n\omega^{(i)}Y(\mathbf x^{(i)})]-E(Y(\mathbf x))\} \tag 8
L(ω,λ)=E[(ωTYs−Y(x))2]+μ{E[i=1∑nω(i)Y(x(i))]−E(Y(x))}(8)
则由:
{
∂
L
(
ω
,
μ
)
∂
ω
(
i
)
=
E
[
2
(
ω
T
Y
s
−
Y
(
x
)
)
Y
(
x
(
i
)
)
]
+
μ
E
[
Y
(
x
(
i
)
)
]
=
2
[
∑
j
=
1
n
(
ω
(
j
)
R
(
x
(
j
)
,
x
(
i
)
+
β
0
2
)
]
−
2
[
β
0
2
+
R
(
x
,
x
i
)
]
+
μ
β
0
=
0
∂
L
(
ω
,
μ
)
∂
μ
=
μ
(
β
0
−
β
0
∑
i
=
1
n
ω
(
i
)
)
=
0
(9)
\begin{cases} \frac {\partial L(\boldsymbol\omega, \mu)}{\partial\omega^{(i)}}=E[2(\boldsymbol \omega^T\mathbf Y_s-Y(\mathbf x))Y(\mathbf x^{(i)})]+\mu E[Y(\mathbf x^{(i)})]=2[\sum_{j=1}^n(\omega^{(j)}R(\mathbf x^{(j)},\mathbf x^{(i)} +\beta_0^2)]-2[\beta_0^2+R(\mathbf x,\mathbf x^i)]+\mu\beta_0=0 \\ \frac {\partial L(\boldsymbol \omega,\mu)}{\partial \mu}=\mu(\beta_0 - \beta_0\sum_{i=1}^n \omega(i))=0 \end {cases} \tag 9
{∂ω(i)∂L(ω,μ)=E[2(ωTYs−Y(x))Y(x(i))]+μE[Y(x(i))]=2[∑j=1n(ω(j)R(x(j),x(i)+β02)]−2[β02+R(x,xi)]+μβ0=0∂μ∂L(ω,μ)=μ(β0−β0∑i=1nω(i))=0(9)
化简得:
{
∑
j
=
1
n
ω
(
j
)
R
(
x
(
i
)
,
x
(
j
)
)
+
μ
2
σ
2
=
R
(
x
(
i
)
,
x
)
∑
i
=
1
n
ω
(
i
)
=
1
(10)
\begin {cases} \sum_{j=1}^n\omega^{(j)}R(\mathbf x^{(i)},\mathbf x^{(j)})+\frac {\mu}{2\sigma^2}=R(\mathbf x^{(i)},\mathbf x) \\ \sum_{i=1}^n \omega^{(i)}=1\end {cases} \tag{10}
{∑j=1nω(j)R(x(i),x(j))+2σ2μ=R(x(i),x)∑i=1nω(i)=1(10)
上式写成矩阵形式为:
[
R
F
F
T
0
]
[
ω
μ
^
]
=
[
r
1
]
(11)
\begin{bmatrix}\mathbf R & \mathbf F \\ \mathbf F^T & 0 \end{bmatrix} \begin {bmatrix}\boldsymbol \omega \\ \hat{\mu} \end {bmatrix}=\begin{bmatrix}\mathbf r \\ 1\end{bmatrix} \tag{11}
[RFTF0][ωμ^]=[r1](11)
上式中:
F
=
[
1
1
.
.
.
1
]
T
∈
R
n
μ
^
=
μ
/
(
2
σ
2
)
R
=
[
R
(
x
(
1
)
,
x
(
1
)
)
.
.
.
R
(
x
(
1
)
,
x
(
n
)
)
⋮
⋮
R
(
x
(
n
)
,
x
(
1
)
.
.
.
R
(
x
(
n
)
,
x
(
n
)
)
]
∈
R
n
×
n
r
=
[
R
(
x
(
1
)
,
x
)
⋮
R
(
x
(
n
)
,
x
)
]
∈
R
n
(12)
\begin {align} &\mathbf F=[1 \ \ 1 \ \ ... \ \ 1]^T\in\R^n \\ &\hat \mu=\mu/(2\sigma^2) \\ &\mathbf R= \begin{bmatrix} R(\mathbf x^{(1)},\mathbf x^{(1)}) \ \ ... \ \ R(\mathbf x^{(1)},\mathbf x^{(n)}) \\ \ \ \ \ \ \ \ \ \ \ \ \vdots \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \vdots \\ R(\mathbf x^{(n)},\mathbf x^{(1)} \ \ ... \ \ R(\mathbf x^{(n)},\mathbf x^{(n)})\end{bmatrix} \in \R^{n \times n} \\ &\mathbf r=\begin{bmatrix}R(\mathbf x^{(1)},\mathbf x) \\ \vdots \\ R(\mathbf x^{(n)},\mathbf x) \end {bmatrix} \in \R^n \end {align}\tag{12}
F=[1 1 ... 1]T∈Rnμ^=μ/(2σ2)R=
R(x(1),x(1)) ... R(x(1),x(n)) ⋮ ⋮R(x(n),x(1) ... R(x(n),x(n))
∈Rn×nr=
R(x(1),x)⋮R(x(n),x)
∈Rn(12)
则:
[
ω
μ
^
]
=
[
R
F
F
T
0
]
−
1
[
r
1
]
(13)
\begin {bmatrix} \boldsymbol \omega \\ \hat \mu\end {bmatrix}=\begin {bmatrix} \mathbf R & \mathbf F \\ \mathbf F^T & 0\end {bmatrix}^{-1}\begin {bmatrix} \mathbf r \\ 1\end {bmatrix} \tag{13}
[ωμ^]=[RFTF0]−1[r1](13)
其中
[
R
F
F
T
0
]
\begin {bmatrix} \mathbf R & \mathbf F \\ \mathbf F^T & 0\end {bmatrix}
[RFTF0] 为对称矩阵,那么:
[
ω
μ
^
]
T
=
[
ω
T
μ
^
]
=
[
r
1
]
T
[
R
F
F
T
0
]
−
1
(14)
\begin {bmatrix} \boldsymbol \omega \\ \hat \mu\end {bmatrix}^T = \begin {bmatrix}\boldsymbol \omega^T &\hat \mu \end {bmatrix} = \begin {bmatrix} \mathbf r \\ 1\end {bmatrix}^T \begin {bmatrix} \mathbf R & \mathbf F \\ \mathbf F^T & 0\end {bmatrix}^{-1} \tag{14}
[ωμ^]T=[ωTμ^]=[r1]T[RFTF0]−1(14)
其中:
R
\mathbf R
R 为相关矩阵,由所有已知样本点之间的相关函数值组成,
r
\mathbf r
r 为相关矢量,由未知点与所有已知样本点之间的相关函数值组成。联立式 (3) 和式 (11)可得:
y
^
(
x
)
=
[
ω
T
μ
^
]
[
y
s
0
]
=
[
r
(
x
)
1
]
T
[
R
F
F
T
0
]
−
1
[
y
s
0
]
(15)
\hat y(\mathbf x)=\begin{bmatrix} \boldsymbol \omega^T & \hat \mu \end {bmatrix}\begin {bmatrix} \mathbf y_s \\ 0\end {bmatrix} =\begin {bmatrix} \mathbf r(\mathbf x) \\ 1\end {bmatrix}^T\begin{bmatrix} \mathbf R &\mathbf F \\ \mathbf F^T & 0 \end {bmatrix}^{-1} \begin{bmatrix} \mathbf y_s \\ 0\end {bmatrix} \tag{15}
y^(x)=[ωTμ^][ys0]=[r(x)1]T[RFTF0]−1[ys0](15)
由分块矩阵求逆公式:设
A
\mathbf A
A 是
m
×
m
m \times m
m×m 可逆矩阵,
B
\mathbf B
B 是
m
×
n
m \times n
m×n 矩阵,
C
\mathbf C
C 是
n
×
m
n \times m
n×m 矩阵,
D
\mathbf D
D 是
n
×
n
n \times n
n×n 可逆矩阵,则有:
[
A
B
C
D
]
−
1
=
[
A
−
1
+
A
−
1
B
(
D
−
C
A
−
1
B
)
−
1
C
A
−
1
−
A
−
1
B
(
D
−
C
A
−
1
B
)
−
1
−
(
D
−
C
A
−
1
B
)
−
1
C
A
−
1
(
D
−
C
A
−
1
B
)
−
1
]
(16)
\begin {bmatrix} \mathbf A & \mathbf B \\ \mathbf C & \mathbf D \end {bmatrix}^{-1}=\begin {bmatrix} \mathbf A^{-1}+\mathbf A^{-1}\mathbf B(\mathbf D-\mathbf C\mathbf A^{-1}\mathbf B)^{-1}\mathbf C \mathbf A^{-1} & - \mathbf A^{-1}\mathbf B(\mathbf D -\mathbf C\mathbf A^{-1} \mathbf B)^{-1} \\ -(\mathbf D-\mathbf C \mathbf A^{-1}\mathbf B)^{-1} \mathbf C\mathbf A^{-1} & (\mathbf D- \mathbf C\mathbf A^{-1}\mathbf B)^{-1}\end {bmatrix} \tag{16}
[ACBD]−1=[A−1+A−1B(D−CA−1B)−1CA−1−(D−CA−1B)−1CA−1−A−1B(D−CA−1B)−1(D−CA−1B)−1](16)
可得:
[
R
F
F
T
0
]
−
1
=
[
R
−
1
−
R
−
1
F
(
F
T
R
−
1
F
)
−
1
F
T
R
−
1
R
−
1
F
(
F
T
R
−
1
F
)
−
1
(
F
T
R
−
1
F
)
−
1
F
T
R
−
1
−
(
F
T
R
−
1
F
)
−
1
]
(17)
\begin {bmatrix} \mathbf R & \mathbf F \\ \mathbf F ^T & 0\end {bmatrix} ^{-1} = \begin{bmatrix} \mathbf R^{-1}-\mathbf R^{-1}\mathbf F(\mathbf F^T \mathbf R^{-1}\mathbf F)^{-1}\mathbf F^{T}\mathbf R^{-1} & \mathbf R^{-1} \mathbf F(\mathbf F^T \mathbf R^{-1} \mathbf F)^{-1} \\ (\mathbf F^T \mathbf R^{-1} \mathbf F)^{-1}\mathbf F^T\mathbf R^{-1} & -(\mathbf F^T\mathbf R^{-1} \mathbf F)^{-1}\end {bmatrix} \tag{17}
[RFTF0]−1=[R−1−R−1F(FTR−1F)−1FTR−1(FTR−1F)−1FTR−1R−1F(FTR−1F)−1−(FTR−1F)−1](17)
代入式 (15) 并化简可得:
y
^
(
x
)
=
[
r
T
R
−
1
−
r
T
R
−
1
F
(
F
T
R
−
1
F
)
−
1
F
T
R
−
1
+
(
F
T
R
−
1
F
)
−
1
F
T
R
−
1
]
y
s
(18)
\hat y(\mathbf x) = [\mathbf r^T\mathbf R^{-1} - \mathbf r^T \mathbf R ^{-1}\mathbf F(\mathbf F^T\mathbf R^{-1}\mathbf F)^{-1}\mathbf F^T\mathbf R^{-1} +(\mathbf F^T\mathbf R^{-1}\mathbf F)^{-1}\mathbf F^T \mathbf R^{-1}]\mathbf y_s \tag{18}
y^(x)=[rTR−1−rTR−1F(FTR−1F)−1FTR−1+(FTR−1F)−1FTR−1]ys(18)
令
β
0
=
(
F
T
R
−
1
F
)
−
1
F
T
R
−
1
y
s
\beta _0 = (\mathbf F^T\mathbf R^{-1}\mathbf F)^{-1}\mathbf F^T \mathbf R^{-1}\mathbf y_s
β0=(FTR−1F)−1FTR−1ys,则有:
y
^
(
x
)
=
β
0
+
r
T
R
−
1
(
y
s
−
β
0
F
)
(19)
\hat y(\mathbf x) = \beta_0 + \mathbf r^T \mathbf R^{-1}(\mathbf y_s - \beta_0 \mathbf F) \tag{19}
y^(x)=β0+rTR−1(ys−β0F)(19)
令列向量
V
k
r
i
g
=
R
−
1
(
y
s
−
β
0
F
)
\mathbf V_{krig}=\mathbf R^{-1}(\mathbf y_s -\beta_0 \mathbf F)
Vkrig=R−1(ys−β0F) ,则
β
0
\beta_0
β0 和
V
k
r
i
g
\mathbf V_{krig}
Vkrig 都只与已知样本点有关,可以在模型训练结束后一次性计算并存储。之后,预测任意
x
\mathbf x
x 处的响应值只需要计算
r
(
x
)
\mathbf r(\mathbf x)
r(x) 与
V
k
r
i
g
\mathbf V_{krig}
Vkrig 间的点乘。
Kriging模型给出的预估值的均方差为:
M
S
E
[
y
^
(
x
)
]
=
E
[
(
ω
T
Y
s
−
Y
(
x
)
)
2
]
=
E
[
(
ω
T
Y
s
−
Y
(
x
)
)
(
ω
T
Y
s
−
Y
(
x
)
)
]
=
σ
2
(
ω
T
R
ω
−
2
ω
T
r
+
1
)
=
σ
2
[
ω
T
(
R
ω
+
F
μ
^
)
−
ω
T
F
μ
^
−
2
ω
T
r
+
1
]
=
σ
2
[
ω
T
r
−
μ
^
−
2
ω
T
r
+
1
]
=
σ
2
[
1
−
ω
T
r
−
μ
^
]
=
σ
2
[
1
−
[
ω
T
μ
^
]
[
r
1
]
]
=
σ
2
[
1
−
[
r
1
]
T
[
R
F
F
T
0
]
−
1
[
r
1
]
]
=
σ
2
[
1
−
r
T
R
−
1
r
+
(
1
−
F
T
R
−
1
r
)
2
/
(
F
T
R
−
1
F
)
]
(20)
\begin {align} MSE[\hat y(\mathbf x)] & =E[(\boldsymbol \omega ^T\mathbf Y_s-\mathbf Y(\mathbf x))^2]\\ & =E[(\boldsymbol \omega ^T\mathbf Y_s-\mathbf Y(\mathbf x))(\boldsymbol \omega ^T\mathbf Y_s-\mathbf Y(\mathbf x))]\\ & = \sigma ^2(\boldsymbol \omega^T\mathbf R \boldsymbol \omega - 2\boldsymbol \omega^T\mathbf r + 1) \\ & =\sigma^2[\boldsymbol \omega^T(\mathbf R\boldsymbol \omega+\mathbf F\hat \mu)-\boldsymbol \omega^T\mathbf F\hat \mu - 2\boldsymbol \omega^T\mathbf r + 1] \\ & = \sigma ^2[\boldsymbol \omega^T\mathbf r-\hat\mu-2\boldsymbol \omega^T\mathbf r + 1] \\ & =\sigma ^2[1-\boldsymbol \omega^T \mathbf r-\hat\mu] \\ &=\sigma ^2[1-[\boldsymbol \omega ^T \ \ \hat \mu]\begin {bmatrix}\mathbf r \\ 1 \end {bmatrix}]\\&= \sigma ^2[1-\begin {bmatrix} \mathbf r \\ 1\end {bmatrix}^T\begin{bmatrix} \mathbf R &\mathbf F \\ \mathbf F^T & 0 \end {bmatrix}^{-1}\begin {bmatrix}\mathbf r \\ 1 \end {bmatrix}] \\ &=\sigma^2[1-\mathbf r^T\mathbf R^{-1}\mathbf r +(1-\mathbf F^T\mathbf R^{-1}\mathbf r)^2/(\mathbf F^T\mathbf R^{-1}\mathbf F)] \end {align} \tag {20}
MSE[y^(x)]=E[(ωTYs−Y(x))2]=E[(ωTYs−Y(x))(ωTYs−Y(x))]=σ2(ωTRω−2ωTr+1)=σ2[ωT(Rω+Fμ^)−ωTFμ^−2ωTr+1]=σ2[ωTr−μ^−2ωTr+1]=σ2[1−ωTr−μ^]=σ2[1−[ωT μ^][r1]]=σ2[1−[r1]T[RFTF0]−1[r1]]=σ2[1−rTR−1r+(1−FTR−1r)2/(FTR−1F)](20)
上述均方差可用于指导加入新样本点,以提高代理模型精度或逼近优化问题的最优解。
1.3 相关函数
在式 (19) 所示Kriging模型表达式中,相关矩阵 R \mathbf R R 和相关矢量 r \mathbf r r 构造涉及相关函数的选择和计算。下表为常用的相关函数:
| 相关函数 | R ( x − x ′ ) \mathbf R(\mathbf x - \mathbf x') R(x−x′) |
|---|---|
| Exponential function | R ( x , x ′ ) = e x p { − ∑ i = 1 m θ i / ∣ x i − x i ′ ∣ } \mathbf R(\mathbf x , \mathbf x')=exp\{-\sum_{i=1}^m\theta_i/ \lvert {x_i -x_i'} \rvert \} R(x,x′)=exp{−∑i=1mθi/∣xi−xi′∣} |
| Power function | R ( x , x ′ ) = e x p { − ∑ i = 1 m θ i / ( x i − x i ′ ) 2 } \mathbf R(\mathbf x , \mathbf x')=exp\{-\sum_{i=1}^m\theta_i/(x_i-x_i')^2\} R(x,x′)=exp{−∑i=1mθi/(xi−xi′)2} |
| Gaussian function | R ( x , x ′ ) = e x p { − ∑ i = 1 m θ i ( x i − x i ′ ) p i } \mathbf R(\mathbf x , \mathbf x')=exp\{-\sum_{i=1}^m\theta_i(x_i-x_i')^{p_i}\} R(x,x′)=exp{−∑i=1mθi(xi−xi′)pi} |
| Linear function | R ( x , x ′ ) = m a x { 0 , 1 − ∑ i = 1 m θ i / ∣ x i − x i ′ ∣ } \mathbf R(\mathbf x , \mathbf x')=max\{0,1-\sum_{i=1}^m\theta_i/ \lvert x_i-x_i' \rvert \} R(x,x′)=max{0,1−∑i=1mθi/∣xi−xi′∣} |
| Ball function | R ( x , x ′ ) = 1 − 1.5 ζ + 0.5 ζ 3 , ζ = m i n { 1 , ∑ i = 1 m θ i ∣ x i − x i ′ ∣ } \mathbf R (\mathbf x,\mathbf x')=1-1.5\zeta+0.5 \zeta ^3, \\ \zeta=min\{ 1,\sum_{i=1}^m\theta_i \lvert x_i-x_i' \rvert \} R(x,x′)=1−1.5ζ+0.5ζ3,ζ=min{1,∑i=1mθi∣xi−xi′∣} |
| Spline function | R ( x , x ′ ) = { 1 − 15 ( ∑ i = 1 m θ i ∣ x i − x i ′ ∣ ) 2 + 30 ( ∑ i = 1 m θ i ∣ x i − x i ′ ∣ ) 3 0 ≤ ∑ i = 1 m θ i ∣ x i − x i ′ ∣ ≤ 0.2 1.25 ( 1 − ( ∑ i = 1 m θ i ∣ x i − x i ′ ∣ ) 3 ) 0.2 ≤ ∑ i = 1 m θ i ∣ x i − x i ′ ∣ ≤ 1 0 ∑ i = 1 m θ i ∣ x i − x i ′ ∣ ≥ 1 \mathbf R(\mathbf x , \mathbf x')=\begin {cases}1-15(\sum_{i=1}^m \theta_i \lvert x_i-x_i' \rvert )^2+30(\sum_{i=1}^m \theta_i \lvert x_i-x_i' \rvert )^3 \ \ \ \ \ \ \ \ \ \ \ \ \ \ 0\leq\sum_{i=1}^m \theta_i \lvert x_i-x_i' \rvert \leq0.2 \\ 1.25(1-(\sum_{i=1}^m\theta_i \lvert x_i-x_i' \rvert)^3) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 0.2\leq\sum_{i=1}^m\theta_i \lvert x_i-x_i' \rvert \leq 1 \\ 0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^m\theta_i \lvert x_i-x_i' \rvert \ge1 \end {cases} R(x,x′)=⎩ ⎨ ⎧1−15(∑i=1mθi∣xi−xi′∣)2+30(∑i=1mθi∣xi−xi′∣)3 0≤∑i=1mθi∣xi−xi′∣≤0.21.25(1−(∑i=1mθi∣xi−xi′∣)3) 0.2≤∑i=1mθi∣xi−xi′∣≤10 ∑i=1mθi∣xi−xi′∣≥1 |
对于高斯指数模型,参数 p = [ p 1 p 2 … p m ] T ∈ R m \mathbf p=[p_1 \ \ p_2 \ \ \ldots \ \ p_m]^T \in\R^m p=[p1 p2 … pm]T∈Rm 是决定相关函数光滑程度的各向异性参数: p i = 2 p_i = 2 pi=2 时,相关函数具有全局性,且无穷阶可导; p i < 2 p_i \lt 2 pi<2时,相关函数仅一阶可导。最初人们直接采用 p i = 2 p_i = 2 pi=2 ,虽然能获得非常光滑的插值结果,但由于相关矩阵条件数大,容易出现奇异性,导致不稳定,之后将 p i p_i pi 也作为模型参数进行优化,从而提高了Kriging模型的鲁棒性。有些研究者作了进一步简化,令各方向的指数相同,即各向同性 p i = p , i = 1 , 2 , … , m p_i=p,i=1,2,\ldots,m pi=p,i=1,2,…,m ,从而减少了待定模型参数,据说预测精度与简化前相当。
三次样条函数二阶可导,在光滑性和鲁棒性方面取得很好的折中。
1.4 模型参数训练
建立Kriging模型时,可以对其模型参数(也称为超参数)进行训练,可以大大增强代理模型的灵活性。一般采用“最大似然估计”或“交叉验证”。这里以最大似然估计为例进行说明,由前述引入的高斯静态随机过程的假设,在任意一点
x
\mathbf x
x 处的响应值
y
^
(
x
)
\hat y(\mathbf x)
y^(x) 服从正态分布
N
(
β
0
,
σ
2
)
N(\beta_0,\sigma^2)
N(β0,σ2) ,则每个样本点处的概率密度函数为:
P
[
Y
(
x
)
]
=
1
2
π
σ
e
x
p
(
−
(
y
(
i
)
−
β
0
)
2
2
σ
2
)
,
i
=
1
,
…
,
n
(21)
P[Y(\mathbf x)]= \frac {1}{\sqrt{2\pi}\sigma}exp\left( -\frac{(y^{(i)}-\beta_0)^2}{2\sigma^2} \right),i=1, \ldots,n \tag{21}
P[Y(x)]=2πσ1exp(−2σ2(y(i)−β0)2),i=1,…,n(21)
则所有样本点的联合分布密度(即似然函数)为:
L
~
(
β
0
,
σ
2
,
θ
,
p
)
=
1
(
2
π
σ
2
)
n
∣
R
∣
⋅
e
x
p
(
−
1
2
(
y
s
−
β
0
F
)
T
R
−
1
(
y
s
−
β
0
F
)
σ
2
)
(22)
\widetilde L(\beta_0,\sigma^2,\boldsymbol \theta,\mathbf p)=\frac{1}{\sqrt {(2\pi\sigma^2)^n|\mathbf R|}}\cdot exp(-\frac{1}{2}\frac {(\mathbf y_s-\beta_0\mathbf F)^T\mathbf R^{-1}(\mathbf y_s-\beta_0\mathbf F)}{\sigma^2}) \tag{22}
L
(β0,σ2,θ,p)=(2πσ2)n∣R∣1⋅exp(−21σ2(ys−β0F)TR−1(ys−β0F))(22)
上式中,超参数
p
\mathbf p
p 仅针对高斯指数函数才存在。对上式两边取对数有:
l
n
L
~
=
−
1
2
(
y
s
−
β
0
F
)
T
R
−
1
(
y
s
−
β
0
F
)
σ
2
−
n
2
l
n
(
σ
2
)
−
1
2
l
n
∣
R
∣
−
n
2
l
n
(
2
π
)
(23)
ln \ \ \widetilde L=-\frac {1}{2} \frac {\mathbf (\mathbf y_s-\beta_0\mathbf F)^T\mathbf R^{-1}(\mathbf y_s-\beta_0\mathbf F)}{\sigma^2} - \frac{n}{2}ln(\sigma^2) - \frac {1}{2}ln|\mathbf R|- \frac{n}{2}ln(2\pi)\tag{23}
ln L
=−21σ2(ys−β0F)TR−1(ys−β0F)−2nln(σ2)−21ln∣R∣−2nln(2π)(23)
要使似然函数最大,令:
{
∂
l
n
L
~
∂
β
0
=
1
2
σ
2
[
F
T
R
−
1
(
y
s
−
β
0
F
)
+
(
y
s
−
β
0
F
)
T
R
−
1
F
]
=
1
2
σ
2
2
F
T
R
−
1
(
y
s
−
β
0
F
)
=
0
∂
l
n
L
~
σ
2
=
1
2
(
y
s
−
β
0
F
)
T
R
−
1
(
y
s
−
β
0
F
)
(
σ
2
)
2
−
n
2
1
σ
2
=
0
(24)
\begin {cases} \frac {\partial \ ln \widetilde L}{\partial \beta_0}=\frac {1}{2\sigma^2}[\mathbf F^T\mathbf R^{-1}(\mathbf y_s - \beta_0 \mathbf F) + (\mathbf y_s - \beta_0\mathbf F)^T\mathbf R^{-1}\mathbf F] = \frac {1}{2\sigma^2}2\mathbf F^T\mathbf R^{-1}(\mathbf y_s-\beta_0 \mathbf F)=0\\ \frac {\partial \ ln\widetilde L}{\sigma^2}=\frac {1}{2} \frac {(\mathbf y_s-\beta_0 \mathbf F)^T\mathbf R^{-1}(\mathbf y_s-\beta_0 \mathbf F)}{(\sigma^2)^2}-\frac {n}{2}\frac {1}{\sigma^2}=0 \end {cases} \tag{24}
{∂β0∂ lnL
=2σ21[FTR−1(ys−β0F)+(ys−β0F)TR−1F]=2σ212FTR−1(ys−β0F)=0σ2∂ lnL
=21(σ2)2(ys−β0F)TR−1(ys−β0F)−2nσ21=0(24)
解得:
{
β
0
(
θ
,
p
)
=
(
F
T
R
−
1
F
)
−
1
F
T
R
−
1
y
s
σ
2
(
β
0
,
θ
,
p
)
=
1
n
(
y
s
−
β
0
F
)
T
R
−
1
(
y
s
−
β
0
F
)
(25)
\begin {cases}\beta_0(\boldsymbol \theta,\mathbf p)= (\mathbf F^T\mathbf R^{-1}\mathbf F)^{-1}\mathbf F^T\mathbf R^{-1}\mathbf y_s\\ \sigma^2(\beta_0,\boldsymbol \theta,\mathbf p)=\frac {1}{n}(\mathbf y_s-\beta_0\mathbf F)^T\mathbf R^{-1}(\mathbf y_s-\beta_0\mathbf F)\end {cases} \tag{25}
{β0(θ,p)=(FTR−1F)−1FTR−1ysσ2(β0,θ,p)=n1(ys−β0F)TR−1(ys−β0F)(25)
将式 (25) 代入式 (23) 并忽略常数项,则最大似然函数估计是让下式最大:
l
n
L
~
=
−
n
2
l
n
σ
2
−
1
2
l
n
∣
R
∣
(26)
ln \ \ \widetilde L = -\frac {n}{2}ln\sigma^2-\frac{1}{2}ln|\mathbf R| \tag{26}
ln L
=−2nlnσ2−21ln∣R∣(26)
由于无法解析地求出
θ
\boldsymbol \theta
θ 和
p
\mathbf p
p 的最优值,需要采用数值优化算法寻优,如梯度优化算法等。
1.5 优化加点准则
建立初始代理模型后,下一步是通过一定的加点准则循环选择新的样本点,直到优化收敛。“优化加点准则”是指如何由建立的代理模型去指导产生新的样本点的规则。以最小化优化问题为例 ,这里对最小化代理模型预测准则(MSP)、改善期望准则(EI)、改善概率准则(PI)、均方差准则(MSE)、置信下界准则(LCB)五种常用加点准则进行介绍。
1.5.1 最小化代理模型预测准则(MSP)
最小化代理模型预测准则的原理是直接在代理模型上寻找目标函数的最小值,其带约束子优化问题(子优化问题指由加点准则确定的优化问题)的数学模型为:
m
i
n
y
^
(
x
)
s
.
t
.
{
g
^
i
(
x
)
≤
0
i
=
1
,
2
,
…
,
N
c
x
l
≤
x
≤
x
u
(27)
\begin {align} & min \ \ \hat y(\mathbf x) \\ & s.t. \begin{cases}\hat g_i(\mathbf x)\leq0 \ \ \ i=1,2,\ldots, N_c \\ \mathbf x_l \leq \mathbf x \leq \mathbf x_u\end {cases} \end {align} \tag{27}
min y^(x)s.t.{g^i(x)≤0 i=1,2,…,Ncxl≤x≤xu(27)
上式中,
y
^
(
x
)
\hat y(\mathbf x)
y^(x) 和
g
^
i
(
x
)
\hat g_i(\mathbf x)
g^i(x) 分别为目标函数和约束函数的代理模型。采用梯度优化算法、遗传算法等求解上述子优化问题,可以得到代理模型上预测的目标函数最优解
x
∗
\mathbf x^*
x∗ 。
1.5.2 改善期望准则(EI)
改善期望准则也称为高效全局优化(EGO)方法,记当前已知样本点所取得的最优目标函数值
y
m
i
n
y_{min}
ymin ,并假设Kriging模型预测服从均值为
y
^
(
x
)
\hat y(\mathbf x)
y^(x) 、标准差为
s
(
x
)
s(\mathbf x)
s(x) 的正态分布,
Y
^
(
x
)
∈
N
[
y
^
(
x
)
,
s
2
]
\hat Y(\mathbf x) \in N[\hat y(\mathbf x),s^2]
Y^(x)∈N[y^(x),s2] ,则其概率密度为:
P
d
f
(
Y
^
(
x
)
)
=
1
2
π
s
(
x
)
e
x
p
(
−
1
2
(
Y
^
(
x
)
−
y
^
(
x
)
s
(
x
)
)
2
)
(28)
Pdf(\hat Y(\mathbf x))=\frac {1}{\sqrt {2\pi}s(\mathbf x)}exp(-\frac {1}{2}(\frac{\hat Y(\mathbf x)-\hat y(\mathbf x)}{s(\mathbf x)})^2) \tag{28}
Pdf(Y^(x))=2πs(x)1exp(−21(s(x)Y^(x)−y^(x))2)(28)
对于最小化问题,目标函数改善量
I
(
x
)
I(\mathbf x)
I(x)定义为:
I
=
m
a
x
(
y
m
i
n
−
Y
^
(
x
)
,
0
)
(29)
I=max(y_{min}-\hat Y(\mathbf x), 0) \tag{29}
I=max(ymin−Y^(x),0)(29)
则
I
(
x
)
I(\mathbf x)
I(x) 的期望值为:
∫
−
∞
y
m
i
n
P
d
f
⋅
I
=
∫
−
∞
y
m
i
n
1
2
π
s
e
x
p
(
−
1
2
(
Y
^
−
y
^
s
)
2
)
⋅
(
y
m
i
n
−
Y
^
)
d
Y
^
=
∫
−
∞
y
m
i
n
1
2
π
s
e
x
p
(
−
1
2
(
Y
^
−
y
^
s
)
2
)
⋅
y
m
i
n
d
Y
^
−
∫
−
∞
y
m
i
n
1
2
π
s
e
x
p
(
−
1
2
(
Y
^
−
y
^
s
)
2
)
⋅
Y
^
d
Y
^
=
∫
−
∞
y
m
i
n
1
2
π
e
x
p
(
−
1
2
(
Y
^
−
y
^
s
)
2
)
⋅
y
m
i
n
d
(
Y
^
−
y
^
s
)
+
s
2
π
∫
−
∞
y
m
i
n
d
(
e
x
p
−
1
2
(
Y
^
−
y
^
s
)
)
−
1
2
π
s
∫
∞
y
m
i
n
y
^
e
x
p
(
−
(
Y
^
−
y
^
s
)
2
)
d
Y
^
=
(
y
m
i
n
−
y
^
)
Φ
(
y
m
i
n
−
y
^
s
)
+
s
ϕ
(
y
m
i
n
−
y
^
s
)
(30)
\begin {align}\int_{- \infty}^{y_{min}}Pdf \ \cdot \ I &=\int_{-\infty} ^{y_{min}}\frac {1}{\sqrt {2\pi}s}exp(-\frac {1}{2}(\frac{\hat Y-\hat y}{s})^2) \ \cdot \ (y_{min}-\hat Y)d\hat Y \\ & = \int_{-\infty}^{y_{min}} \frac {1}{\sqrt {2 \pi}s}exp(-\frac {1}{2}(\frac {\hat Y-\hat y}{s})^2) \ \cdot \ y_{min}d\hat Y -\int_{-\infty}^{y_{min}}\frac {1}{\sqrt {2\pi}s}exp(-\frac {1}{2}(\frac {\hat Y-\hat y}{s})^2) \ \cdot \ \hat Y d\hat Y \\ & = \int_{-\infty}^{y_{min}} \frac {1}{\sqrt {2 \pi}}exp(-\frac {1}{2}(\frac {\hat Y-\hat y}{s})^2) \ \cdot \ y_{min}d(\frac {\hat Y-\hat y}{s}) +\frac {s}{\sqrt {2 \pi}} \int_{-\infty}^{y_{min}}d(exp^{-\frac {1}{2} (\frac{\hat Y-\hat y}{s})}) - \frac {1}{\sqrt {2\pi}s} \int_{\infty}^{y_{min}}\hat y \ exp(-(\frac{\hat Y -\hat y}{s})^2)d \hat Y \\ & =(y_{min}-\hat y) \Phi (\frac {y_{min}-\hat y}{s})+s\phi(\frac {y_{min}-\hat y}{s}) \end{align} \tag{30}
∫−∞yminPdf ⋅ I=∫−∞ymin2πs1exp(−21(sY^−y^)2) ⋅ (ymin−Y^)dY^=∫−∞ymin2πs1exp(−21(sY^−y^)2) ⋅ ymindY^−∫−∞ymin2πs1exp(−21(sY^−y^)2) ⋅ Y^dY^=∫−∞ymin2π1exp(−21(sY^−y^)2) ⋅ ymind(sY^−y^)+2πs∫−∞ymind(exp−21(sY^−y^))−2πs1∫∞yminy^ exp(−(sY^−y^)2)dY^=(ymin−y^)Φ(symin−y^)+sϕ(symin−y^)(30)
上式中,
Φ
\Phi
Φ 和
ϕ
\phi
ϕ 分别为标准正态分布累积分布函数和标准正态分布概率密度函数。上式可简化为:
E
[
I
(
x
)
]
=
{
(
y
m
i
n
−
y
^
)
Φ
(
y
m
i
n
−
y
^
s
)
+
s
ϕ
(
y
m
i
n
−
y
^
s
)
s
>
0
0
s
=
0
(31)
E[I(\mathbf x)]=\begin {cases} (y_{min}-\hat y) \Phi (\frac {y_{min}-\hat y}{s})+s\phi(\frac {y_{min}-\hat y}{s}) \ \ \ s>0 \\ 0 \ \ \ \ \ \ \ \ \ \ \ s=0 \end {cases} \tag{31}
E[I(x)]={(ymin−y^)Φ(symin−y^)+sϕ(symin−y^) s>00 s=0(31)
通过求解最大化 EI 值的子优化问题:
M
a
x
E
[
I
(
x
)
]
s
.
t
.
x
l
≤
x
≤
x
u
(32)
\begin {align} & Max \ \ E[I(\mathbf x)] \\ & s.t. \ \ \ \ \mathbf x_l \leq \mathbf x \leq \mathbf x_u \end {align} \tag{32}
Max E[I(x)]s.t. xl≤x≤xu(32)
从而可以得到新的样本点
x
∗
\mathbf x^*
x∗ 。
当优化存在约束
g
i
(
x
)
≤
0
,
i
=
1
,
2
,
…
,
N
c
g_i(\mathbf x) \leq 0,i=1,2, \ldots,N_c
gi(x)≤0,i=1,2,…,Nc 时,对
g
i
(
x
)
g_i(\mathbf x)
gi(x) 也需要分别建立Kriging模型,并也假定其对应的随机变量
G
i
(
x
)
G_i(\mathbf x)
Gi(x) 服从均值为
g
i
(
x
)
g_i(\mathbf x)
gi(x) 、标准差为
s
g
,
i
(
x
)
s_{g,i}(\mathbf x)
sg,i(x) 的正态分布,即
G
i
(
x
)
∈
N
[
g
^
i
(
x
)
,
s
^
g
,
i
2
(
x
)
]
G_i(\mathbf x)\in N[\hat g_i(\mathbf x),\hat s_{g,i}^2(\mathbf x)]
Gi(x)∈N[g^i(x),s^g,i2(x)] ,其中
g
i
(
x
)
g_i(\mathbf x)
gi(x) 为 Kriging 模型预估值,
s
^
g
,
i
2
(
x
)
\hat s_{g,i}^2(\mathbf x)
s^g,i2(x) 为预估值的方差,那么任意点
x
\mathbf x
x 位置处满足约束的概率为:
P
[
G
i
(
x
)
≤
0
]
=
Φ
(
−
g
^
i
(
x
)
s
g
,
i
(
x
)
)
(33)
P[G_i(\mathbf x)\leq0]=\Phi (-\frac{\hat g_i(\mathbf x)}{s_{g,i}(\mathbf x)}) \tag{33}
P[Gi(x)≤0]=Φ(−sg,i(x)g^i(x))(33)
于是可以得到约束 EI 值:
E
c
[
I
(
x
)
]
=
E
[
I
(
x
)
⋂
G
i
≤
0
]
=
E
[
I
(
x
)
]
⋅
∏
i
=
1
N
c
P
(
G
i
≤
0
)
(34)
E_c[I(\mathbf x)]=E[I(\mathbf x)\bigcap G_i \leq 0]=E[I(\mathbf x)]\cdot \prod_{i=1}^{N_c}P(G_i\leq 0) \tag{34}
Ec[I(x)]=E[I(x)⋂Gi≤0]=E[I(x)]⋅i=1∏NcP(Gi≤0)(34)
在约束存在时,求解下述无约束子优化问题:
M
a
x
E
[
I
(
x
)
]
⋅
∏
i
=
1
N
c
P
[
G
i
≤
0
]
s
.
t
.
x
l
≤
x
≤
x
u
(35)
\begin {align} & Max \ E[I(\mathbf x)] \ \cdot \prod_{i=1}^{N_c}P[G_i\leq 0] \\ & s.t. \ \ \mathbf x_l\leq\mathbf x\leq \mathbf x_u \end {align} \tag{35}
Max E[I(x)] ⋅i=1∏NcP[Gi≤0]s.t. xl≤x≤xu(35)
从而得到新的样本点
x
∗
x^*
x∗。
1.5.3 改善概率准则(PI)
改善概率准则方法是 EI 方法的派生方法,与 EI 准则类似,该准则通过计算目标函数改善的概率,并将改善概率最大点作为新的样本点。
目标函数改善的概率为:
P
[
I
(
x
)
]
=
Φ
(
y
m
i
n
−
y
^
(
x
)
s
(
x
)
)
(36)
P[I(\mathbf x)]=\Phi(\frac {y_{min}-\hat y(\mathbf x)}{s(\mathbf x)}) \tag{36}
P[I(x)]=Φ(s(x)ymin−y^(x))(36)
通过求解最大化 PI 值的子优化问题:
M
a
x
P
[
I
(
x
)
]
s
.
t
.
x
l
≤
x
≤
x
u
(37)
\begin {align} & Max \ \ P[I(\mathbf x)] \\ & s.t. \ \ \ \ \mathbf x_l \leq \mathbf x \leq \mathbf x_u \end {align} \tag{37}
Max P[I(x)]s.t. xl≤x≤xu(37)
从而可以得到新的样本点
x
∗
\mathbf x^*
x∗ 。
对于约束优化问题,可以采用与约束 EI 类似的方法进行处理,即求解下面的子优化问题:
M
a
x
P
[
I
(
x
)
]
⋅
∏
i
=
1
N
c
P
[
G
i
≤
0
]
s
.
t
.
x
l
≤
x
≤
x
u
(38)
\begin {align} & Max \ P[I(\mathbf x)] \ \cdot \ \prod_{i=1}^{N_c}P[G_i\leq 0] \\ &s.t. \ \ \mathbf x_l\leq\mathbf x\leq \mathbf x_u\end {align} \tag{38}
Max P[I(x)] ⋅ i=1∏NcP[Gi≤0]s.t. xl≤x≤xu(38)
得到新的样本点
x
∗
\mathbf x^*
x∗ 。
1.5.4 均方差准则(MSE)
均方差准则是直接采用Kriging模型提供的均方差估计来改善代理模型全局精度的一种加点准则,即采用子优化算法求解下述子优化问题:
M
a
x
M
S
E
(
y
^
(
x
)
)
s
.
t
.
x
l
≤
x
≤
x
u
(39)
\begin {align} & Max \ \ MSE(\hat y(\mathbf x)) \\ & s.t. \ \ \mathbf x_l\leq \mathbf x \leq \mathbf x_u \end {align} \tag {39}
Max MSE(y^(x))s.t. xl≤x≤xu(39)
得到新的样本点
x
∗
\mathbf x^*
x∗ 。
对于带约束的问题,可以引入满足约束的概率,求解下面的子优化问题:
M
a
x
M
S
E
(
y
^
(
x
)
)
⋅
∏
i
=
1
N
c
P
[
G
i
≤
0
]
s
.
t
.
x
l
≤
x
≤
x
u
(40)
\begin {align} & Max \ \ MSE(\hat y(\mathbf x)) \cdot \prod_{i=1}^{N_c}P[G_i\leq0] \\ & s.t. \ \ \mathbf x_l \leq \mathbf x \leq \mathbf x_u \end {align} \tag{40}
Max MSE(y^(x))⋅i=1∏NcP[Gi≤0]s.t. xl≤x≤xu(40)
得到新的样本点
x
∗
\mathbf x^*
x∗ 。
1.5.5 置信下界准则(LCB)
置信下界准则方法是一种利用 Kriging 模型误差估计进行全局优化的加点准则。假设 Kriging 模型预测结果满足均值为
y
^
(
x
)
\hat y(\mathbf x)
y^(x) 、标准差为
s
(
x
)
s(\mathbf x)
s(x) 的正态分布。为了充分发掘目标函数在整个设计空间上的更小值,可将对 Kriging 模型预测的置信下界作为目标函数进行子优化,并将其最小值点作为新的样本点。LCB 函数定义为:
L
C
B
(
x
)
=
y
^
(
x
)
−
A
s
(
x
)
(41)
LCB(\mathbf x)=\hat y(\mathbf x)-As(\mathbf x) \tag{41}
LCB(x)=y^(x)−As(x)(41)
上式中,
A
A
A 为一个自定义常数。当
A
→
0
,
L
C
B
→
y
^
(
x
)
A\rightarrow 0,LCB\rightarrow\hat y(\mathbf x)
A→0,LCB→y^(x) ,该方法退化为 MSP 方法;当
A
→
∞
,
L
C
B
→
s
(
x
)
A\rightarrow \infty,LCB\rightarrow s(\mathbf x)
A→∞,LCB→s(x) ,该方法退化为 MSE
方法。该准则约束的处理与 MSP 准则类似,即求解下述子优化问题:
M
i
n
y
^
(
x
)
−
A
s
(
x
)
s
.
t
.
{
g
^
i
(
x
)
≤
0
i
=
1
,
2
,
…
,
N
c
x
l
≤
x
≤
x
u
(42)
\begin {align} & Min \ \ \hat y(\mathbf x) - As(\mathbf x) \\& s.t. \begin{cases}\hat g_i(\mathbf x)\leq0 \ \ \ i=1,2,\ldots, N_c \\ \mathbf x_l \leq \mathbf x \leq \mathbf x_u\end {cases} \end {align} \tag{42}
Min y^(x)−As(x)s.t.{g^i(x)≤0 i=1,2,…,Ncxl≤x≤xu(42)
参考文献
[1] HAN Z H. Kriging Surrogate Model and its Application to Design Optimization: A Review of Recent Progress[J]. Acta Aeronauticaet Astronautica Sinica, 2016, 37(11): 3197-3225.文章来源:https://www.toymoban.com/news/detail-790651.html
[2] Ping Jiang, Qi Zhou, Xinyu Shao. Surrogate Model-Based Engineering Design and Optimization [M]. 2020.文章来源地址https://www.toymoban.com/news/detail-790651.html
到了这里,关于Kriging代理模型理论相关推导的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!