视频链接:(1)书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
01-背景介绍
大模型的快速发展

以语言模型和大语言模型为关键词的检索记录呈指数级上升;
以ChatGPT为代表的大语言模型技术成果引起了广泛的使用兴趣。
走向通用人工智能需要大模型
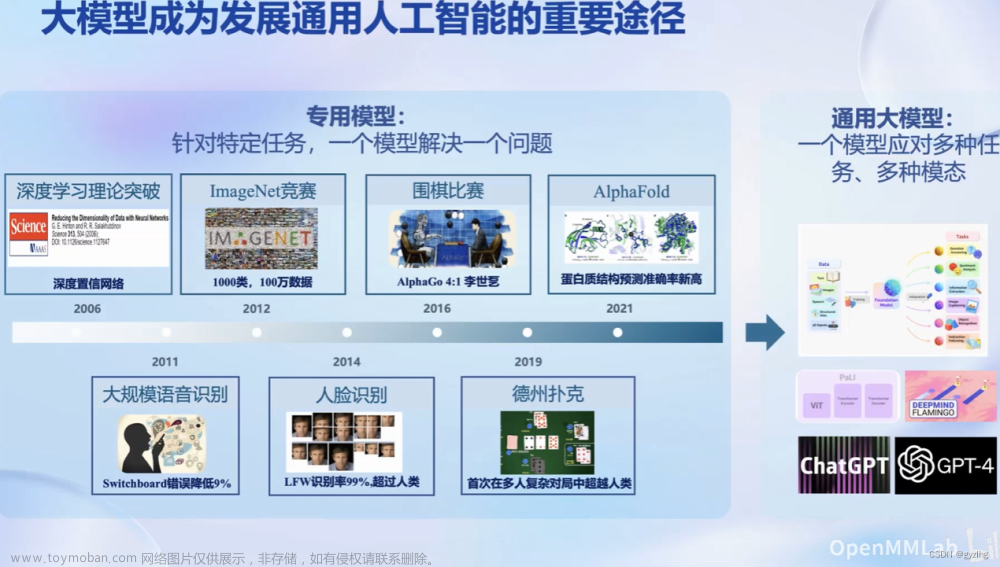
深度学习与强化学习模型在许多特定领域建立了许多富有成效的专用模型,用于解决特定领域的特定问题;
通用大模型的核心在于,使用一个模型应对具有多种模态的多种任务。
书生·浦语大模型开源历程


上海人工智能实验室推出的书生·浦语大模型包含轻量级、中量级、重量级三种,分别具有7B、20B、123B规模的模型参数,能够满足社区开发、商业应用、全面落地等不同的需要。

性能方面,以20B开源大模型为例,书生·浦语在各种能力性能方面全面领先相近量级的开源模型,并且以不到三分之一的参数量达到其他70B规模参数大模型的性能水平。
大模型的应用

大模型的常见应用包括智能客服、个人助手、专业行业应用等;
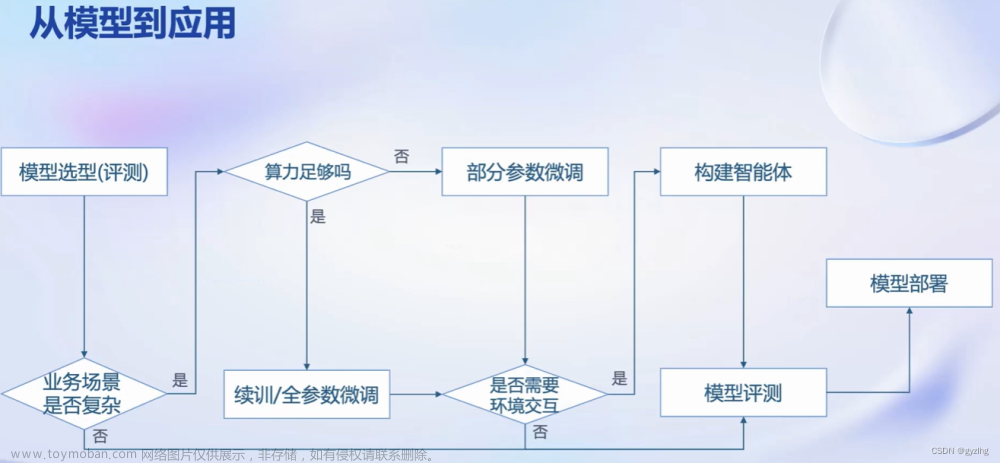
从大模型到实际应用,需要涉及到模型选型、参数调整、模型评测、模型部署这四步,其中具体要对应用场景的复杂程度、算力大小、环境交互需求等对应用过程进行具体调整;
02-书生·浦语全链条开源开放体系

书生·浦语针对大模型的全链条建立完整的了开源开放体系,包括数据支持、预训练、参数微调、模型部署、模型评测、智能体应用等功能。
数据

开放的数据包括文本数据、图像-文本数据、视频数据等,共计2TB,并且这些数据均进行了多模态融合、精细化处理、价值观对齐等处理;

此外在OpenDataLab中提供了更为丰富多样的开放数据
预训练

预训练工具与算法框架具备高可扩展性、极致性能优化、兼容主流生态、开箱即用等特点。
微调

大语言模型的常用微调方法包括增量续调、有监督微调;
增量续调多用于垂直领域的模型,包括文字、图像、代码等,格式和预训练一致;
有监督微调的训练数据以高质量的对话、问答数据为主,所需数据量要小于预训练和增量续调。

提供了高效微调框架XTuner,能够适配多种微调算法、开源生态,能够自动优化加速,并且能够适配多种硬件,包括消费级显卡与数据中心等。

例如,显存为8GB的消费级显卡也能够轻松适用于微调算法。
评测

目前国内外评测体系可分为客观评测、主观评测,其中以客观评测类型为主;

提供了OpenCompass评测体系,包含学科、语言、知识、理解、推理、安全共6大维度,有超过40w+道评测题目;
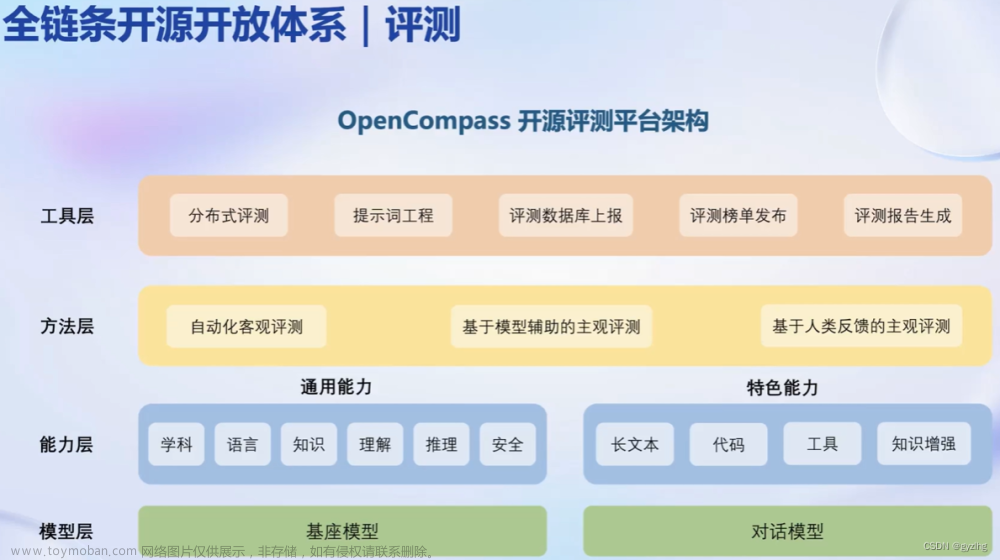
评测平台包括模型层、能力层、方法层、工具层共四个层次。
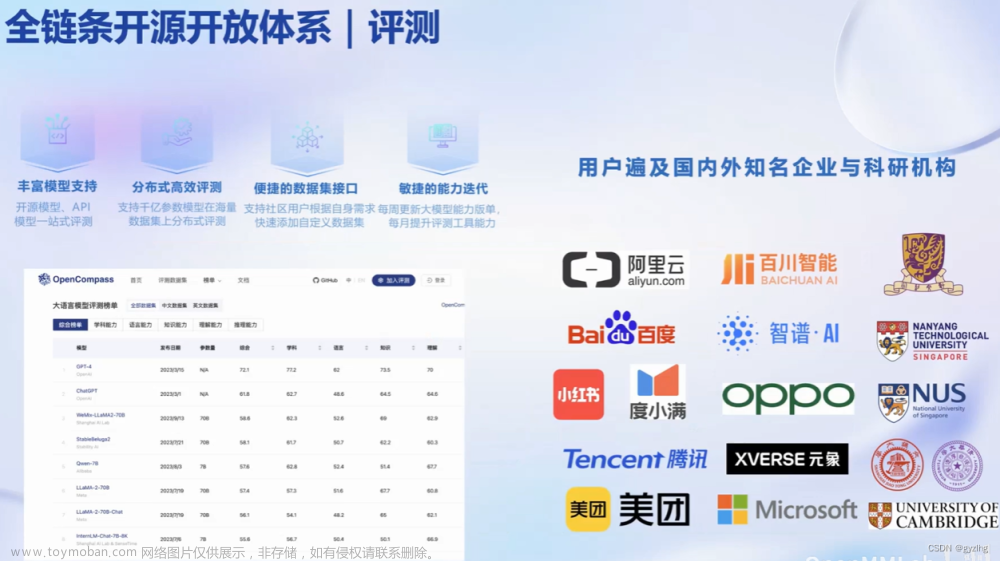
OpenCompass具有丰富的模型支持、实现了分布式高效评测、提供了便捷的数据集接口、具备敏捷的能力迭代等优点。

部署

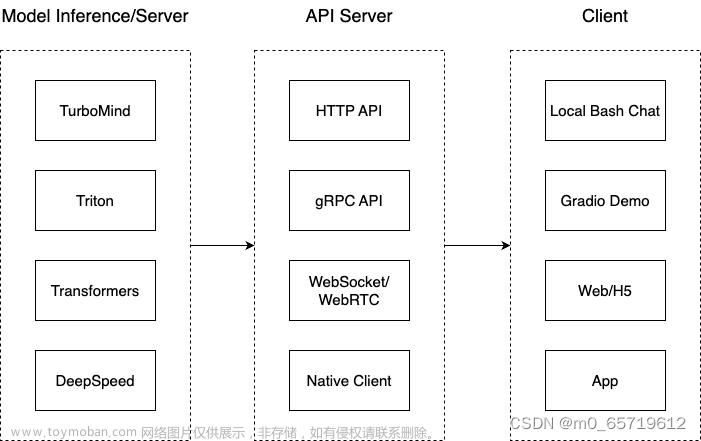
针对大语言模型的特点以及所对应的技术挑战,提出合适的部署方案;
大语言模型具有内存开销巨大、动态Shape、模型结构相对简单等特点,对设备、推理、服务提出了技术挑战,对应的部署方案具备模型并行、低比特量化、Attetion优化、计算和访存优化、Continuous Batching等技术点。

提供了LMDeploy框架,实现了大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理、服务等,提供了高效的推理引擎与完备易用的工具链,包括有关接口、轻量化、推理引擎、服务等的支持。

基于LMDeploy部署方案的模型在静态与动态推理性能方面具有显著的优势。
应用:从大语言模型到智能体

大语言模型具有一定的局限性,包括最新信息与知识的获取、回复的可靠性、数学计算、工具使用和交互等问题,单纯的大语言模型不等于通用人工智能体。

Lagent是一个轻量级的智能体框架,能够支持多种类型的智能体能力、多种大语言模型,并且具有丰富的工具支持。

AgentLego是一个多模态智能体工具箱,是一个工具集合,具有丰富的工具集合、支持多个主流智能体系统、具备灵活的多模态工具调用接口、可一键远程工具部署等。
 文章来源:https://www.toymoban.com/news/detail-790805.html
文章来源:https://www.toymoban.com/news/detail-790805.html
扫描二维码查看书生·浦语的Github主页,获取相关支持。文章来源地址https://www.toymoban.com/news/detail-790805.html
到了这里,关于书生·浦语大模型实战营:Ch1-书生·浦语大模型全链路开源体系的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!