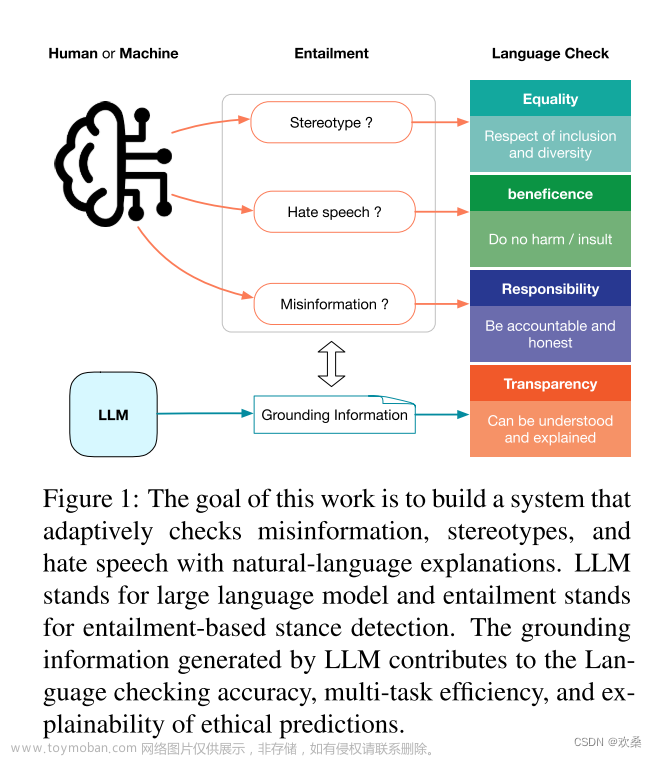
对齐语言模型的通用和可迁移对抗攻击
论文地址:https://arxiv.org/abs/2310.06387
1.Motivation
- 之前的越狱攻击方法可以通过对有害请求添加对抗前缀或后缀来破解对齐的LLM,以产生有害的答案。然而,由于这些前/后缀的不自然性,这些对抗性prompt可以通过简单的困惑检测器轻松防御。
- 本文提出是否可以利用LLM的上下文学习(ICL)能力来使用自然语言越狱LLMs。利用模型的上下文学习能力,我们可以通过首先向LLM展示另一个有害的查询-答案演示来诱导LLM生成所需的内容。
- 此外,由于这个对抗演示也使用自然语言,因此上下文攻击也更加隐蔽,更难被发现

2. Method
In-Context Attack
上下文攻击的方法很简单:就是在输入提示中添加对抗性演示来诱导模型完成有害指令 。
首先收集一些其他有害提示{x_i}及其相应的有害答案{y_i}作为上下文攻击演示 。
然后,将提示[x_1,y_1,···,x_k,y_k]与目标攻击提示x串联起来,得到最终的攻击提示P_attack。


In-Context Defense
除了攻击,本文还提出了一种上下文防御(ICD)方法,对于之前的攻击方法,比如下图这种添加对抗后缀的方法,上下文防御通过添加一个安全的上下文演示来提醒模型不要生成有害输出。(防御的是其他文章的方法)。

具体算法:
首先收集一些其他有害提示{x_i}及其相应的安全输出{y_i}作为上下文安全演示 。
然后,将提示[x_1,y_1,···,x_k,y_k] 串联起来,得到一个更安全的语言模型。
当这个安全演示与对抗指令一起输入时,这个对抗指令就会失效,不再输出有害内容。

3. Experiments
表1展示了不同上下文演示样本数下ICA的攻击成功率和基于优化的越狱方法的比较,所有这些方法都需要优化500步的提示 。
Individual:针对一个有害行为设计的对抗提示,multiple:根据多个有害行为设计的通用对抗提示
从表1的比较来看,我们的ICA攻击效果优于一些基于优化的方法,包括GBDA和PEZ。 虽然上一篇的GCG的攻击成功率非常高,但它生成的对抗后缀很容易被检测机制防御,如表2,经过过滤防御后攻击完全失效。 而本文的方法因为用到的对抗演示是自然语言形式,所以可以绕过防御检测。

文章来源:https://www.toymoban.com/news/detail-790927.html

表3展示了防御GCG越狱方法的效果(ASR) 分别在这俩个模型上进行了实验,可以看到原本高攻击成功率的GCG,在应用一次防御演示后攻击成功率下降非常大,应用两次时基本为0了。说明这个基于上下文学习的防御方法很有效。 文章来源地址https://www.toymoban.com/news/detail-790927.html

到了这里,关于【论文阅读】Jailbreak and Guard Aligned Language Modelswith Only Few In-Context Demonstrations的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!