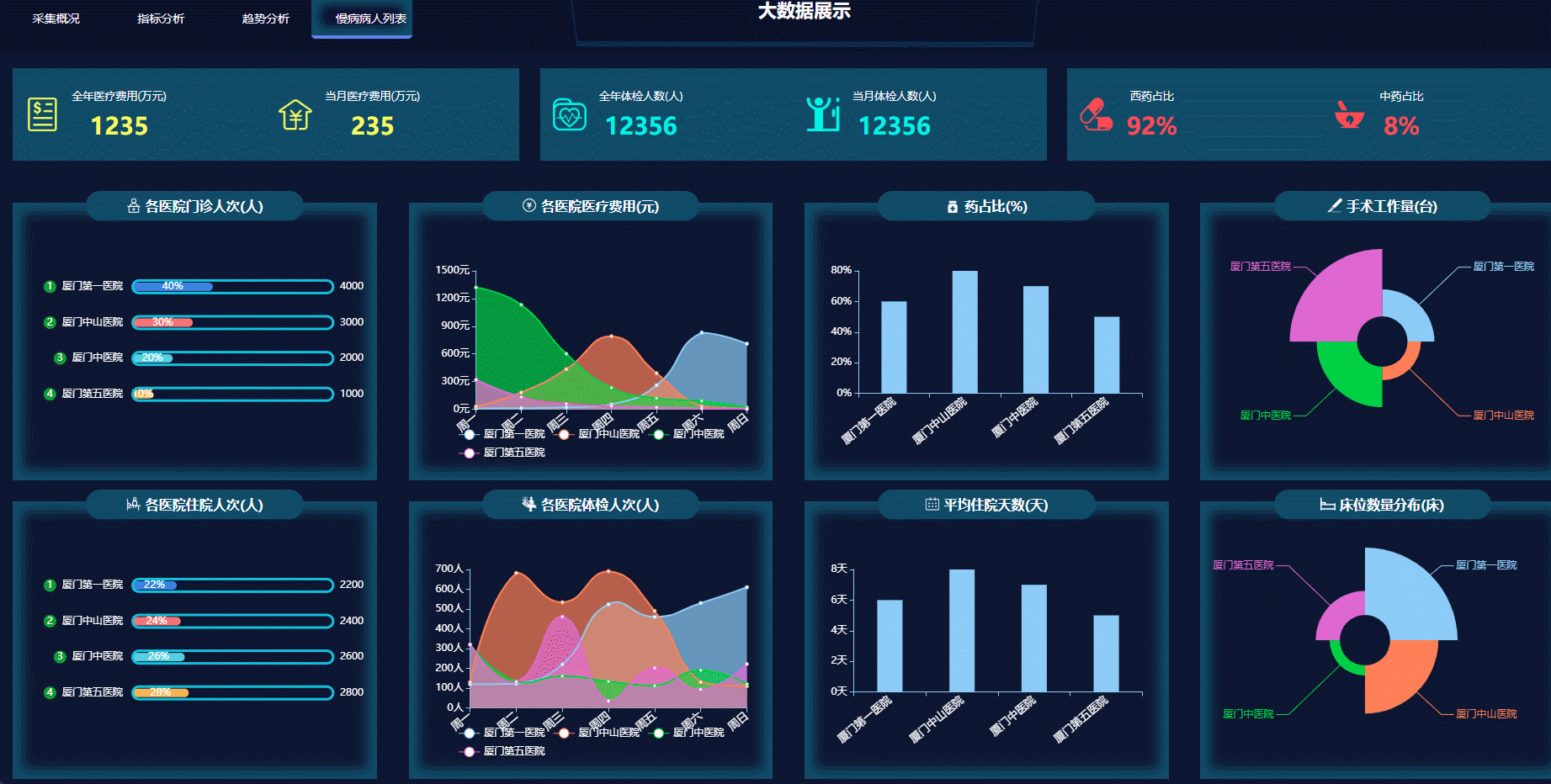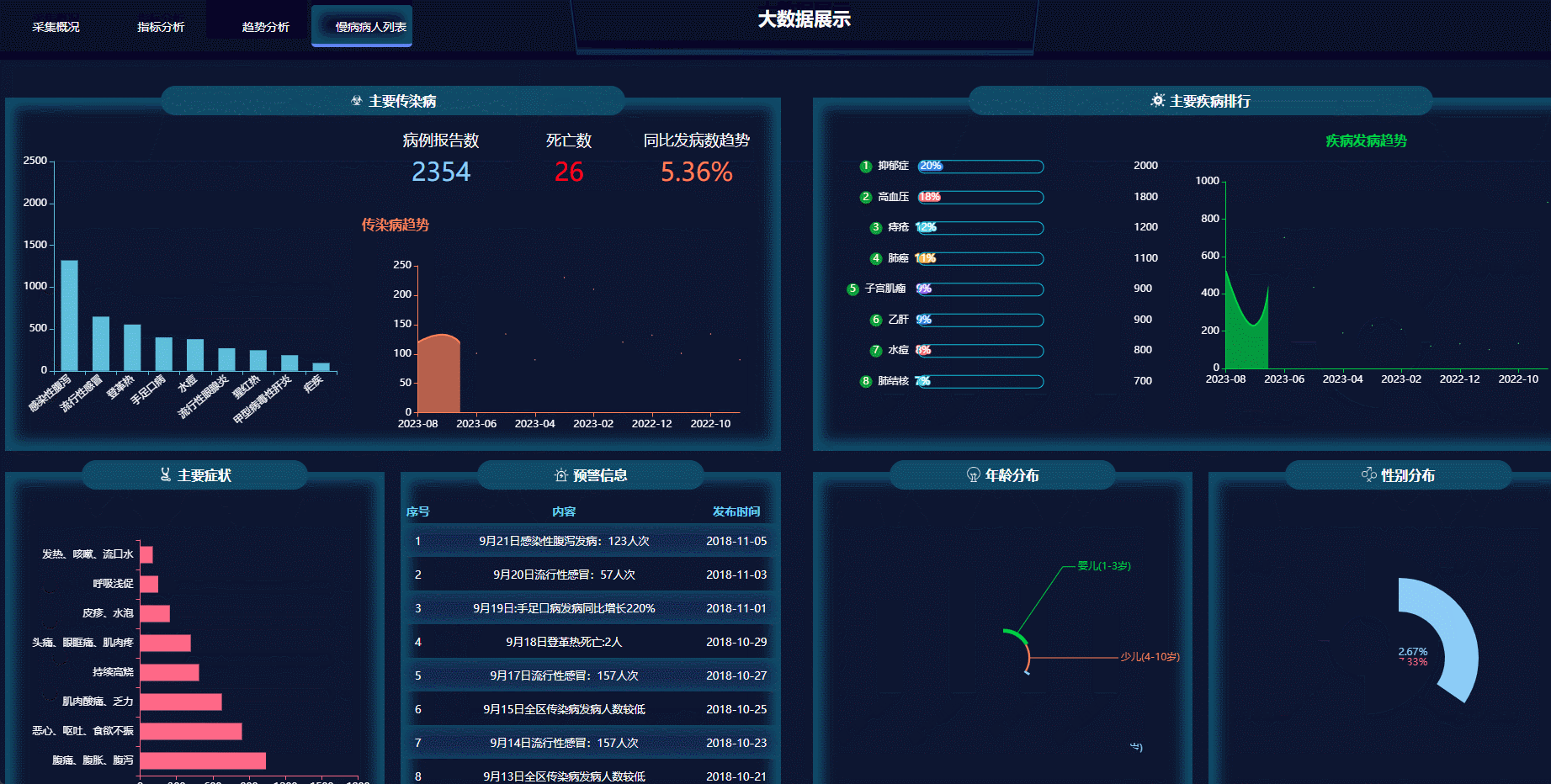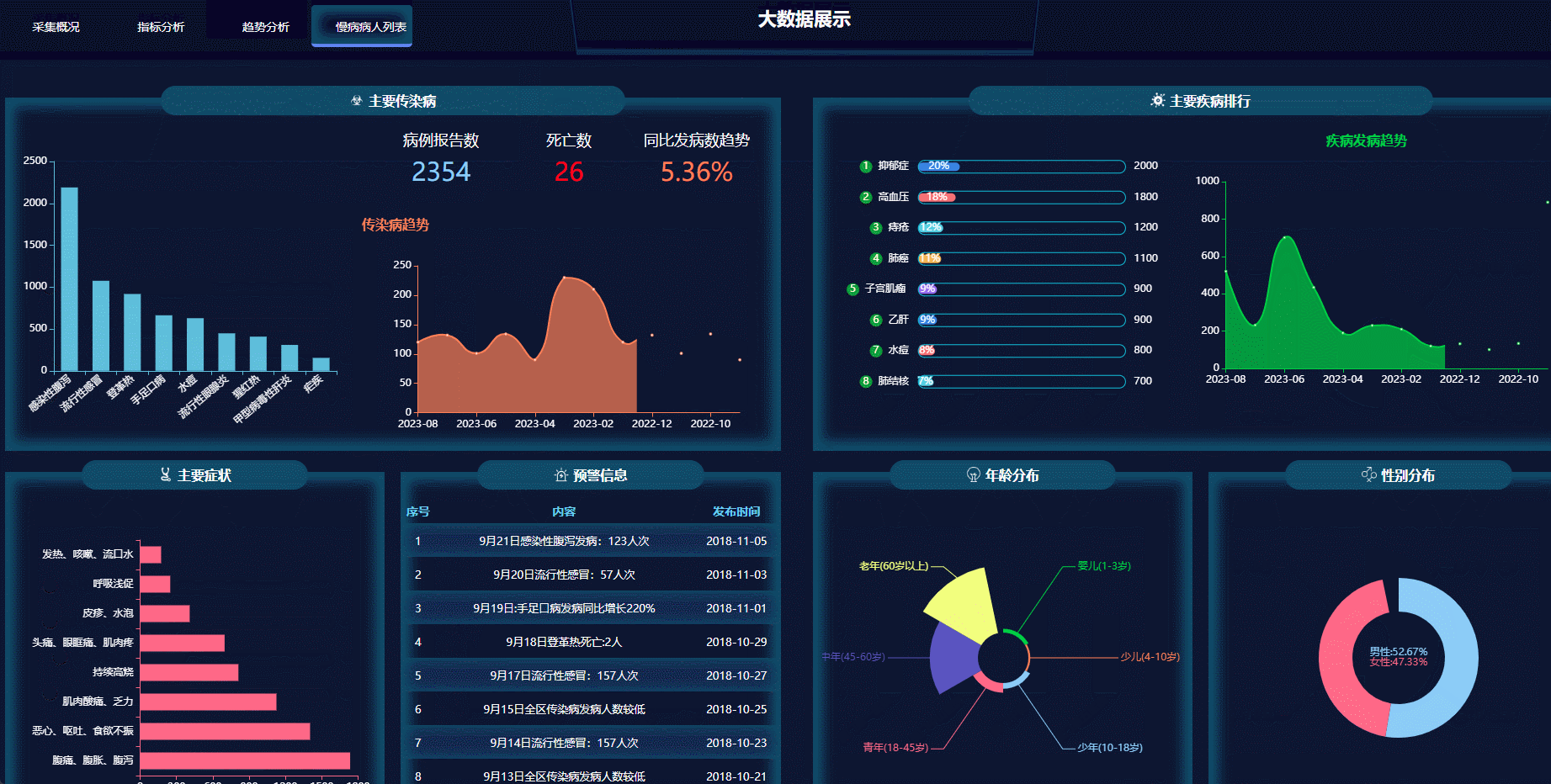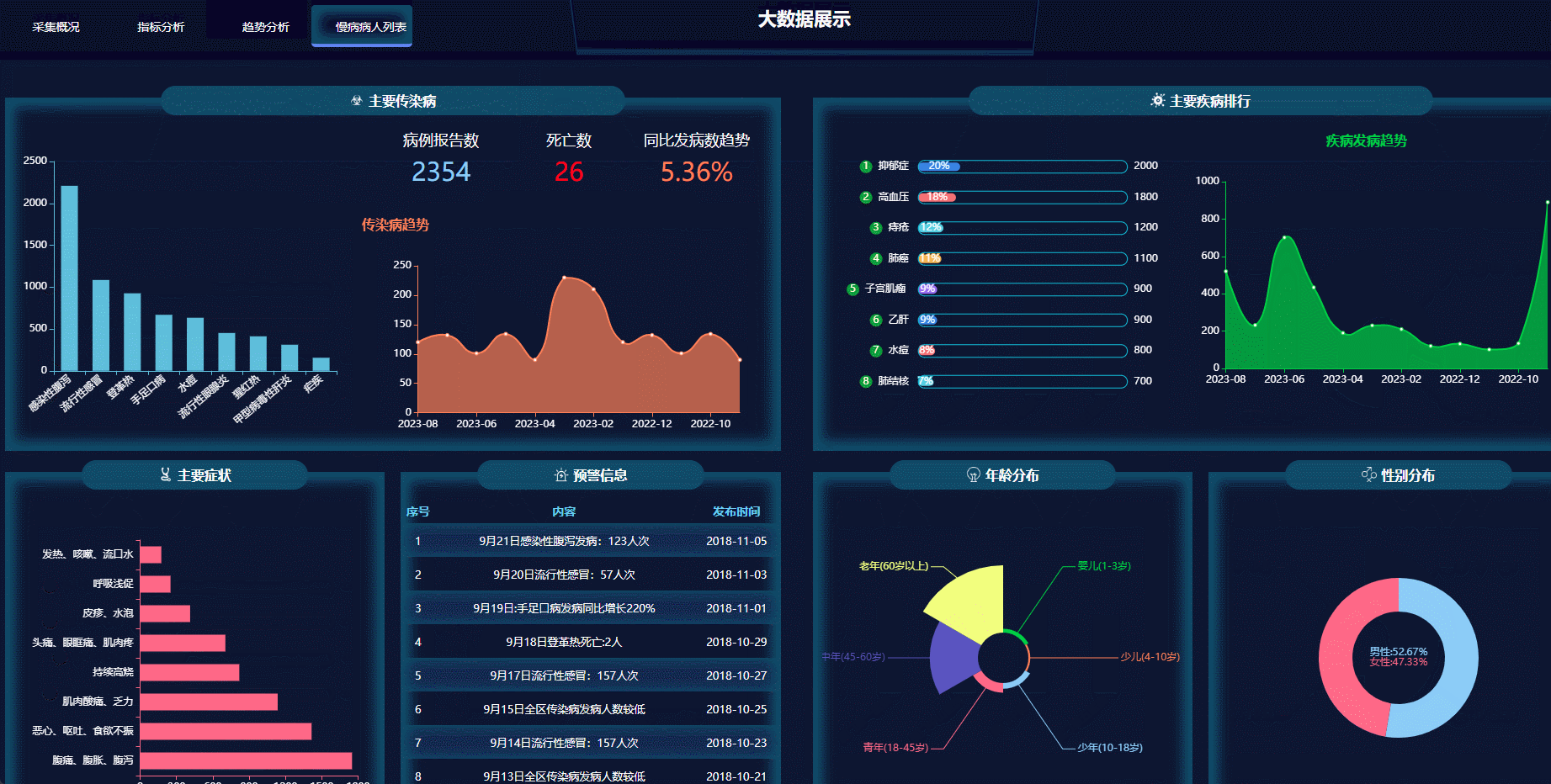
一、项目概述
知识图谱是将知识连接起来形成的一个网络。由节点和边组成,节点是实体,边是两个实体的关系,节点和边都可以有属性。知识图谱除了可以查询实体的属性外,还可以很方便的从一个实体通过遍历关系的方式找到相关的实体及属性信息。
基于知识图谱+flask的KBQA医疗问答系统基于医疗方面知识的问答,通过搭建一个医疗领域知识图谱,并以该知识图谱完成自动问答与分析服务。 基于知识图谱+flask的KBQA医疗问答系统以neo4j作为存储,本系统知识图谱建模使用的最大向前匹配是一种贪心算法,从句首开始匹配,每次选择最长的词语。由于只需一次遍历,因此在速度上相对较快。 算法相对简单,容易实现和理解,不需要复杂的数据结构。 对于中文文本中大部分是左向的情况,最大向前匹配通常能够较好地切分。与最大向前匹配相反,最大向后匹配从句尾开始匹配,每次选择最长的词语。适用于大部分右向的中文文本。双向最大匹配结合了最大向前匹配和最大向后匹配的优势,从两个方向分别匹配,然后选择分词数量较少的一种结果。这种方法综合考虑了左向和右向的特点,提高了切分的准确性,以关键词执行cypher查询,并返回相应结果查询语句作为问答。后面我又设计了一个简单的基于 Flask 的聊天机器人应用,利用nlp自然语言处理,通过医疗AI助手根据用户的问题返回结果,用户输入和系统返回的输出结果都会一起自动存储到sql数据库。
在多模式匹配方面, Aho-Corasick算法专门用于在一个文本中同时搜索多个模式(关键词)。相比于暴力搜索算法,Aho-Corasick算法的时间复杂度较低,在本知识图谱建模问答系统中,性能更为显著。在线性时间复杂度方面,进行预处理的阶段,Aho-Corasick算法构建了一个确定性有限自动机(DFA),使得在搜索阶段的时间复杂度为O(n),其中n是待搜索文本的长度。这种线性时间复杂度使得算法在本应用中非常高效。在灵活性方面, Aho-Corasick算法在构建有限自动机的过程中,可以方便地添加、删除模式串,而不需要重新构建整个数据结构,提高了算法的灵活性和可维护性。
二、实现知识图谱的医疗知识问答系统基本流程
-
配置好所需要的环境(jdk,neo4j,pycharm,python等)
-
爬取所需要的医学数据,获取所需基本的医疗数据。
-
对医疗数据进行数据清洗处理。
-
基于贪心算法进行分词策略。
-
关系抽取定义与实体识别。
-
知识图谱建模。
-
基于
Aho-Corasick算法进行多模式匹配。 -
设计一个基于 Flask 的聊天机器人AI助手。
-
设计用户输入和系统输出记录数据自动存储到sql数据库。
三、项目工具所用的版本号
Neo4j版本:Neo4j Desktop1.4.15;
neo4j里面医疗系统数据库版本:4.4.5;
Pycharm版本:2021;
JDK版本:jdk1.8.0_211;
MongoDB版本:MongoDB-windows-x86_64-5.0.14;
flask版本:3.0.0
四、所需要软件的安装和使用
(一)安装JAVA
1.下载java安装包:
官网下载链接:https://www.oracle.com/java/technologies/javase-downloads.html

本人下载的版本为JDK-1.8,JDK版本的选择一定要恰当,版本太高或者太低都可能导致后续的neo4j无法使用。
安装好JDK之后就要开始配置环境变量了。 配置环境变量的步骤如下:
右键单击此电脑—点击属性—点击高级系统设置—点击环境变量
在下方的系统变量区域,新建环境变量,命名为JAVA_HOME,变量值设置为刚才JAVA的安装路径,我这里是C:\Program Files\Java\jdk1.8.0_211
编辑系统变量区的Path,点击新建,然后输入 %JAVA_HOME%\bin
打开命令提示符CMD(WIN+R,输入cmd),输入 java -version,若提示Java的版本信息,则证明环境变量配置成功。
2.安装好JDK之后,就可以安装neo4j了
2.1 下载neo4j
官方下载链接:https://neo4j.com/download-center/#community
也可以直接下载我上传到云盘链接:
Neo4j Desktop Setup 1.4.15.exe
链接:https://pan.baidu.com/s/1eXw0QjqQ9nfpXwR09zLQHA?pwd=2023
提取码:2023
打开之后会有一个自己设置默认路径,可以根据自己电脑情况自行设置,然后等待启动就行了
打开之后我们新建一个数据库,名字叫做:“基于医疗领域的问答系统”
详细信息看下图:
数据库所用的是4.4.5版本,其他数据库参数信息如下:
五、项目结构整体目录
├── pycache \\编译结果的保存目录
│ │ ├── answer_search.cpython-39.pyc
│ │ ├── question_classifier.cpython-39.pyc
│ │ │── 基于问句解析.cpython-39.pyc
│ │ │── 基于问句解析结果查询.cpython-39.pyc
│ │ │── 基于问题分类.cpython-39.pyc
├── data\本项目的数据
│ └── medical.json \本项目的数据,通过build_medicalgraph.py导neo4j
├── dict
│ ├── check.txt \诊断检查项目实体库
│ ├── deny.txt \否定词词库
│ ├── department.txt \医疗科目实体库
│ ├── disease.txt \疾病实体库
│ ├── drug.txt \药品实体库
│ ├── food.txt \食物实体库
│ ├── producer.txt \在售药品库
│ └── symptom.txt \疾病症状实体库
├── prepare_data \爬虫及数据处理
│ ├──__pycache__
│ ├── build_data.py \数据库操作脚本
│ ├── data_spider.py \网络资讯采集脚本
│ └── max_cut.py \基于词典的最大向前/向后脚本
│ ├── 处理后的medical数据.xlsx
│ ├── MongoDB数据转为json格式数据文件.py
│ ├──从MongoDB导出的medical.csv
│ ├──data.json #从MongoDB导出的json格式数据
├── static \静态资源文件
├── templates
│ ├──index.html \问答系统前端UI页面
├── app.py \启动flask问答AI脚本主程序
├── question_classifier.py \问句类型分类脚本
├── answer_search.py \基于问题答复脚本
├── build_medicalgraph.py \构建医疗图谱脚本
├── chatbot_graph.py \医疗AI助手问答系统机器人脚本
├── question_parser.py [\基于问句解析脚本](file://基于问句解析脚本)
├── 删除所有关系.py \可有可无的脚本文件
├── 删除关系链.py \可有可无的脚本文件
├── 两节点新加关系.py \可有可无的脚本文件
├── 交互 匹配所有节点.py \可有可无的脚本文件
这里chatbot_graph.py脚本首先从需要运行的chatbot_graph.py文件开始分析。
该脚本构造了一个问答类ChatBotGraph,定义了QuestionClassifier类型的成员变量classifier、QuestionPase类型的成员变量parser和AnswerSearcher类型的成员变量searcher。
question_classifier.py脚本构造了一个问题分类的类QuestionClassifier,定义了特征词路径、特征词、领域actree、词典、问句疑问词等成员变量。question_parser.py问句分类后需要对问句进行解析。该脚本创建一个QuestionPaser类,该类包含三个成员函数。
answer_search.py问句解析之后需要对解析后的结果进行查询。该脚本创建了一个AnswerSearcher类。与build_medicalgraph.py类似,该类定义了Graph类的成员变量g和返回答案列举的最大个数num_list。该类的成员函数有两个,一个查询主函数一个回复模块。
问答系统框架的构建是通过chatbot_graph.py、answer_search.py、question_classifier.py、question_parser.py等脚本实现。
五、系统实现
数据的抓取与存储
安装MongoDB数据库:
MongoDB官方下载地址:
https://www.mongodb.com/try




安装完成:

然后我们进行MongoDB的环境配置:
在变量Path里加入E:\MongoDB\bin
打开终端(cmd)输入mongod --dbpath E:\MongoDB\data\db
在浏览器输入
127.0.0.1:27017
查看MongoDB服务是否启动成功:

安装好MongoDB之后开始爬取数据:
数据来源于寻医问药网:http://jib.xywy.com/

具体的疾病详情页面如下:
首先对网址上的疾病链接进行分析,以感冒为例:
感冒的链接:http://jib.xywy.com/il_sii_38.htm
可以看到,上面包含了疾病的简介、病因、预防、症状、检查、治疗、并发症、饮食保健等详情页的内容。下面我们要使用爬虫把信息收集起来。要收集 url 下面对应的数据,具体爬虫代码如下:
之前老版本的insert方法被弃用,再用会出现警告。insert 替换为了 insert_one,这样就不会再收到关于 insert 方法被弃用的警告了。
'''基于寻医问药的医疗数据采集'''
# 使用 insert_one 或 insert_many 方法。提供了更多的灵活性,并且支持更多的功能,比如插入后返回的文档的 _id 值。
class MedicalSpider:
def __init__(self):
self.conn = pymongo.MongoClient()
self.db = self.conn['medical2']
self.col = self.db['data']
def insert_data(self, data):
# 使用 insert_one 方法插入单个文档
self.col.insert_one(data)
根据url,请求html
用于获取指定 URL 的 HTML 内容的函数,使用了 Python 的 requests 库。在这个代码中,设置请求的头部信息(User-Agent),代理信息(proxies),然后使用 requests.get 方法获取页面内容,并指定了编码为 ‘gbk’。
'''根据url,请求html'''
def get_html(self,url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
proxies = {
'http': None,
'https': None
}
html = requests.get(url=url, headers=headers, proxies=proxies)
html.encoding = 'gbk'
return html.text
爬取医疗相关的信息,包括疾病描述、疾病预防、疾病症状、治疗方法等。
url_parser 函数
def url_parser(self, content):
selector = etree.HTML(content)
urls = ['http://www.anliguan.com' + i for i in selector.xpath('//h2[@class="item-title"]/a/@href')]
return urls
url_parser 函数函数的作用是解析传入的 HTML 内容,提取出页面中疾病相关的链接。具体来说:
-
etree.HTML(content): 使用 lxml 库中的 etree 模块将 HTML 内容转换成可被 XPath 解析的对象。 -
selector.xpath('//h2[@class="item-title"]/a/@href'): 使用 XPath 选择器提取所有<h2>标签中class属性为"item-title"的子节点<a>的href属性,得到的是一组相对链接。 -
['http://www.anliguan.com' + i for i in ...]: 将相对链接转换成完整的链接,拼接在'http://www.anliguan.com'前面。
这个函数的作用是解析传入的 HTML 内容,提取出页面中疾病相关的链接。具体来说:文章来源:https://www.toymoban.com/news/detail-790952.html
spider_main函数是主要的爬虫逻辑,循环遍历页面,爬取不同类型的医疗信息,并将结果存储到数据库中文章来源地址https://www.toymoban.com/news/detail-790952.html
'''url解析'''
def url_parser(self,content):
selector=etree.HTML(content)
urls=['http://www.anliguan.com'+i for i in selector.xpath('//h2[@class="item-title"]/a/@href')]
return urls
'''主要的爬取的链接'''
def spider_main(self):
# 收集页面
for page in range(1,11000):
try:
basic_url='http://jib.xywy.com/il_sii/gaishu/%s.htm'%page # 疾病描述
cause_url='http://jib.xywy.com/il_sii/cause/%s.htm'%page # 疾病起因
prevent_url='http://jib.xywy.com/il_sii/prevent/%s.htm'%page # 疾病预防
symptom_url='http://jib.xywy.com/il_sii/symptom/%s.htm'%page #疾病症状
inspect_url='http://jib.xywy.com/il_sii/inspect/%s.htm'%page # 疾病检查
treat_url='http://jib.xywy.com/il_sii/treat/%s.htm'%page # 疾病治疗
food_url = 'http://jib.xywy.com/il_sii/food/%s.htm' % page # 饮食治疗
drug_url = 'http://jib.xywy.com/il_sii/drug/%s.htm' % page #药物
-
basic_url、symptom_url、food_url、drug_url和cause_url是根据page变量构建的不同 URL 地址,用于访问和爬取不同类型信息的网页。
-data是一个字典,用于存储从不同 URL 中获取的数据。
2. 对不同 URL 进行爬取和信息提取:
-data['ba
到了这里,关于大数据知识图谱——基于知识图谱+flask的大数据(KBQA)NLP医疗知识问答系统(全网最详细讲解及源码/建议收藏)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!