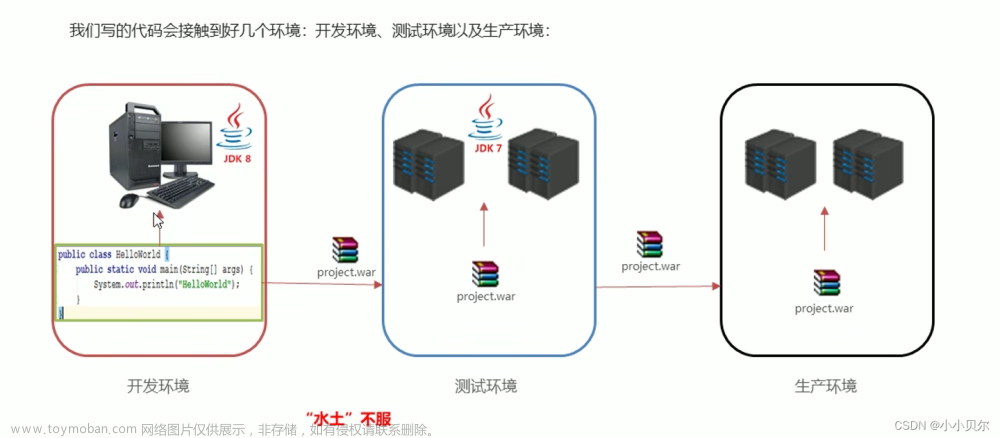
1 概述
Apache Spark 是一个为高效处理大规模数据而设计的分布式计算引擎。它采用分布式并行计算的方式,将数据拆分、计算、合并的任务分散到多台计算机上,从而实现了高效的数据处理和分析。
2 应用场景
大规模数据处理与分析
- Spark 能够处理海量数据,通过并行计算任务提高了处理效率。它广泛应用于金融、电信、医疗等领域的数据处理和分析。
流式数据处理
- Spark Streaming 允许实时处理数据流,将其转化为可供分析和存储的批处理数据。这在在线广告、网络安全等实时数据分析场景中非常有用。
机器学习
- Spark 提供了机器学习库(MLlib),支持多种机器学习算法和模型训练,用于推荐系统、图像识别等机器学习应用。
图计算
- Spark 的图计算库(GraphX)支持多种图计算算法,适用于社交网络分析、推荐系统等图分析场景。
本篇文档将介绍两种使用 Spark 计算引擎实现批量数据写入 MatrixOne 的示例。一种示例是从 MySQL 迁移数据至 MatrixOne,另一种是将 Hive 数据写入 MatrixOne。
3 前期准备
硬件环境
本次实践对于机器的硬件要求如下:

软件环境
本次实践需要安装部署以下软件环境:
- 已完成安装和启动 MatrixOne。
- 下载并安装 IntelliJ IDEA version 2022.2.1 及以上。
- 下载并安装 JDK 8+。
- 如需从 Hive 导入数据,需要安装 Hadoop 和 Hive。
- 下载并安装 MySQL Client 8.0.33。
4 示例一
从 MySQL 迁移数据至 MatrixOne
步骤一:初始化项目
1. 启动 IDEA,点击 File > New > Project,选择 Spring Initializer,并填写以下配置参数:
- Name:mo-spark-demo
- Location:~\Desktop
- Language:Java
- Type:Maven
- Group:com.example
- Artiface:matrixone-spark-demo
- Package name:com.matrixone.demo
- JDK 1.8

2. 添加项目依赖,在项目根目录下的 pom.xml 内容编辑如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.mo</groupId>
<artifactId>mo-spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>3.2.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-catalyst_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-core-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
</dependencies>
</project>步骤二:读取 MatrixOne 数据
使用 MySQL 客户端连接 MatrixOne 后,创建演示所需的数据库以及数据表。
1. 在 MatrixOne 中创建数据库、数据表,并导入数据:
CREATE DATABASE test;
USE test;
CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');2. 在 IDEA 中创建 MoRead.java 类,以使用 Spark 读取 MatrixOne 数据:
package com.matrixone.spark;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* @auther MatrixOne
* @desc 读取 MatrixOne 数据
*/
public class MoRead {
// parameters
private static String master = "local[2]";
private static String appName = "mo_spark_demo";
private static String srcHost = "192.168.146.10";
private static Integer srcPort = 6001;
private static String srcUserName = "root";
private static String srcPassword = "111";
private static String srcDataBase = "test";
private static String srcTable = "person";
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().appName(appName).master(master).getOrCreate();
SQLContext sqlContext = new SQLContext(sparkSession);
Properties properties = new Properties();
properties.put("user", srcUserName);
properties.put("password", srcPassword);
Dataset<Row> dataset = sqlContext.read()
.jdbc("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase,srcTable, properties);
dataset.show();
}
}3. 在 IDEA 中运行 MoRead.Main(),执行结果如下:

步骤三:将 MySQL 数据写入 MatrixOne
现在可以开始使用 Spark 将 MySQL 数据迁移到 MatrixOne。
1. 准备 MySQL 数据:
在 node3 上,使用 Mysql 客户端连接本地 Mysql,创建所需数据库、数据表、并插入数据:
mysql -h127.0.0.1 -P3306 -uroot -proot
mysql> CREATE DATABASE motest;
mysql> USE motest;
mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');2. 清空 MatrixOne 表数据:
在 node3 上,使用 MySQL 客户端连接本地 MatrixOne。由于本示例继续使用前面读取 MatrixOne 数据的示例中的 test 数据库,因此我们需要首先清空 person 表的数据。
-- 在 node3 上,使用 Mysql 客户端连接 node1 的 MatrixOne
mysql -h192.168.146.10 -P6001 -uroot -p111
mysql> TRUNCATE TABLE test.person;3. 在 IDEA 中编写代码:
创建 Person.java 和 Mysql2Mo.java 类,使用 Spark 读取 MySQL 数据。Mysql2Mo.java 类代码可参考如下示例:
package com.matrixone.spark;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.*;
import java.sql.SQLException;
import java.util.Properties;
/**
* @auther MatrixOne
* @desc
*/
public class Mysql2Mo {
// parameters
private static String master = "local[2]";
private static String appName = "app_spark_demo";
private static String srcHost = "127.0.0.1";
private static Integer srcPort = 3306;
private static String srcUserName = "root";
private static String srcPassword = "root";
private static String srcDataBase = "motest";
private static String srcTable = "person";
private static String destHost = "192.168.146.10";
private static Integer destPort = 6001;
private static String destUserName = "root";
private static String destPassword = "111";
private static String destDataBase = "test";
private static String destTable = "person";
public static void main(String[] args) throws SQLException {
SparkSession sparkSession = SparkSession.builder().appName(appName).master(master).getOrCreate();
SQLContext sqlContext = new SQLContext(sparkSession);
Properties connectionProperties = new Properties();
connectionProperties.put("user", srcUserName);
connectionProperties.put("password", srcPassword);
connectionProperties.put("driver","com.mysql.cj.jdbc.Driver");
//jdbc.url=jdbc:mysql://127.0.0.1:3306/database
String url = "jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase + "?characterEncoding=utf-8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=Asia/Shanghai";
//SparkJdbc 读取表内容
System.out.println("读取数据库中 person 的表内容");
// 读取表中所有数据
Dataset<Row> rowDataset = sqlContext.read().jdbc(url,srcTable,connectionProperties).select("*");
//显示数据
//rowDataset.show();
//筛选 id > 2 的数据,并将 name 字段添加 spark_ 前缀
Dataset<Row> dataset = rowDataset.filter("id > 2")
.map((MapFunction<Row, Row>) row -> RowFactory.create(row.getInt(0), "spark_" + row.getString(1), row.getDate(2)), RowEncoder.apply(rowDataset.schema()));
//显示数据
//dataset.show();
Properties properties = new Properties();
properties.put("user", destUserName);
properties.put("password", destPassword);;
dataset.write()
.mode(SaveMode.Append)
.jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase,destTable, properties);
}
}在上述代码中,执行了简单的 ETL 操作(筛选 id > 2 的数据,并在 name 字段前添加前缀 "spark_"),并将处理后的数据写入到 MatrixOne 数据库中。
步骤四:查看结果
在 MatrixOne 中执行如下 SQL 查看执行结果:
select * from test.person;
+------+---------------+------------+
| id | name | birthday |
+------+---------------+------------+
| 3 | spark_wangwu | 2023-07-12 |
| 4 | spark_zhaoliu | 2023-08-07 |
+------+---------------+------------+
2 rows in set (0.01 sec)5 示例二
将 Hive 数据导入到 MatrixOne
步骤一:初始化项目
1. 启动 IDEA,点击 File > New > Project,选择 Spring Initializer,并填写以下配置参数:
- Name:mo-spark-demo
- Location:~\Desktop
- Language:Java
- Type:Maven
- Group:com.example
- Artiface:matrixone-spark-demo
- Package name:com.matrixone.demo
- JDK 1.8
2. 添加项目依赖,在项目根目录下的 pom.xml 内容编辑如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.mo</groupId>
<artifactId>mo-spark-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>3.2.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-catalyst_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-core-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
</dependencies>
</project>
步骤二:准备 Hive 数据
在终端窗口中执行以下命令,创建 Hive 数据库、数据表,并插入数据:
hive
hive> create database motest;
hive> CREATE TABLE `users`(
`id` int,
`name` varchar(255),
`age` int);
hive> INSERT INTO motest.users (id, name, age) VALUES(1, 'zhangsan', 12),(2, 'lisi', 17),(3, 'wangwu', 19);步骤三:创建 MatrixOne 数据表
在 node3 上,使用 MySQL 客户端连接到 node1 的 MatrixOne。然后继续使用之前创建的 "test" 数据库,并创建新的数据表 "users"。
CREATE TABLE `users` (
`id` INT DEFAULT NULL,
`name` VARCHAR(255) DEFAULT NULL,
`age` INT DEFAULT NULL
)
步骤四:拷贝配置文件
将 Hadoop 根目录下的 "etc/hadoop/core-site.xml" 和 "hdfs-site.xml" 以及 Hive 根目录下的 "conf/hive-site.xml" 这三个配置文件复制到项目的 "resource" 目录中。

步骤五:编写代码
在 IntelliJ IDEA 中创建名为 "Hive2Mo.java" 的类,用于使用 Spark 从 Hive 中读取数据并将数据写入 MatrixOne。
package com.matrixone.spark;
import org.apache.spark.sql.*;
import java.sql.SQLException;
import java.util.Properties;
/**
* @auther MatrixOne
* @date 2022/2/9 10:02
* @desc
*
* 1.在 hive 和 matrixone 中分别创建相应的表
* 2.将 core-site.xml hdfs-site.xml 和 hive-site.xml 拷贝到 resources 目录下
* 3.需要设置域名映射
*/
public class Hive2Mo {
// parameters
private static String master = "local[2]";
private static String appName = "app_spark_demo";
private static String destHost = "192.168.146.10";
private static Integer destPort = 6001;
private static String destUserName = "root";
private static String destPassword = "111";
private static String destDataBase = "test";
private static String destTable = "users";
public static void main(String[] args) throws SQLException {
SparkSession sparkSession = SparkSession.builder()
.appName(appName)
.master(master)
.enableHiveSupport()
.getOrCreate();
//SparkJdbc 读取表内容
System.out.println("读取 hive 中 person 的表内容");
// 读取表中所有数据
Dataset<Row> rowDataset = sparkSession.sql("select * from motest.users");
//显示数据
//rowDataset.show();
Properties properties = new Properties();
properties.put("user", destUserName);
properties.put("password", destPassword);;
rowDataset.write()
.mode(SaveMode.Append)
.jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase,destTable, properties);
}
}步骤六:查看执行结果
在 MatrixOne 中执行如下 SQL 查看执行结果:
mysql> select * from test.users;
+------+----------+------+
| id | name | age |
+------+----------+------+
| 1 | zhangsan | 12 |
| 2 | lisi | 17 |
| 3 | wangwu | 19 |
+------+----------+------+
3 rows in set (0.00 sec)关于MatrixOne
MatrixOne 是一款基于云原生技术,可同时在公有云和私有云部署的多模数据库。该产品使用存算分离、读写分离、冷热分离的原创技术架构,能够在一套存储和计算系统下同时支持事务、分析、流、时序和向量等多种负载,并能够实时、按需的隔离或共享存储和计算资源。 云原生数据库MatrixOne能够帮助用户大幅简化日益复杂的IT架构,提供极简、极灵活、高性价比和高性能的数据服务。
MatrixOne企业版和MatrixOne云服务自发布以来,已经在互联网、金融、能源、制造、教育、医疗等多个行业得到应用。得益于其独特的架构设计,用户可以降低多达70%的硬件和运维成本,增加3-5倍的开发效率,同时更加灵活的响应市场需求变化和更加高效的抓住创新机会。在相同硬件投入时,MatrixOne可获得数倍以上的性能提升。
MatrixOne秉持开源开放、生态共建的理念,核心代码全部开源,全面兼容MySQL协议,并与合作伙伴打造了多个端到端解决方案,大幅降低用户的迁移
关键词:超融合数据库、多模数据库、云原生数据库、国产数据库。
MatrixOrigin 官网:新一代超融合异构开源数据库-矩阵起源(深圳)信息科技有限公司 MatrixOne文章来源:https://www.toymoban.com/news/detail-791165.html
Github 仓库:GitHub - matrixorigin/matrixone: Hyperconverged cloud-edge native database文章来源地址https://www.toymoban.com/news/detail-791165.html
到了这里,关于手把手入门MO | 如何使用使用 Spark 将批量数据写入 MatrixOne的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!