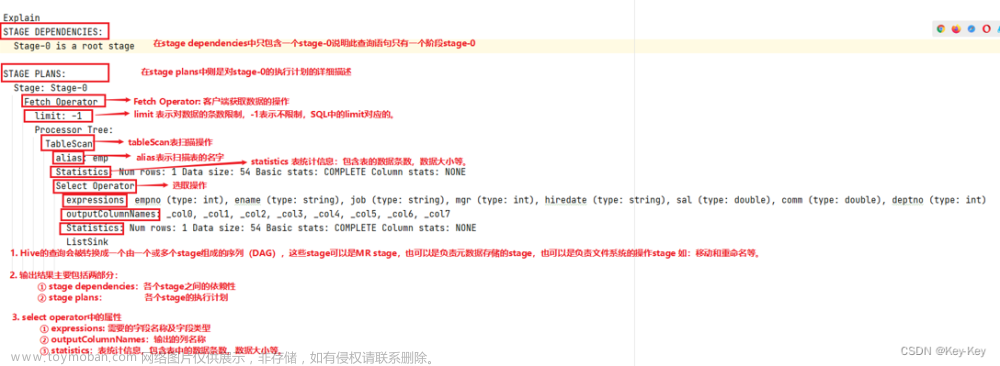
– explain语法查询**
– explain解析执行计划
– 以下优化为hive层面优化,常开****文章来源:https://www.toymoban.com/news/detail-791425.html
– 读取零拷贝
set hive.exec.orc.zerocopy=true; – 默认false
– 关联优化器
set hive.optimize.correlation=true; – 默认false
– fetch本地抓取
set hive.fetch.task.conversion=minimal; – 新版本默认more,老版本默认minimal
– 针对小文件开启本地模式
set hive.exec.mode.local.auto=true; – 默认false
– 并行执行任务
set hive.exec.parallel=true; – 打开任务并行执行,默认false
set hive.exec.parallel.thread.number=16; – 同一个sql允许最大并行度,默认为8
– Map端聚合相关配置
set hive.map.aggr = true; – 开启Map端聚合,默认是true
set hive.groupby.mapaggr.checkinterval = 100000; – 设置在Map端进行聚合操作的条目数目,默认100000
文章来源地址https://www.toymoban.com/news/detail-791425.html
到了这里,关于Hive命令调优大全的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!