目录
Spark 与云原生的结合
1. 传统 Spark 集群的痛点
2. Spark 与云原生结合的优势
Spark on K8s 原理介绍
1. Spark 的集群部署模式
2. Spark on K8s 的部署架构
3. Spark on K8s 部署架构——对比
4. Spark on K8s 社区进展
5. Spark 3.3 新特性介绍
Spark on K8s 在阿里云 EMR 上的实践
1. EMR Spark on ACK
2. 充分利用云上弹性优势
3. 使用 RSS 优化 shuffle 和动态资源
4. 使用 DLF 构建云上数据湖
5. 易用性提升
Serverless Spark 在阿里云 DLF 的实践
1. DLF 数据探索介绍
2. Serverless Spark SQL 架构
3. Spark Session 管理
4. Livy Server 的优化
5. 其他功能特性
Spark 与云原生的结合

1. 传统 Spark 集群的痛点
① 部署运维难度大
目前我们大家所熟悉的Spark集群都是在传统的 Hadoop 集群内部,比如CDH,或者早期的云上的EMR集群,这种全家桶式的部署方式的好处在于组件比较丰富,但是部署组件繁多,无论是安装、部署、运维都比较复杂,带来比较大的运维和人力成本。
② 弹性能力不足
这种部署模式需要比较固定的资源预估,比如跑作业需要多少 master,多少worker,都要提前准备好,还要事先完成环境的安装和组件的部署。这样,弹性扩容的效率就比较差。
③ 存储与计算耦合
传统 Spark 集群既要部署HDFS 的 data node,也要部署 YARN 的 node manager,这样虽然数据稳定性可能好一些,但是如果存储节点需要扩容的时候,意味着 CPU 和内存也要扩容,有可能会带来一些资源的浪费和使用率的一些问题。

2. Spark 与云原生结合的优势
如果把 Spark 部署在云上,并且能充分利用云原生的特点,可以带来更好的效果。什么是云原生?不同组织对云原生都有一些不同的定义,对于云原生中我们可能接触到像容器化、微服务、DevOps等概念。实际上这些都是技术,但不是云原生的定义。我认为云原生就是代表着通过一些技术可以充分利用到云上的云计算资源和服务的优势,然后高效地在云上部署。因为在云上的部署就代表了在云上的海量资源都可以用到,可以按需使用。Spark 作业可以结合到这些特点,来实现对作业成本和效率的优化。
① 弹性优势
和云原生结合最大特点还是弹性,利用云原生的技术可以实现秒级别的弹性,更细的按量付费。
② 作业为中心
要实现更好的弹性,也意味着环境的部署更敏捷了。比如用容器镜像的技术, Spark 运行环境就是和容器镜像相关,而与集群无关了。作业版本对环境的依赖,都可以通过不同镜像来快速地进行区分,避免很多依赖冲突的问题。
③ 更低运维成本
Spark 运行依赖了很多 Hadoop 的很多组件,但是云上其实有很多这些组件的替代品。比如可以用对象存储 OSS 来替代 HDFS,用 DLF 元数据来去代替 Hive Meta。这些方式都可以减少组件数量,减少部署的复杂度,降低运维成本。
Spark on K8s 原理介绍
接下来具体介绍 Spark 和云原生结合的两种形态。
首先介绍 Spark on K8s,因为 K8s 是云原生的重要代表技术。这个章节将介绍 Spark on K8s 的原理和部署方式。

1. Spark 的集群部署模式
Spark 获取运行时资源是通过 Cluster Manager 的对象的。目前 Spark 官方支持四种部署模式。
① Standalone。比较简单,Spark 不依赖外部调度器,直接就可以独立部署起来。实际中一般在测试用得比较多,很少在生产环境用。
② YARN。就是前面提到的在 Hadoop 集群中跑,这个也是业界最常见的部署模式,大部分 Spark job 也都是跑在 YARN 里面的,生态也比较丰富。
③ Mesos。随着 K8s 的兴起,目前已经比较少有人用了。
④ Kubernetes。把 Spark 作业跑在 K8s 集群里。随着云原生趋势热度比较高,现在也有更多的用户在尝试用这种部署模式跑 Spark 作业。

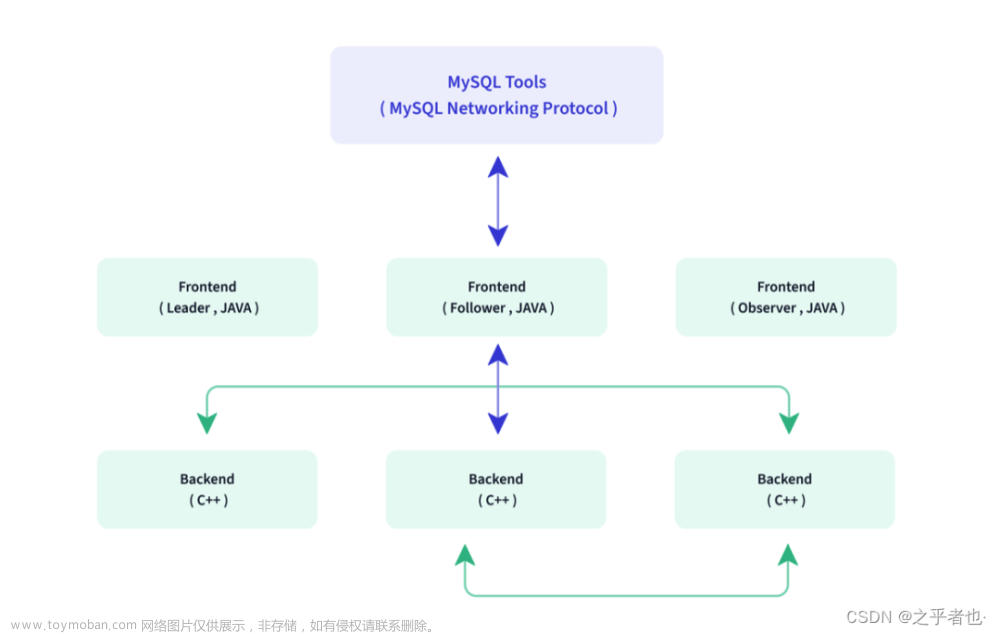
2. Spark on K8s 的部署架构
Spark on K8s 通常会有两种部署模式。
① 使用原生 spark-submit
Spark 官方文档里给出了一个标准的 spark-submit 的方式。这种方式和大家常用的spark-submit 的方式差不多,需要 client 端安装一个 Spark 环境,同时还要装 kubectl,用于连接 K8s 集群。和正常 spark-submit 一样,在提交命令里需要额外指定一下 K8s 的 master 的地址和镜像的地址,这样 Spark 就会自动把作业提交到 K8s 集群里,集群里也不需要装任何的环境配置就可以跑起来。

② 使用 spark-on-k8s-operator
除了官方文档这种方式之外,还有一个 spark-on-k8s-operator 的模式。这个 Spark operator 是 Google 的一个开源项目(链接:https://github.com/GoogleCloudPlatform/spark-on-k8s-operator),它可以让 Spark 作业作为一种 CRD(Custom Resource Definition),用 yaml 的方式来描述,直接提交一个 yaml 文件就能提交 Spark 作业了。这种方式实际上是 spark-submit 官方方式的一种封装而已,但是它更符合我们作为用户的习惯,因为 K8s 其他的对象也都是用这种的 yaml 方式去提交的。
除此之外 operator 也做了一些作业管理能力的增强。比如可以做定时调度、作业监控,以及 pod 增强等等,但这是需要在 K8s 集群里提前安装一个常驻 operator 才能实现的,不像前面的 spark-sumit 的方式不需要常驻服务就可以直接跑起来。

3. Spark on K8s 部署架构——对比
简单对比一下这两种方式。spark-submit 方式是对老用户比较友好,迁移难度比较低,而且交互式作业直接就能跑起来。Spark operator 做了一些完善,在作业管理方面做了很多功能,可以自动去创建 service ingress,可以自动去清理残留的 pod,并且支持重试等等。总体来说就是这两种方式各有利弊。另外我们也提供了一种提交方式,可以结合这两个优点,后面会进行介绍。

4. Spark on K8s 社区进展
Spark 官方在 Spark 2.3 正式支持 native on K8s。之前有人尝试过在 K8s 上用Standalone 或者 YARN 模式来跑,不过都不是 native on K8s,缺点比较多。Spark 2.3 支持之后,在 2.4 有了少量的功能优化,但是真正得到完善是在 Spark 3 之后,Spark on K8s GA 是 Spark 3.1(general available,正式可用,之前都是叫experimental)。如果想要尝试在 K8s 里跑 Spark 还是选择 Spark 3 比较好,因为 Spark 2 功能和稳定性都有些不足,比如 Spark 3 的一个重要特性是支持了 K8s 的 dynamic allocation,另外还支持了自定义 pod template,提升了灵活性。
整体来看,近几年社区里面关于 K8s 有很多新版本发布,说明最近社区在 K8s 还是比较活跃的,越来越多的人在使用这方面的功能。
接下来看一下 Spark 3.3 有哪些关于 K8s 的优化。

5. Spark 3.3 新特性介绍
Spark 3.3 在 K8s 方面主要有两个重点特性发布。
① Executor Rolling in K8s environment
这个 issue 的背景是,Spark 作业运行的时候总是可能会遇到一些慢的 executor,这些慢的 executor 会产生长尾 task,拖慢作业速度。这个现象在流作业更为严重。为什么会有这些慢 executor,可能原因比较多,比如有可能是因为某个机器节点网络环境或者磁盘环境有问题,也有可能有潜在的内存泄漏之类的 bug 等。
为了解决这个问题,它提供了一个叫 executor 的滚动刷新的方式,可以设置刷新的频率,刷新的策略(比如可以结合最近的统计跑 task 最慢的 executor,并重启这些 executor,实现这个 executor 定期地重新拉起)。这样,这些慢 executor 可以通过重启来避免一直拖慢后面的作业。因为重启 executor 对作业可能会有些影响,所以它需要结合 Spark 3 提供的另一个特性——decommissioning,节点优雅下线的特性,既保证这个 executor 能够重启,也不会带来 Stage 重算之类的对作业的干扰。
② Support Customized K8s Schedulers
K8s 默认调度器对大数据批处理不友好,功能上也有比较多的欠缺,比如没有 capacity scheduling。这些大数据调度的功能在 K8s 比较少,因此有一些第三方的调度器提供了增强的能力,比如 YuniKorn、Volcano。为了能够更好的对接这些第三方 K8s 调度器,Spark 社区最近也提供了一个扩展接口和内置的实现类,这样用户可以方便地通过一些 Spark conf 来配置,连上这些第三方调度器,对这个 K8s 环境的调度会有一些比较好的可用性的提升。虽然之前也能用,但是配置起来会较繁琐,现在 Spark 有了内置的支持就会有更好的用户体验。
这些就是近期 Spark 3.3 关于 K8s 方面的主要特性。
Spark on K8s 在阿里云 EMR 上的实践
这一章节将介绍 Spark on K8s 在阿里云上的实践,结合我们云上的一个产品 Spark on ACK,具体介绍我们提供的方案,以及所做的优化。

1. EMR Spark on ACK
在阿里云的公共云上,有一款 EMR on ACK 的产品,其中有一个集群类型是 Spark 集群(后面简称为 Spark on ACK)。顺便提一下,这里的 ACK 是阿里容器服务 K8s 版, ACK 可以理解为 K8s 集群。Spark on ACK 其实提供了一套半托管的大数据平台,帮大家在自己的 K8s 集群里部署好 Spark 运行的环境,提供一些控制台管控之类的功能。
用户首先需要有一个自己的 ACK 集群(K8s 集群),然后平台会在这个集群里面创建一个 Spark 作业的 namespace,并且固定安装一些组件,包括 Spark operator、History Server 等,后续的 Spark 作业的 pod 也会在这个 namespace 下做运行。这些 Spark 作业的 pod 可以是 ACK 节点资源,也可以利用云上的弹性实力(ECI),来实现按量付费。

2. 充分利用云上弹性优势
所谓的这个弹性实例(ECI)是什么?Spark 和云上结合最大的优势就是弹性比较好,可以充分利用云上的资源优势。在阿里云 K8s 环境里有一个弹性容器实例(ECI)的产品,这个产品提供了一个很好的弹性,比如如果要申请 2 核 8G的一个 pod,不再是占用自己机器节点的资源,而是完全用云上的资源帮你来去创建这个 pod,不需要感知机器了。同时可以做到快速拉起(秒级),以及按秒付费等。这样,用 ECI 来跑 Spark 作业很划算,因为通常大家用 Spark 跑批处理任务,峰谷比较明显,有的时候是人群高峰,白天可能查询比较少,这样的场景非常适合搭配这种极致的弹性。这些都可以节省很多成本,性价比非常高。

3. 使用 RSS 优化 shuffle 和动态资源
① Spark Shuffle 在 K8s 环境下的挑战
Shuffle 是 K8s 环境跑 Spark 的另一个挑战,主要有两点:
-
Spark Shuffle 对本地存储的依赖
Spark 作业的数据是需要落盘的,很多大的作业 shuffle 数据量很大(可能到 TB 级别)。在传统化的集群里这个问题到比较好解决,因为节点都会配置比较大的数据盘,和 HDFS 同时使用,所以很少会出现磁盘不够的情况。但是在 K8s 环境就不太一样。K8s 环境可能和其他服务做混合部署,K8s 很多机型没有本地盘,不是专门给大数据用的一些机型,只能利用它们的空闲的 CPU,这个时候作业就很难利用上这些资源。如果 ECI 用弹性实力来跑 Spark,这些实例也没有比较大的数据盘,它只有少量的系统盘,而挂云盘又有性能损失,也不好评估挂多大的云盘比较合适。这个是在本地存储可能会面临的一些问题。
-
不完美的 Dynamic Allocation
Spark 2 官方没有支持 dynamic allocation,Spark 3 GA 之后才支持在 K8s 环境里的dynamic allocation。但是 Spark 3 提供的 shuffle tracking 这个功能的 executor 回收效率比较慢,会带来资源使用的浪费,也不是一个比较完美的方案。这个是环境跑 shuffle 的一个问题。

② Spark Shuffle 本身的不足
另外 Spark Shuffle 本身的算法也有一些不足。在 shuffle write 期间,会按照数据所属Reducer 排序,然后合并成一个文件,这个排序的过程中可能会触发外排,会造成磁盘写放大的一些性能问题。另外,Reducer 是并发拉取 Mapper 端的数据的,Mapper 端读的时候,有很多小碎片随机读,也会影响性能。还有就是 Shuffle 数据一旦丢失就要整个 Stage 重算,尤其在 K8s 环境里还可能会遇到节点驱逐、pod 实例回收这些问题,遇到 executor 挂掉的情况会更为普遍,而一旦挂掉就重算对容错度的影响还是比较大的,对作业的时长也有比较大的影响。

③使用 RSS 优化 shuffle 和动态资源
针对这两类问题,阿里云提供了一个叫做 RSS(Remote Shuffle Service)(链接:https://github.com/alibaba/celeborn)的服务,目前已经在 GitHub 上开源了。原来的 Spark Shuffle 数据是保存在本地磁盘的,用了 RSS 之后,Shuffle 数据就交给 RSS 来管理,executor 直接把数据推给 RSS,本地就不需要占用很大的磁盘空间了。这种用外部 Shuffle Service 的模式在业界已经是一个比较流行的一个共识,很多公司都有在做这方面的优化,只不过 Spark 还没有提供一个官方的方式。
这种做法的优点有很多,不仅仅是性能上的优化,还能解耦前面提到的 executor 对本地盘的依赖,这样各种 pod 的机型都可以跑 Spark 作业了。另外这种方式对动态资源的支持也更好,多副本特性可以保证即使有一些挂掉可能也不会带来 Stage 重算的这些问题等等。

4. 使用 DLF 构建云上数据湖
接下来介绍一下关于 Spark 生态的问题。
在 K8s 上大家不会部署完整的 Hadoop 集群,比如 HDFS,会用对象存储 OSS 来做替代,还有很多其他组件可能用到,比如用 Hive Metadata 保存元数据,用 Sqoop 做数据导入等。在云上构建大数据平台是比较复杂的,Spark 也依赖很多这些组件,这些问题都可以用云上的全托管服务 DLF,它可以提供统一的元数据权限控制,这样 Spark 就不需要自己再维护 Hive Metastore ,可以直接对接 DLF 做元数据管理,免去了很多组建运维的问题,并且用户也可以借此来快速上手,是引擎的一个很好的搭档。

5. 易用性提升
最后介绍一下在 Spark on ACK 作业提交这一侧做的这个优化。
刚才提到有两种作业提交方式,各有优劣,Spark on K8s operator 有比较好的作业管理能力,但是提交作业不兼容老的语法,也不好跑交互式的作业,这样从老集群迁移就比较麻烦。我们提供了一个 CLI 工具,可以直接以 spark-submit 语法来提交 Spark 作业,同时也会记录到 operator 来进行管理,这样就同时享受到了这两种提交方式的优点。
具体原理其实就是在我们在集群提交作业到 Spark Pod 的时候,我们会去反向监听这个Pod 创建,然后再注册回 Spark operator。这里也是用我们内部改造过的 Spark operator 来做这个功能。这对用户来说较大地提升了易用性。
Serverless Spark 在阿里云 DLF 的实践
上面我们介绍了 Spark on K8s 的一些内容。Spark 和云原生结合不一定非要用 K8s,云上也有些 Serverless 的功能,在 Spark 场景下也更加适合。下面这个章节我再介绍一下 Serverless Spark 相关的一些信息。

1. DLF 数据探索介绍
什么是 Serverless Spark?
刚才提到的 Spark on K8s 的形态还是需要用户去感知、运维K8s 集群,是一种半托管的形态。云上 serverless Spark 的形态意味着用户无需要感知任何机器节点,可以直接通过标准的 API 方式提交作业。所谓 Serverless Spark 就是说用户完全不需要买机器了,按作业去付费就可以,这种形态很适合中小型的客户。阿里云 DLF 除了提供之前描述的元数据等等这些湖管理的功能以外,还有一个叫数据探索的功能。这个功能是一个标准的 Serverless Spark SQL,可以用来跑交互式查询。我们只要把数据放到 OSS 上,然后在 DLF 建好表格,就可以直接使用 SQL,并在控制台上进行交互式查询。图中右侧是我们实际的产品截图是一个标准的 SQL 工作台,用户可以直接在这里做一些分析查询。

2. Serverless Spark SQL 架构
接下来介绍一下 Serverless Spark 具体的实现原理。
在架构里,最上层是 DLF-SQL Server,它是一个管控服务,对外提供查询 API,是一个无状态的在线服务。下面一层是利用了 Apache Livy 来去做交互式查询的会话创建和维护,这一层部署在 K8s 环境里,会根据负载扩缩容。最下层 Spark 跑在内部的机器资源池里,阿里云内部有一些统一的资源池,这个资源池是我们和阿里云 Max Compute 共享的机器资源,可以最大程度保障用户资源的需求,对于每个用户的 SQL 查询都会提供独立的 Spark session,这样就意味着它们是不同的 Spark application,可以使隔离性和安全性得到保证。

3. Spark Session 管理
对于交互式查询,我们设计上有几个目标:既要保证用户查询能够快速返回,用户提交的短查询,我们希望至少在几秒一定要能返回。另外也要保证内部资源不要做到浪费。因此我们需要对这些 Spark session 做好管理。
我们把 Livy 拉起的 Spark session 分成了几种类型,一种是我们默认会拉起一些空白会话,并始终维护若干个空白会话,保证用户查询来的时候不在现场创建 Spark 作业,这样,首次查询就会打到已经建好的 Spark session 里了,能够最大限度地提高查询的性能。当用户查询到来的时候,就会从这个空白会话池里选中一个,并标记为这个用户专属的活跃会话,进入活跃会话池。在一段时间之内,如果用户进行一些查询之后不再提交查询了(超时了),我们就会把这个活跃会话从活跃会话池里拿走,自动销毁、自动关闭,避免资源的浪费。这就是我们针对每一个用户查询对应的后台的 Spark Session 的管理和实现。

4. Livy Server 的优化
在 Livy server 这一层,我们也做了一些优化和改进。
首先,每一个 Livy session 默认只能运行一条语句,之后运行的语句都要排队等待。为了提高一些并行度,我们改进了 Livy 的状态管理,搭配 Spark 的 Fair Scheduler,可以支持多条语句并行执行。
同时,为了保证用户首次查询的性能,我们在空白 session 创建之初还会跑一些预热的语句,这样可以提高首次查询的性能。
另外 ,Livy 对查询的报错信息有一些 error 的透出是不全的,默认只取 error 的第一行 message,实际上具体信息可能在 call stack 下方,所以我们会根据一些规则把 call stack 下方的异常也都返回回来,便于用户查询定位等等这些细节。
当然下面还有一些就是我们对分页的支持,对一些扫描量的记录等等,这些是结合我们的具体产品功能做的优化和适配。

5. 其他功能特性
为了保证用户体验,在功能细节上也做了很多配置和优化。比如权限这块,我们对接DLF 权限,用户阿里云子账号登录上来之后,自动去根据用户的子账号去做鉴权,只能查询自己有权限的 table,很适合分析师在阿里云上开几个子账号,分别去做数据分析的这种场景,我们也有一些用户就是这么用的。
另外数据和格式方面,对 Delta、Hudi、IceBerg 这三个我们都提供了内置支持。用户可以直接写 SQL 查询,不需要配额外的参数就能直接查这些数据湖格式的表。这里实现上其实有一些棘手的地方,因为每个湖格式都要配置自己的这个 SQL extension,做 SQL 拦截来去做处理,在配置上三种格式有些场景下会有一些冲突,我们也是在湖格式这个层面做了优化和兼容,保证互操作的顺滑性。文章来源:https://www.toymoban.com/news/detail-791624.html
我们在功能上也提供了后台自动导出,默认内置了一些 TPC-DS 数据,通过映射的方式可以快速创建,这些功能都可以帮帮助大家快速上手,也欢迎大家在 DLF 里直接用这个功能体验一下 Serverless Spark SQL 的能力。文章来源地址https://www.toymoban.com/news/detail-791624.html
到了这里,关于Spark内容分享(二十七):阿里云基于 Spark 的云原生数据湖分析实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!