大语言模型于海量的文本内容上,以无监督和半监督的方式进行训练的
模型微调的目的:使其在具体的使用场景或领域中输出更好的回答
增量预训练——给模型喂新的领域知识;
指令跟随或指令微调——
基于海量的预训练数据训练出来的模型通常叫做——base模型或预训练模型,在没有进行指令微调的模型上进行测试,模型只是单纯的对给定的输入进行在训练数据集上的拟合,而不能意识到在对模型进行提问,为了让模型在测试过程中有更好的表现,需要对基座模型进行指令微调。
指令微调

在对基座模型进行指令微调时,首先需要对训练数据进行角色指定
在给模型投喂的一条数据中,数据由一问一答的形式构成,问题和结果分别指定为user和assistant两个角色,system部分的数据按照自己微调的目标领域来书写,如果想微调一个医疗的ai助手,那system的内容可以为:你是一个专业的医生,你总能输出专业且正确的细致且耐心的这种回答。
在同一次微调,同一个数据集中,system的内容往往由于目标的唯一性,是确定的
以上的内容为 对话模板的构建

在与模型进行对话的过程中(部署的阶段),用户不需要进行角色的分配,用户输入的内容被默认放入user的部分,system部分由模板自动添加,具体的模板在启动预测的时候可以进行自定义,计算损失时,只需要进行assistant部分的损失
指令微调的原理

增量预训练微调

进行指令微调的过程中,每条数据都由一问一答的形式构成,但增量训练的数据不需要问题,只需要回答,或者说增量训练的数据,都是一个一个的陈述句,所以每一条训练的数据中system和user的部分只需要留空,增量训练的数据放入到assistant中即可,计算损失时也只需要计算assistant的部分的损失
X Turner中使用的原理——LoRA和QLoRA

使用LoRA的理由——如果对整个模型的所有参数进行调整,需要非常大的显存才能训练,而LoRA不需要非常大的显存开销
LoRA是一种在原有的模型的线路旁,新增一个旁路分支Adapter,该分支包含两个小的部分(LoRA模型文件 指的就是旁路分支Adapter文件)
QLoRA是对LoRA的一种改进
全参数微调,LoRA和QLoRA的对比
全参数微调和LoRA微调,模型的参数都需要先加载到显存中,但对LoRA,其参数优化器只需要保存LoRA部分的参数优化器即可;而QLoRA,在加载模型时,就使用4比特量化的方式加载,其优化器也可以在cpu和gpu之间进行调度,即若显存满了,就自动在内存中跑文章来源:https://www.toymoban.com/news/detail-791652.html
XTuner



一些trick的训练策略文章来源地址https://www.toymoban.com/news/detail-791652.html
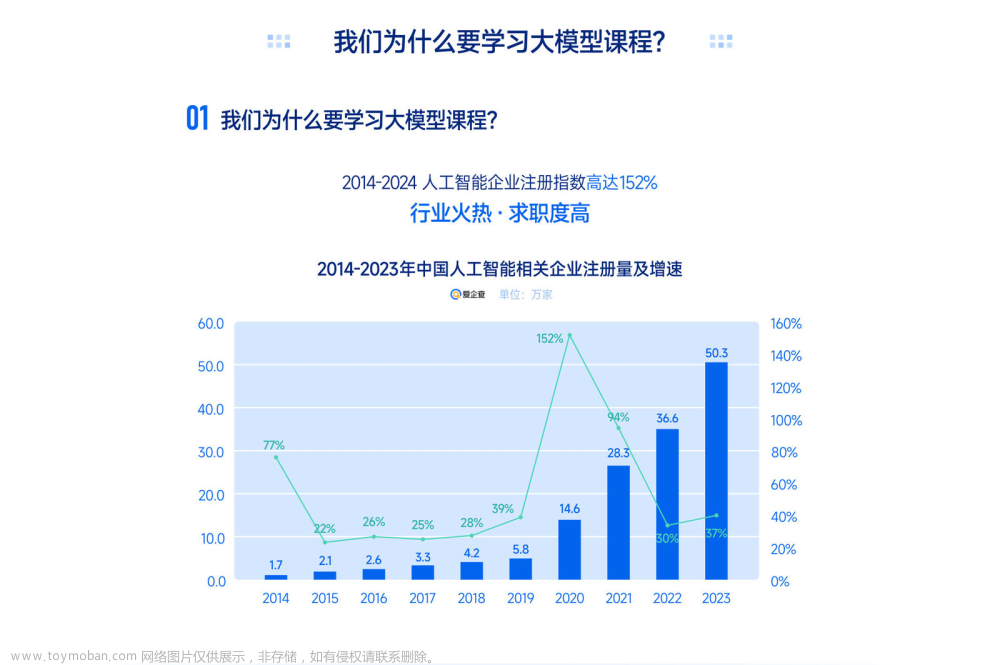
到了这里,关于XTuner 微调 课程学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![北大肖臻老师《区块链技术与应用》系列课程学习笔记[25]以太坊-智能合约-5](https://imgs.yssmx.com/Uploads/2024/03/838544-1.png)



