1.inet_init是如何被调用的?从start_kernel到inet_init调用路径
从调用栈中可以看到inet_init被调用的过程
start_kernel
|
rest_init
|
kernel_init
|
kernel_init_freeable
|
do_basic_setup
|
do_initcalls
|
inet_init()- start_kernel函数位于
init/main.c中,是内核的入口位置,它在系统引导过程中被调用。执行该函数后,内核初始化各种子系统,包括调度器、内存管理、文件系统等。在函数最后,会调用rest_init函数来继续剩余的初始化工作。 - 在rest_init函数中,内核启动了一个新线程
kernel_init负责系统的进一步初始化,之后执行kernel_init_freeable完成了需要在分配自由内存之前的完成的初始化任务。然后内核调用内置的do_basic_setup函数实现对各种设备和驱动的初始化。随后调用do_basic_setup函数,负责完成编译时的注册操作。这些初始化函数在执行时按照定义的顺序按序执行。 - inet_init函数位于net/ipv4/af_inet.c中,其作为网络子系统初始化的一部分,也是一个初始化调用,负责初始化整个IPv4协议族,包括TCP、UDP等。
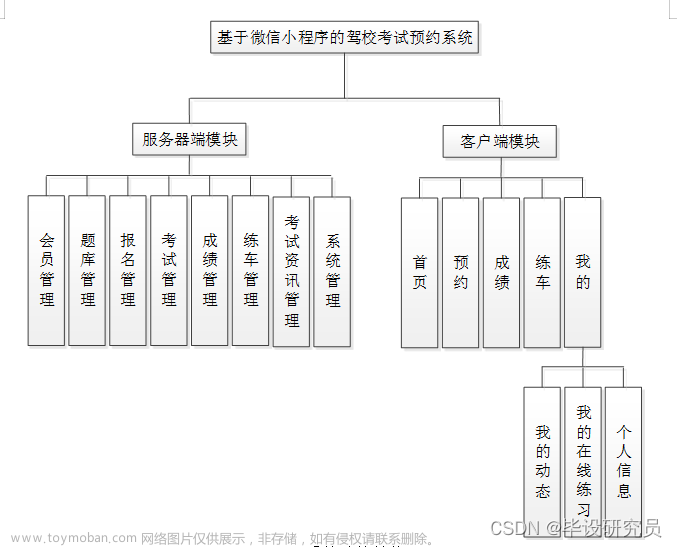
2.跟踪分析TCP/IP协议栈如何将自己与上层套接口与下层数据链路层关联起来的?
1)TCP/IP协议栈与上层套接口的关联
在Linux内核中,套接字接口(Sockets)提供了应用程序与网络协议栈之间的接口。应用程序通过调用如socket()的系统调用创建套接字。这个调用最终会在内核中被定向到相应的协议族的套接字创建函数。而每个协议簇在内核中有一个对应的结构体,其中包含了用于处理套接字调用的函数指针。这些函数处理网络操作,例如创建新套接字、数据发送接收、连接管理等。之后就是数据的发送与接收,应用层数据的发送和接收都是通过套接字接口进行的。数据在从应用层传输到协议栈时,会根据套接字的类型被封装成TCP或UDP数据包。
2)TCP/IP协议栈与下层数据链路层的关联
在网络数据包被发送或接收时,TCP/IP协议栈与数据链路层的关联起着至关重要的作用。当上层(如TCP或UDP)生成了一个数据包后,它需要通过网络层进一步封装,然后传输到数据链路层。这一过程涉及添加IP头部,并确定如何通过网络路由数据包。数据链路层通过网络接口与物理网络连接。每个网络接口在内核中都有一个对应的结构体,其中包含了用于发送和接收数据帧的函数。此外,在数据链路层中IP数据包被进一步封装成适合于特定物理媒介的帧。例如,在以太网中,这包括添加以太网头部,其中包含MAC地址等信息。
3.TCP的三次握手源代码跟踪分析,跟踪找出设置和发送SYN/ACK的位置,以及状态转换的位置
TCP三次握手主要发生在TCP状态机中,涉及SYN的发送、SYN/ACK的接收与发送,以及最终的ACK的发送。
1)发送SYN
当客户端开始一个TCP连接时,它首先发送一个SYN包。这一过程在tcp_connect函数中实现,该函数位于net/ipv4/tcp_output.c文件中。
int tcp_connect(struct sock *sk)
{
//创建SYN信号,并发送出去
}2)接收SYN并发送SYN/ACK
服务端在收到SYN包后,需要发送一个SYN/ACK包作为响应。这部分处理在tcp_v4_syn_recv_sock函数中实现,该函数位于net/ipv4/tcp_ipv4.c文件中。该函数处理接收到的SYN包,并准备发送SYN/ACK。它设置SYN和ACK标志位,并将服务端的TCP状态设置为TCP_SYN_RECV。
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req){
//三次握手完成,我们得到了一个有效的synack,现需要创建新的套接字
}3)接收SYN/ACK并发送ACK
客户端接收到服务端的SYN/ACK响应后,需要发送一个ACK包来完成三次握手。这部分代码在tcp_rcv_state_process函数中实现,位于net/ipv4/tcp_input.c文件中。在状态为TCP_SYN_SENT时接收到SYN/ACK,客户端通过这个函数发送ACK响应,并将状态转换为TCP_ESTABLISHED。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb){
//接收SYN/ACK,并发送ACK响应,随后变更状态为:TCP_ESTABLISHED
}4)状态转换
TCP的状态转换在tcp_set_state函数中处理,这个函数负责根据当前的事件和接收到的TCP段来更新TCP连接的状态。该函数位于net/ipv4/tcp.c文件中。
void tcp_set_state(struct sock *sk, int state){
//根据不同的情况和接收到的数据来更新连接的状态
}4.send在TCP/IP协议栈中的执行路径
在Linux内核中,当应用程序调用send函数发送数据时,数据会经过TCP/IP协议栈的多个层次最终被发送到网络上。以下是send函数在TCP/IP协议栈中的执行路径:
1)应用层
网络应用调用Socket API socket创建一个 socket,最终调用 sock_create() 方法,返回被创建好了的那个 socket 的 描述符。
对于 TCP socket ,应用调用 connect()函数,使客户端和服务器端通过该 socket 建立一个连接。建立连接之后然后可以调用send函数发出一个 message 给接收端。sock_sendmsg 被调用,调用相应协议的发送函数。
2)传输层
先调用tcp_sendmsg 函数,把用户层的数据填充到skb中。在tcp_sendmsg_locked中,将数据整理成发送队列,数据创建之后调用tcp_push()来发送,tcp_push函数调用tcp_write_xmit()函数,将调用发送函数tcp_transmit_skb,所有的SKB都经过该函数进行发送。最后进入到ip_queue_xmit到网络层。
3)网络层
ip_queue_xmit(skb)会检查skb->dst路由信息,如果没有则使用ip_route_output()选择一个路由。填充IP包的各个字段,比如版本、包头长度、TOS等。ip_fragment 函数进行分片,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
4)数据链路层
数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。从dev_queue_xmit函数开始,位于net/core/dev.c文件中。
5.recv在TCP/IP协议栈中的执行路径
当应用程序调用recv系统调用来接收TCP数据时,数据会经过TCP/IP协议栈的多个层次。
1)应用层
应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
TCP 调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
2)传输层
tcp_v4_rcv函数为TCP的总入口,数据包从IP层传递上来,进入该函数,其中handler设置为tcp_v4_rcv,tcp_v4_rcv函数作用:设置TCP_CB、 查找控制块、根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理、TCP_LISTEN状态处理、接收TCP段
3)网络层
IP层的入口函数在 ip_rcv 函数,然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
ip_rcv_finish 函数会调用ip_route_input函数,进入路由处理环节。会调用 ip_route_input 来更新路由,然后查找 route,决定该会被发到本机还是会被转发还是丢弃。如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment,然后调用 ip_local_deliver 函数。如果需要转发 ,则进入转发流程,调用 dst_input 函数。
4)数据链路层
物理网络适配器接收到数据帧时,会触发一个中断,并将通过 DMA 传送到位于 linux kernel 内存中的 rx_ring。终端处理程序经过简单处理后,发出一个软中断,通知内核接收到新的数据帧,进入软中断处理流程,调用 net_rx_action 函数。包从 rx_ring 中被删除,进入 netif _receive_skb ,netif_receive_skb根据注册在全局数组 ptype_all 和 ptype_base 里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数。
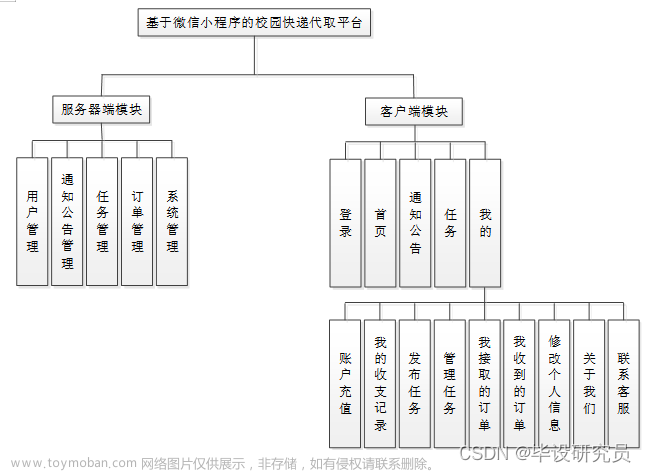
6.路由表的结构和初始化过程
路由表的结构和初始化过程是网络子系统的关键组成部分。路由表用于存储和检索路由信息,使得内核能够决定如何将网络数据包转发到正确的目的地。
路由表在Linux内核中通常由几个关键的数据结构组成:
rtable结构体,位于include/net/route.h中,用于表示IPv4路由表中的一个条目。该结构体中包含目的地址、子网掩码、网关、相关接口等信息。fib_info结构体,位于include/net/ip_fib.h中,代表了路由表中的一个"前向信息库"(FIB)条目。该结构体中包含包含路由策略、下一跳信息等。fib_table结构体,代表了一个特定的路由表,可以有多个fib_table实例,对应不同的路由表。
路由表的初始化过程如下所示:
在内核启动过程中的 inet_init函数中触发。初始化包括创建和设置默认的路由表,这是通过 ip_rt_init 函数完成的,该函数位于net/ipv4/route.c。在这个函数中,内核配置必要的数据结构,如路由缓存和默认路由表,并建立相关的钩子和接口,以便其他内核部分可以添加、删除或修改路由条目。这一初始化步骤确保了内核能够正确地处理传入和传出的网络数据包,根据路由表中的信息将它们转发到正确的目的地。
7.通过目的IP查询路由表的到下一跳的IP地址的过程
ib_lookup函数作为路由策略数据库的主要查询接口,负责根据目的IP地址查找下一跳的IP地址。这个过程首先涉及搜索策略表以找到匹配的路由策略。一旦找到合适的策略,fib_lookup 接着查询与该策略关联的路由表。
在路由表查找中,fib_lookup 调用 fn_hash_lookup 函数来处理实际的查找任务。这个过程会遍历路由表中的条目,寻找与目的IP地址相匹配的路由项。根据查找的结果,一般会有两种处理情况:数据包的转发和本地处理。无论是哪一种情况,都通常涉及首先分配一个新的路由缓存节点。这个新节点会被填充适当的路由信息,然后插入到路由缓存中,以便加速后续的路由查找。
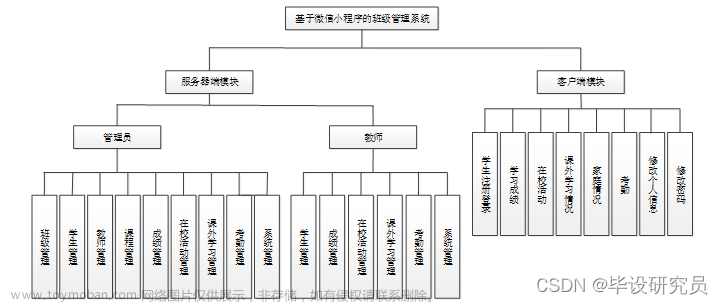
8.ARP缓存的数据结构及初始化过程,包括ARP缓存的初始化
ARP缓存的书数据结构主要有:neighbour 结构体、neigh_table 结构体、arp_queue 结构体。
- ARP缓存的主要数据结构是
neighbour结构体,它表示一个ARP表项,包含了IP地址和对应的MAC地址等信息。该结构位于include/net/neighbour.h。
struct neighbour {
struct neighbour __rcu *next;
struct neigh_table *tbl;
struct neigh_parms *parms;
unsigned long confirmed;
unsigned long updated;
rwlock_t lock;
refcount_t refcnt;
unsigned int arp_queue_len_bytes;
struct sk_buff_head arp_queue;
struct timer_list timer;
unsigned long used;
atomic_t probes;
__u8 flags;
__u8 nud_state;
__u8 type;
__u8 dead;
u8 protocol;
seqlock_t ha_lock;
unsigned char ha[ALIGN(MAX_ADDR_LEN, sizeof(unsigned long))] __aligned(8);
struct hh_cache hh;
int (*output)(struct neighbour *, struct sk_buff *);
const struct neigh_ops *ops;
struct list_head gc_list;
struct rcu_head rcu;
struct net_device *dev;
u8 primary_key[0];
} __randomize_layout;- ARP缓存表由
neigh_table结构体表示,其内包含了一系列的neighbour实例,并提供了查找、插入和删除映射的功能。该结构位于include/net/neighbour.h。
struct neigh_table {
int family;
unsigned int entry_size;
unsigned int key_len;
__be16 protocol;
__u32 (*hash)(const void *pkey,
const struct net_device *dev,
__u32 *hash_rnd);
bool (*key_eq)(const struct neighbour *, const void *pkey);
int (*constructor)(struct neighbour *);
int (*pconstructor)(struct pneigh_entry *);
void (*pdestructor)(struct pneigh_entry *);
void (*proxy_redo)(struct sk_buff *skb);
int (*is_multicast)(const void *pkey);
bool (*allow_add)(const struct net_device *dev,
struct netlink_ext_ack *extack);
char *id;
struct neigh_parms parms;
struct list_head parms_list;
int gc_interval;
int gc_thresh1;
int gc_thresh2;
int gc_thresh3;
unsigned long last_flush;
struct delayed_work gc_work;
struct timer_list proxy_timer;
struct sk_buff_head proxy_queue;
atomic_t entries;
atomic_t gc_entries;
struct list_head gc_list;
rwlock_t lock;
unsigned long last_rand;
struct neigh_statistics __percpu *stats;
struct neigh_hash_table __rcu *nht;
struct pneigh_entry **phash_buckets;
};- 当ARP请求发送后等待响应时,相关的数据包会暂时存储在
arp_queue结构体中,其确保了数据包在等待MAC地址解析期间不会丢失。
ARP缓存初始化过程如下所示:
1)网络子系统初始化:在Linux内核启动过程中,网络子系统的初始化是由 inet_init 函数触发的。
2)ARP表初始化:ARP表的初始化通常发生在网络接口初始化过程中,具体操作包括:分配 neigh_table 结构体,设置其参数,以及创建用于管理ARP表项的哈希表。
3)初始化函数:通过arp初始化函数创建ARP表,并配置ARP请求的重试次数、超时等参数。
4)注册协议族:ARP缓存的初始化还包括在协议族中注册ARP处理函数,确保ARP请求和响应可以被正确处理。
9.如何将IP地址解析出对应的MAC地址
当内核需要解析一个IP地址对应的MAC地址时,比如在尝试向一个尚未知MAC地址的目标IP地址发送数据包时,它首先会构建一个ARP请求。此时需要arp_send函数(位于 net/ipv4/arp.c)建一个包含请求者的IP和MAC地址,以及目标IP地址的ARP请求数据包。
void arp_send(int type, int ptype, __be32 dest_ip,
struct net_device *dev, __be32 src_ip,
const unsigned char *dest_hw, const unsigned char *src_hw,
const unsigned char *target_hw)
{
arp_send_dst(type, ptype, dest_ip, dev, src_ip, dest_hw, src_hw,
target_hw, NULL);
}
EXPORT_SYMBOL(arp_send);当一个设备收到ARP请求,并识别出请求中的目标IP地址与自己的IP地址相匹配时,它会发送一个ARP响应。在Linux内核中,接收和处理ARP响应的逻辑通常在 arp_rcv(位于 net/ipv4/arp.c)函数中实现。该函数负责处理接收到的ARP包,如果是针对本机的ARP请求,则会发送一个包含本机MAC地址的ARP响应。
static int arp_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt, struct net_device *orig_dev)
{
const struct arphdr *arp;
/* do not tweak dropwatch on an ARP we will ignore */
if (dev->flags & IFF_NOARP ||
skb->pkt_type == PACKET_OTHERHOST ||
skb->pkt_type == PACKET_LOOPBACK)
goto consumeskb;
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb)
goto out_of_mem;
/* ARP header, plus 2 device addresses, plus 2 IP addresses. */
if (!pskb_may_pull(skb, arp_hdr_len(dev)))
goto freeskb;
arp = arp_hdr(skb);
if (arp->ar_hln != dev->addr_len || arp->ar_pln != 4)
goto freeskb;
memset(NEIGH_CB(skb), 0, sizeof(struct neighbour_cb));
return NF_HOOK(NFPROTO_ARP, NF_ARP_IN,
dev_net(dev), NULL, skb, dev, NULL,
arp_process);
consumeskb:
consume_skb(skb);
return NET_RX_SUCCESS;
freeskb:
kfree_skb(skb);
out_of_mem:
return NET_RX_DROP;
}发起ARP请求的设备在收到ARP响应后,会通过neigh_update函数更新其ARP缓存表,将目标IP地址与响应中的MAC地址关联起来。该函数位于 include/net/neigh.h中。
int neigh_update(struct neighbour *neigh, const u8 *lladdr, u8 new,
u32 flags, u32 nlmsg_pid)
{
return __neigh_update(neigh, lladdr, new, flags, nlmsg_pid, NULL);
}
EXPORT_SYMBOL(neigh_update);10.跟踪TCP send过程中的路由查询和ARP解析的最底层实现
TCP发送过程中的路由查询是通过调用fib_lookup函数实现的。该函数会遍历路由表并根据目的IP地址查找最佳的路由路径。在查找过程中,会考虑多种因素,如目标网络的掩码长度、路径的成本等。最终选择一条最佳的路由路径用于数据包的发送。
在TCP发送过程中,如果目的地在同一局域网内,将进行ARP解析以获取目的地的MAC地址。ARP解析涉及发送ARP请求,并等待接收ARP响应。这是通过 arp_send 函数来发送ARP请求,而接收到的响应由 arp_rcv 函数处理。收到的MAC地址被存储在ARP缓存中,该缓存中的IP到MAC的映射关系由 neighbour 结构体表示。当需要解析IP地址时,系统首先检查ARP缓存。如果缓存中存在相应的记录,就直接使用;如果不存在,则发送ARP请求进行解析。
这些过程中的函数和数据结构协同工作,构成了TCP发送过程中路由查询和ARP解析的基础机制。这些机制确保了TCP数据包能够有效地定位到正确的网络路径和物理地址,从而完成网络通信文章来源:https://www.toymoban.com/news/detail-791795.html
总结
通过学习孟宁老师的网络程序设计这门课程,我学习到了Javascript网络编程、Socket API、网络协议设计及RPC、Linux内核网络协议栈这四个方向的相关知识,并通过课程仓库中的相关实验进一步加深对上述知识的理解。最后,十分感谢孟宁老师对我们的辛勤付出,让我在今后的学习中明确了前进的方向。文章来源地址https://www.toymoban.com/news/detail-791795.html
到了这里,关于网络程序设计:TCP/IP协议栈源代码分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!