12.4 Java与线程
12.4.1 线程的实现
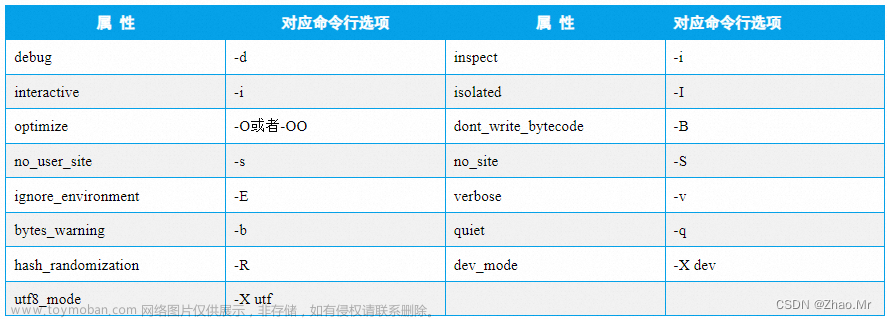
实现线程主要有三种方式:使用内核线程实现(1: 1 实现),使用用户线程实现(1: N 实现),使用用户线程加轻量级进程混合实现(N: M 实现)。
1.内核线程实现
使用内核线程实现的方式也被称为 1: 1 实现。内核线程(Kernel-Level Thread,KLT)就是直接由操作系统内核(Kernel,下称内核)支持的线程,这种线程由内核来完成线程切换,内核通过操纵调度器( Scheduler)对线程进行调度,并负责将线程的任务映射到各个处理器上。每个内核线程可以视为内核的一个分身,这样操作系统就有能力同时处理多件事情,支持多线程的内核就称为多线程内核(Multi-Threads Kernel)。
程序一般不会直接使用内核线程,而是使用内核线程的一种高级接口——轻量级进程(Light Weight Process, LWP),轻量级进程就是我们通常意义上所讲的线程,由于每个轻量级进程都由一个内核线程支持,因此只有先支持内核线程,才能有轻量级进程。这种轻量级进程与内核线程之间 1: 1 的关系称为一对一的线程模型。
轻量级线程的局限性:
- 由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态( UserMode)和内核态(Kernel Mode)中来回切换
- 每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。
2.用户线程实现
广义上来讲,一个线程只要不是内核线程,都可以认为是用户线程(User Thread, UT)的一种,因此从这个定义上看,轻量级进程也属于用户线程,但轻量级进程的实现始终是建立在内核之上的,许多操作都要进行系统调用,因此效率会受到限制,并不具备通常意义上的用户线程的优点。
狭义上的用户线程指的是完全建立在用户空间的线程库上,系统内核不能感知到用户线程的存在及如何实现的。如果程序实现得当,这种线程不需要切换到内核态。
Java、 Ruby 等语言都曾经使用过用户线程,最终又都放弃了使用它。但是近年来许多新的、以高并发为卖点的编程语言又普遍支持了用户线程,譬如 Golang、 Erlang 等,使得用户线程的使用率有所回升。
3.混合实现
线程除了依赖内核线程实现和完全由用户程序自己实现之外,还有一种将内核线程与用户线程一起使用的实现方式,被称为 N: M 实现。
4.Java线程的实现
从 JDK 1.3 起, “主流”平台上的“主流”商用Java 虚拟机的线程模型普遍都被替换为基于操作系统原生线程模型来实现,即采用 1: 1的线程模型。也就是轻量级线程?
以 HotSpot 为例,它的每一个 Java 线程都是直接映射到一个操作系统原生线程来实现的,而且中间没有额外的间接结构,所以 HotSpot 自己是不会去干涉线程调度的(可以设置线程优先级给操作系统提供调度建议),全权交给底下的操作系统去处理,所以何时冻结或唤醒线程、该给线程分配多少处理器执行时间、该把线程安排给哪个处理器核心去执行等,都是由操作系统完成的,也都是由操作系统全权决定的。
12.4.2 Java线程调度
线程调度是指系统为线程分配处理器使用权的过程,调度主要方式有两种,分别是协同式(Cooperative Threads-Scheduling)线程调度和抢占式( Preemptive ThreadsScheduling)线程调度。
Java是抢占式调度。
12.4.3 状态转换
Java 语言定义了 6 种线程状态,在任意一个时间点中,一个线程只能有且只有其中的一种状态,并且可以通过特定的方法在不同状态之间转换。这 6 种状态分别是:
- 新建(New):创建后尚未启动的线程处于这种状态。
- 运行(Runnable):包括操作系统线程状态中的 Running 和 Ready,也就是处于此状态的线程有可能正在执行,也有可能正在等待着操作系统为它分配执行时间。
- 无限期等待(Waiting):包括操作系统线程状态中的 Running 和 Ready,也就是处于此状态的线程有可能正在执行,也有可能正在等待着操作系统为它分配执行时间。
- 没有设置 Timeout 参数的 Object::wait()方法;
- 没有设置 Timeout 参数的 Thread::join()方法;
- LockSupport::park()方法
- 限期等待(Timed Waiting):处于这种状态的线程也不会被分配处理器执行时间,不过无须等待被其他线程显式唤醒,在一定时间之后它们会由系统自动唤醒。以下方法会让线程进入限期等待状态:
- Thread::sleep()方法;
- 设置了 Timeout 参数的 Object::wait()方法;
- 设置了 Timeout 参数的 Thread::join()方法;
- LockSupport::parkNanos()方法;
- LockSupport::parkUntil()方法
- 阻塞(Blocked):线程被阻塞了, “阻塞状态”与“等待状态”的区别是“阻塞状态”在等待着获取到一个排它锁,这个事件将在另外一个线程放弃这个锁的时候发生;而“等待状态”则是在等待一段时间,或者唤醒动作的发生。在程序等待进入同步区域的时候,线程将进入等待这种状态。
- 结束(Terminated):已终止线程的线程状态,线程已经结束执行。

12.5 Java与协程
12.5.1 内核线程的局限
Java 目前的并发编程机制就与上述架构趋势产生了一些矛盾, 1: 1 的内核线程模型是如今 Java 虚拟机线程实现的主流选择,但是这种映射到操作系统上的线程天然的缺陷是切换、调度成本高昂,系统能容纳的线程数量也很有限。以前处理一个请求可以允许花费很长时间在单体应用中,具有这种线程切换的成本也是无伤大雅的,但现在在每个请求本身的执行时间变得很短、数量变得很多的前提下,用户线程切换的开销甚至可能会接近用于计算本身的开销,这就会造成严重的浪费。
12.5.2 协程的复苏
内核线程的调度成本比较高,主要来自于用户态与核心态之间的状态转换,而这两种状态转换的开销主要来自于响应中断、保护和恢复执行现场的成本。
一个例子:
线程 A->系统中断->线程 B
处理器要去执行线程 A 的程序代码时,并不是仅有代码程序就能跑得起来,程序是数据与代码的组合体,代码执行时还必须要有上下文数据的支撑。**而这里说的“上下文”,以程序员的角度来看,是方法调用过程中的各种局部的变量与资源;以线程的角度来看,是方法的调用栈中存储的各类信息;而以操作系统和硬件的角度来看,则是存储在内存、缓存和寄存器中的一个个具体数值。**物理硬件的各种存储设备和寄存器是被操作系统内所有线程共享的资源,当中断发生,从线程 A 切换到线程 B 去执行之前,操作系统首先要把线程 A 的上下文数据妥善保管好,然后把寄存器、内存分页等恢复到线程 B 挂起时候的状态,这样线程 B 被重新激活后才能仿佛从来没有被挂起过。这种保护和恢复现场的工作,免不了涉及一系列数据在各种寄存器、缓存中的来回拷贝,当然不可能是一种轻量级的操作。
当然协程也是不可避免这些开销的,但是如何实现就在程序员手中了,就可以做各种的优化。
由于最初多数的用户线程是被设计成协同式调度(Cooperative Scheduling)的,所以它有了一个别名——“协程”(Coroutine)。又由于这时候的协程会完整地做调用栈的保护、恢复工作,所以今天也被称为“有栈协程”(Stackfull Coroutine),起这样的名字是为了便于跟后来的“无栈协程”(Stackless Coroutine)区分开。
协程的主要优势是轻量,无论是有栈协程还是无栈协程,都要比传统内核线程要轻量得多。文章来源:https://www.toymoban.com/news/detail-792190.html
12.5.3 Java的解决方案
还在实验阶段。文章来源地址https://www.toymoban.com/news/detail-792190.html
到了这里,关于第十二章 Java内存模型与线程(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![C国演义 [第十二章]](https://imgs.yssmx.com/Uploads/2024/02/581669-1.png)