作者:高玉涵
时间:2024.1.11 08:30
博客:blog.csdn.net/cg_i
环境:Windows 10 专业版 22H2、Python 3.10.4、selenium 4.10.0
前言
在 WEB 功能测试领域,Selenium 是一个免费、开源、跨平台的重要工具,它可以对 Chrome、Firefox、Safari 等浏览器进行测试,支持多种语言(如 Python、Java、C#、Ruby、JavaScript 等),它足以胜任一切 WEB 功能测试任务。优点:它可以模拟浏览器,打开你需要爬取的网站,可以大概率避免被封。因为我们用 Python 的 requets 库时,有些反爬严格的网站,可以识别出你当前访问是机器,导致爬取数据失败。缺点:速度慢。因为 Selenium 必须要打开浏览器,然后模拟点击网页,这个过程和你打开浏览器访问网站一样的速度。
然而,工具本质上只是工具,并不能真正发挥价值。要让 Selenium 在爬取数据中发挥真正功能,不仅需要有强大工具,还需有有效的策略。下面我会给出一个虚构的需求,通过简单举例自动化登录 SOHU 邮箱,浅尝辄止的介绍如何使用 Selenium,方便让你了解其价值,希望大家能从中有所收获。当然,限于本人水平有限,文中举例难免会有疏漏或不当之处,敬请广大读者及同行批评指正,谢谢各位!
一、背景知识
Selenium 4
Selenium 是一系列基于 Web 的自动化工具。它提供了一系统操作函数,用于支持 Web 自动化。这些函数非常灵活,能够通过多种方式定位界面元素、操作元素并获取元素的各项信息。Selenium 2 开始引入了 WebDriver,由浏览器厂商基于一定规范提供原生级别的操作实现,就相当于用户在真实操作浏览器。时至今日,Selenium 4,已经非常成熟,本文示例采用此版本。
Selenium WebDriver
是一种简洁而紧密的编程接口,可以通过多种编程语言(例如 Python、Java、C#、Ruby等)来调用 WebDriver。支持全部主流浏览器:例如 Firefox、Safari、Edge、Chrome 及 Internet Explorer 等,在这些浏览器中的自动化操作等同于按真实用户的方式进行交互。WebDriver 标准是 W3C 标准:主要的浏览器厂商(Mozilla、Google、Apple、Microsoft等)都支持 WebDriver 标准,将据此优化浏览器及开发控制代码(可将控制代码称为驱动程序,各个浏览器拥有自身的 WebDriver 驱动程序)提供更统一的原生操作支持,使自动化脚本更加稳定。
二、Selenium WebDriver 的安装与配置
浏览器的安装很简单,这里不做过多说明,主要介绍驱动程序和语言(Python)绑定的安装与配置。对不同的浏览器,需要下载浏览器驱动程序来支持运行。这里主要以 Goolge Chrome 浏览器举例。
2.1 下载 Chrome 浏览器的驱动程序
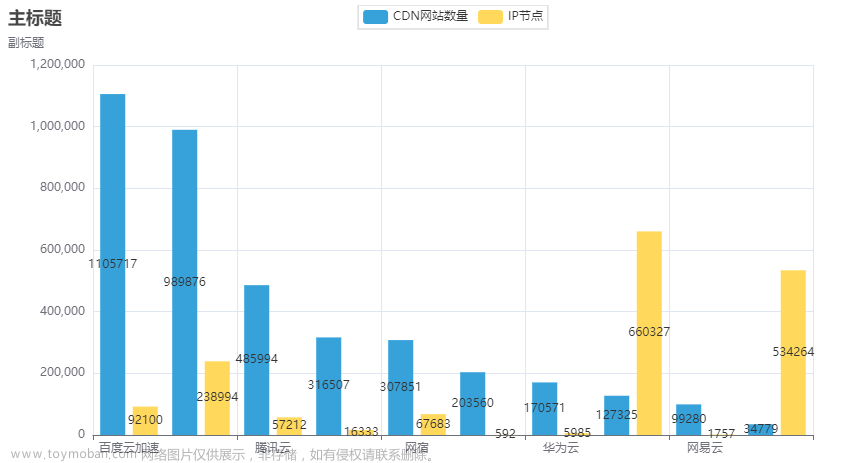
在 Chrome 浏览器中,首先在“帮助 ”->”关于 Google Chrome“菜单中查看浏览器版本,在本例中版本号为 120.0.6099.201,如图 2-1 所示。

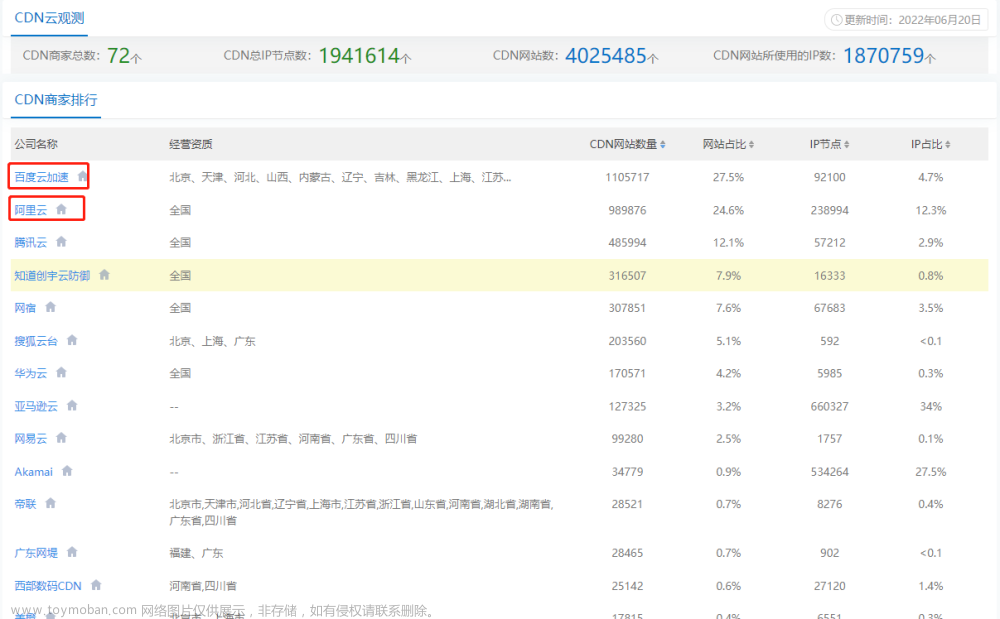
然后访问 Chrome 浏览器的驱动程序下载页面 CNPM Binaries Mirror (npmmirror.com),找到对应版本的文件夹,如图 2-2 所示。

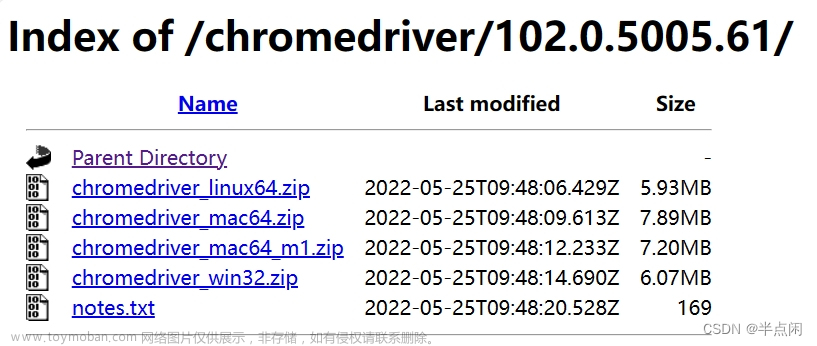
进入对应版本的文件夹,根据操作系统下载对应的驱动程序即可,如图 2-3 所示。
2.2 配置环境变量
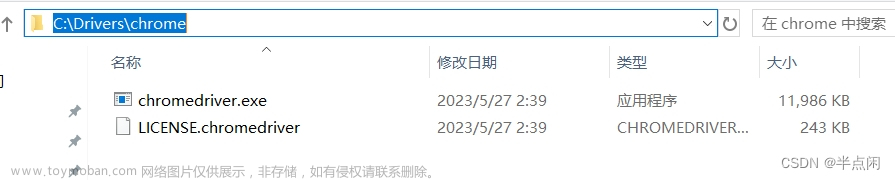
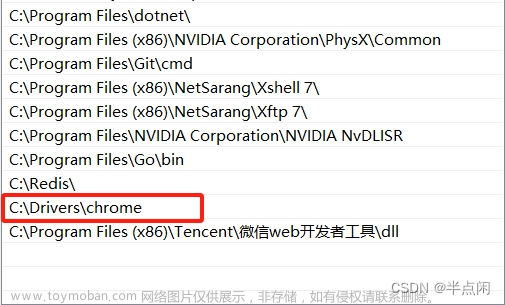
驱动下载完成后,建议将驱动程序的 exe 文件放在同一个文件夹下进行管理,可按图 2-4 所示。本例中存放路径为 C:\Drivers\chrome。
然后还需要将文件夹配置到环境变量 Path 当中,这样 Selenium 在运行时,就可以通过环境变量 Path 找到驱动程序所在位置。
在”设置“,选择”关于“,找到单击”高级系统设置“,在弹出的”系统属性“对话框中单击”环境变量“按键。在弹出的”环境变量“对话框中,在”系统变量“选项组中,选择 Path 变量,将 C:\Drivers\chrome 添加到环境变量 Path 当中,如图 2-5 所示。
浏览器驱动程序的配置到此完成。
三、Python 安装 Selenium
在命令行窗口中输入以下命令,即可完成针对 Python 的 Selenium 库的安装。
pip install selenium
安装完成后,可以通过以个命令查看安装的版本。
pip show selenium
Name: selenium
Version: 4.10.0
Summary:
Home-page: https://www.selenium.dev
Author:
Author-email:
License: Apache 2.0
Location: c:\python310\lib\site-packages
Requires: certifi, trio, trio-websocket, urllib3
Required-by:
语言绑定安装完成后,就可以开始编写 Selenium 的相关代码了。
四、页面元素定位
4.1 选择浏览器开始测试
在此之前,我们已经配置了浏览器的驱动程序,因此可以在代码中声明 WebDriver 实例,来运行浏览器。
from selenium import webdriver
driver = webdriver.Chrome()
执行以上代码,将打开 Chrome 浏览器。
4.2 查找页面元素
4.2.1 浏览器查找元素
在进行操作之前,必须要找到相应的元素。如何才能找到这些元素?首先打开浏览器,地址栏输入 https://mail.sohu.com/fe/#/login 登录搜狐邮箱页面。 如图 4-1 所示。
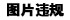
登录时,需要提供邮箱和密码。可以通过查找“请输入您的邮箱”、”请输入您的密码“来定位元素 HTML 标签位置。按下 F12 打开”开发人员工具”选中“元素”按 Ctrl+F 在查找输入框中输入“请输入您的邮箱”,如图 4-2 所示。
重复上述方法依次找到登录邮箱用到的元素。
4.2.2 按 XPath 查找
XPath 的全称为 XML 路径语言(XML Path Language),它是一种用来确定目标对象在 XML 文档中的位置的语言。XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的计算机文件系统中看到的表达式非常相似。由于 HTML 和 XML 的结构非常相似,因此 XPath 可以用于 HTML 节点的选取。通过 XPath 表达式,几乎可以选取任何相要的节点。
在 Selenium 中,可以通过以下函数查找匹配 XPath 表达式的首个元素。
find_element(By.XPATH, "//*[@placeholder='请输入您的邮箱']")
注:基本的 XPath 语法类似于在一个文件系统中定位文件,如果路径以斜线(/)开始,那么该路径就表示到一个元素的绝对路径。相对路径定位以斜线(//)开头,表示选择文档中所有满足双斜线(//)后面的规则的元素(无论层级关系)。属性定位通过前缀 @ 来指定属性名称,然后指定期望的属性值来进行定位。
4.2.3 显示等待 WebDriverWait
在查找元素时,需要等待页面全部元素加载完成,如因某些原因造成页面无法加载或超时,就会造成失败。当然你可以通过 time.sleep(5) 设定强制等待秒数,直到页面加载完成后再查找元素。即使想找的元素已经出来了,它还是会继续等待,这往往会影响程序执行效率。
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
需要通过from selenium.webdriver.support.wait import WebDriverWait 导入模块
- driver:浏览器驱动
- timeout:最长超时时间,默认以秒为单位
- poll_frequency:检测的间隔步长,默认为 0.5s
- ignored_exceptions:超时后的抛出的异常信息,默认抛出 NoSuchElementExeception 异常。
与until()或者until_not()方法结合使用
WebDriverWait(driver,10).until(method,message="")
调用该方法提供的驱动程序作为参数,直到返回值为 True
WebDriverWait(driver,10).until_not(method,message="")
调用该方法提供的驱动程序作为参数,直到返回值为 False
在设置时间(10s)内,等待后面的条件发生。如果超过设置时间未发生,则抛出异常。在等待期间,每隔一定时间(默认0.5秒),调用 until 或 until_not 里的方法,直到它返回 True 或 False。
五、SOHU 邮箱自动化登录
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
url = 'https://mail.sohu.com/fe/?spm=smpc.home.top-logo.3.1701571180664h7IM3dP_1467#/login'
username = 'test@sohu.com'
password = 'test'
driver = webdriver.Chrome()
try:
driver.get(url)
mail_input = WebDriverWait(driver, 10).until(lambda d: d.find_element(By.XPATH, "//*[@placeholder='请输入您的邮箱']"))
mail_input.clear()
mail_input.send_keys(username)
mail_pwd = WebDriverWait(driver, 10).until(lambda d: d.find_element(By.XPATH, "//*[@placeholder='请输入您的密码']"))
mail_pwd.clear()
mail_pwd.send_keys(password)
# 登录按钮
loginbtn = WebDriverWait(driver, 10).until(lambda d: d.find_element(By.XPATH, "//*[@class='btn-login fontFamily']"))
loginbtn.submit() # 登录
except Exception as e:
print(e)
六、结尾
通过上述极简的例子,介绍如何让自动化测试取得成功,然而如何完善和丰富其功能,其中涉及较多技术和经验。限于篇幅这里就不展开了,建议读者可搜寻相关资料阅读,还要结合实际的项目多加思考。
七、参考
-
入门指南 | Selenium
-
XPath 教程 | 菜鸟教程 (runoob.com)
-
Python 采集网络 数据(一):BeautifulSoup
-
Python 网络数据采集(二):抓取所有网页文章来源:https://www.toymoban.com/news/detail-792281.html
-
Python 网络数据采集(三):采集整个网站文章来源地址https://www.toymoban.com/news/detail-792281.html
到了这里,关于Python 网络数据采集(四):Selenium 自动化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!