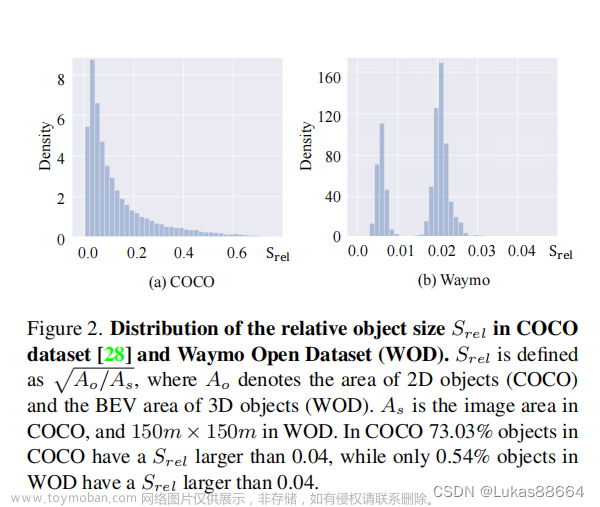
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation(2020年论文)
作者:香港中文大学
论文链接:https://arxiv.org/pdf/2011.10033.pdf
代码链接:https://github.com/xinge008/Cylinder3D
摘要
为什么做这件事(why):
● 目前用于自动驾驶场景的最好的点云分割算法常见的做法是将3D点云投射到2D空间,从而使用2D卷积进行处理,但是这种做法会损失掉一些3D信息。
● 三维体素化和三维卷积网络在室外点云中获得的改进相当有限。
● 究其原因是:sparsity and varying density,即室外开发环境的点云的稀疏性和密度不均匀性
作者做了什么(what):
● 提出了一种新的框架,用于室外激光雷达点云分割
作者怎么做的(how):
● 圆柱形分区(3D cylindrical partition)
● 非对称三维卷积网络(asymmetrical 3D convolution)
● 引入了一个point-wise细化模块:
减轻基于体素的标签编码的损失干扰
作者做的怎么样(result):
● 在SemanticKITTI 1的排行榜上名列第一
● 在nuScenes上比现有方法高出约4%
● 所提出的3D框架也很好地推广到了激光雷达全景分割和激光雷达3D检测中
引言(Introduction)
提出问题:
● 激光雷达在自动驾驶中很重要
● 深度学习在图像分割算法上效果明显
● 目前的一些做法是将点云投射到2D空间(range-image方法、bev方法),但是会损失3D信息
● 三维体素化和三维卷积网络在室外点云中获得的改进相当有限
作者的论文:
提出了一种新的框架,用于室外激光雷达点云分割(3个创新点)
● 3D圆柱分区:这个组件涉及将3D点云数据分成圆柱形区域。它根据点离原点的距离动态进行分割。这种方法的理论依据是离传感器远的点通常具有较稀疏的数据,因此对这些区域使用较大的单元格。这有助于创建更平衡的点分布。
● 非对称3D卷积网络:这个部分指的是专门设计用于处理3D点云数据的卷积神经网络(CNN)。这些网络是“非对称的”,因为它们具有水平和垂直核,这些核被调整以匹配室外环境中的点分布。这种调整有助于使网络对稀疏数据更加稳健。
● point-wise模块:为了解决由于基于体素的编码而导致的信息丢失问题,引入了一个点级模块。这个模块可能对单个点执行操作,以refine从基于体素的网络获得的特征。它有助于保留重要的细节和点之间的区别。
相关工作
室内场景点云分割
室内场景特点
● uniform density
● small number of points
● small range of the scene
常用的方法
基于原始点进行处理:
● 基于PointNet,并通过改进采样、分组和排序等技术来提高性能
● 利用聚类算法来提取点的分层特征
缺点
这些方法在应对室外点云的问题时存在限制,因为室外点云通常具有不均匀的密度和更大的场景范围,而且点的数量较多,导致从室内到室外的部署时面临计算困难
室外场景点云分割
室外场景特点
● sparsity
● varying density
常用方法
大多数现有的室外场景点云分割方法侧重于将3D点云转换为2D网格,以便使用2D卷积神经网络
● SqueezeSeg、Darknet、SqueezeSegv2和RangeNet++等方法利用球面投影机制,将点云转换为前视图图像或范围图像,并在伪图像上采用2D卷积网络进行点云分割(range image)
● PolarNet则采用鸟瞰图投影,将点云数据投影到极坐标下的鸟瞰图表示
缺点
从3D到2D的投影方法不可避免地会损失和改变3D拓扑结构,并且无法模拟几何信息
3D Voxel Partition
● 将点云转换为3D体素,可以保留3D几何信息,但对于室外LiDAR点云的改进仍然有限。
● OccuSeg、SSCN和SEG-Cloud等方法采用了这种方法。
● 问题是这些方法忽视了室外LiDAR点云的固有特性,即稀疏性和不均匀密度。
Network Architectures for Segmentation
分割使用的一些深度学习网络架构:
- Fully Convolutional Network (FCN): FCN是深度学习时代的基础工作之一。许多工作都建立在FCN的基础上,旨在通过探索扩张卷积、多尺度上下文建模和注意力建模等方法来改进性能。这些工作包括DeepLab和PSP等。
- U-Net: U-Net是一个对称的神经网络架构,用于图像分割任务。它特别适用于保留低级特征,并在2D基准上取得了巨大的成功。最近,许多研究也将U-Net的思想应用到了3D点云分割领域。
方法论
整体框架

图2上半部分是整体框架。
● LiDAR点云首先被输入到MLP(多层感知器)中,以获得点级特征,
● 然后根据圆柱划分重新分配这些特征。
● 接下来,使用非对称3D卷积网络生成逐体素的输出。
● 最后,引入了一个点级模块,用于改进这些输出。这一过程有助于在室外LiDAR点云中执行语义分割任务,提高了分割的准确性和效果。
图2下半部分详细阐述了四个组件,包括非对称下采样块(AD)、非对称上采样块(AU)、非对称残差块(A)和基于维度分解的上下文建模(DDCM)。这些组件是框架的重要部分,用于处理和改进室外LiDAR点云的语义分割任务。以下是对这些组件的简要解释:
- 非对称下采样块 (AD):这是一个用于下采样(减小分辨率)的块,通常在卷积神经网络中用于降低数据维度和提取特征。在这个框架中,非对称下采样块用于降低点云数据的复杂性,以便更有效地进行处理。
- 非对称上采样块 (AU):这是一个用于上采样(增大分辨率)的块,通常在卷积神经网络中用于还原分辨率并生成高分辨率特征图。在这个框架中,非对称上采样块用于还原点云数据的分辨率,以便更准确地进行分割。
- 非对称残差块 (A):残差块是一种神经网络块,它有助于网络学习残差信息,从而提高网络的性能。在这个框架中,非对称残差块用于改进和优化特征表示,以更好地执行语义分割任务。
- 基于维度分解的上下文建模 (DDCM):这是一种上下文建模方法,用于捕获点云数据中的上下文信息。通过维度分解,DDCM可以更好地理解点云数据中的特征和结构,从而提高分割的准确性。
这些组件共同构成了该框架的底部部分,用于处理和优化LiDAR点云数据,并执行室外语义分割任务。每个组件在提高模型性能和准确性方面都发挥着关键作用。
3D圆柱分区

上图展示了在不同距离下,圆柱形分区和立方体分区之间的非空单元格比例(结果是在SemanticKITTI的训练集上计算的)。可以看到,圆柱形分区在更大的距离下具有更高的非空比例和更均衡的点分布,特别是对于远处的区域。这表明圆柱形分区在处理不均匀密度的点云时具有明显的优势,特别是在远距离区域。这种优势有助于提高语义分割的准确性和效果。
图4中详细展示了工作流程。
● 首先,将笛卡尔坐标系中的点转换为圆柱坐标系。这一步将点(x,y,z)转换为点(ρ,θ,z),其中半径ρ(到原点的距离在x-y轴上)和方位角θ(从x轴到y轴的角度)被计算出来。
● 然后,圆柱形分区对这三个维度执行划分,需要注意的是,在圆柱坐标系中,距离较远的区域具有较大的单元格。从MLP获得的点级特征根据此划分的结果重新分配,以获得圆柱形特征。
● 完成这些步骤后,从0度开始展开圆柱体,得到3D圆柱形表示R ∈ C × H × W × L,其中C表示特征维度,H、W、L表示半径、方位角和高度。
● 接下来的非对称3D卷积网络将在这个表示上执行。这个工作流程有助于更好地处理LiDAR点云数据,并为后续的语义分割任务提供更好的数据表示。
非对称3D卷积网络
由于驾驶场景点云具有特定的物体形状分布,包括汽车、卡车、公共汽车、摩托车和其他立方体状物体,因此旨在根据这一观察来增强标准3D卷积的表示能力。此外,最近的文献 [40, 11] 也表明,在方形卷积核中,中央的十字交叉权重更重要。因此,设计了非对称残差块,以增强水平和垂直响应,并匹配对象点的分布。基于提出的非对称残差块,进一步构建了非对称下采样块和非对称上采样块,用于执行下采样和上采样操作。此外,引入了一种基于维度分解的上下文建模方法(称为DDCM),以在分解-聚合策略中探索高阶全局上下文。在图2的底部详细介绍了这些组件。
这些组件的设计和使用旨在提高网络对驾驶场景点云的表示能力,特别是对于包括汽车、卡车、公共汽车、摩托车等立方体状物体在内的对象的分布。非对称残差块、非对称下采样块、非对称上采样块和维度分解上下文建模(DDCM)是用于实现这一目标的关键组件。
Asymmetrical Residual Block(A)

非对称残差块增强了水平和垂直卷积核,以匹配驾驶场景中物体的点分布,并明确地使卷积核的骨架更强大,从而增强了对室外LiDAR点云稀疏性的鲁棒性。以汽车和摩托车为例,在图5中展示了非对称残差块的结构,其中3D卷积操作是在圆柱形网格上执行的。此外,与常规的正方形卷积核3D卷积块相比,所提出的非对称残差块还节省了计算和内存成本。通过整合非对称残差块,设计了非对称下采样块和上采样块,通过堆叠这些下采样和上采样块来构建非对称3D卷积网络。这些设计有助于提高网络的性能,并在处理室外LiDAR点云时提供了计算和内存的有效利用。
Dimension-Decomposition based Context Modeling (DDCM)
基于维度分解的上下文建模是为了捕获大范围上下文变化而设计的,因此全局上下文特征应该是高秩的,以具有足够的容量来捕获大范围的上下文信息 [49]。然而,直接构建这些高秩特征是困难的。因此,遵循张量分解理论 [8] 来构建高秩上下文,将其构建为低秩张量的组合,其中使用三个秩-1的核来获取低秩特征,然后将它们聚合在一起以获得最终的全局上下文。这种方法有助于提高网络对大范围上下文信息的建模能力。
Point-wise Refinement 模块
基于分区的方法通常会为每个单元格预测一个标签。虽然基于分区的方法可以有效地探索大范围的点云,但包括基于立方体和基于圆柱体的这一组方法不可避免地会遭受有损的单元格标签编码,例如,不同类别的点被分为同一单元格,这种情况会导致信息丢失。进行了一项统计来展示不同标签编码方法的效果,如图6所示,其中“majority encoding”表示使用单元格内点的主要类别作为单元格标签,而“minority encoding”表示使用次要类别作为单元格标签。可以观察到,它们都无法达到100%的mIoU(理想编码),并且不可避免地会有信息丢失。因此,引入了点级改进模块,以减轻有损的单元格标签编码的影响。
首先,将体素级特征基于点-体素映射表投影到点级特征。然后,点级模块将3D卷积网络之前和之后的点特征作为输入,并将它们融合在一起以改进输出。这种方法有助于提高语义分割的准确性,特别是在处理不同类别的点云时,避免了信息损失。
使用不同的标签编码方法(即,多数编码和少数编码)时,mIoU的上限。可以发现,无论采用什么编码方法,信息丢失总是会发生,这也是点级改进的原因。即使使用不同的编码方法,也无法达到理想的100% mIoU,因此点级改进模块的引入是为了减轻这种信息损失并提高语义分割的性能。
Objective Function(损失函数)
总损失函数由两个部分组成,包括体素级损失和点级损失。可以表示为 L = L_voxel + L_point。
对于体素级损失(L_voxel),遵循现有的方法 [10, 16],使用加权交叉熵损失和lovasz-softmax [4] 损失来最大化点准确度和交并比分数。
对于点级损失(L_point),只使用加权交叉熵损失来监督训练。
在推理时,point-wise refine 模块的输出用作最终输出。
对于优化器,使用Adam,初始学习率为1e-3。这些设置有助于训练和优化的模型,以获得更好的语义分割性能。
实验
实验设置
参数设置
For both two datasets, cylindrical partition splits these point clouds into 3D representation with the size = 480 × 360 × 32, where three dimensions indicate the radius, angle and height, respectively.
数据集
● SemanticKITTI
● nuScenes
评测方式
mIoU,定义如下:
whereT P i , F P i , F N i represent true positive, false positive, and false negative predictions for class i and the mIoU is the mean value of IoU i over all classes.
实验结果

消融实验


Generalization Analyses(泛化分析)
Generalize to LiDAR Panoptic Segmentation

generalize to LiDAR 3D Detection
 文章来源:https://www.toymoban.com/news/detail-792896.html
文章来源:https://www.toymoban.com/news/detail-792896.html
结论
在这篇论文中,提出了一种用于LiDAR分割的圆柱形和非对称3D卷积网络,它有助于保持3D几何关系。具体而言,设计了两个关键组件,即圆柱形分区和非对称3D卷积网络,旨在有效而稳健地处理室外LiDAR点云中的固有困难,即稀疏性和变化密度。进行了广泛的实验和消融研究,在这些研究中,该模型在SemanticKITTI中获得第一名,在nuScenes中达到了最新水平,并在其他基于LiDAR的任务中具有良好的泛化能力,包括LiDAR全景分割和LiDAR 3D检测。
这些结果表明,所提出的方法在处理LiDAR点云分割任务方面表现出色,不仅在竞赛中取得了卓越的成绩,还在实际应用中具有广泛的应用前景,对于处理室外场景的LiDAR数据的挑战有良好的应对能力。文章来源地址https://www.toymoban.com/news/detail-792896.html
到了这里,关于Cylinder3D论文阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[论文阅读]Multimodal Virtual Point 3D Detection](https://imgs.yssmx.com/Uploads/2024/02/778145-1.png)
![[论文阅读]FCAF3D——全卷积无锚 3D 物体检测](https://imgs.yssmx.com/Uploads/2024/02/777827-1.png)


![[论文阅读]PillarNeXt——基于LiDAR点云的3D目标检测网络设计](https://imgs.yssmx.com/Uploads/2024/02/715798-1.png)