大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。
本文主要介绍了Python提取PDF中部分页面的实战代码,希望能对使用Python的同学们有所帮助。
1. 问题描述
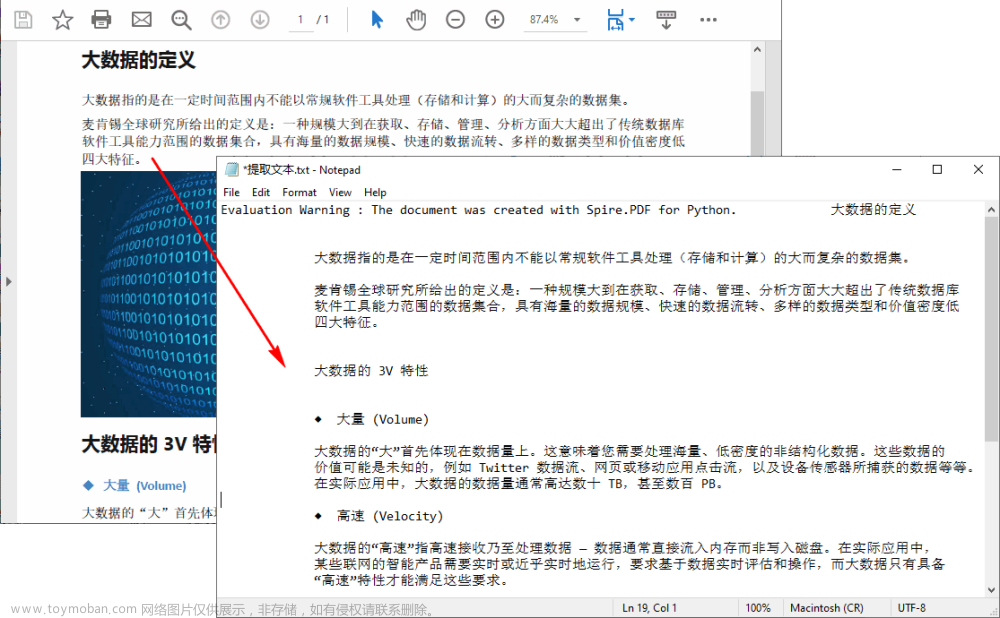
今天在阅读扫描版的PDF,但不幸的是该文件没有目录,所以看起来非常不方便。如果能够利用Python代码将每一章节拆分成单独的PDF文件,就能够有效的提升阅读效率。成功对第14章提取后的截图如下所示:
 文章来源:https://www.toymoban.com/news/detail-793052.html
文章来源:https://www.toymoban.com/news/detail-793052.html
在经过了亲身的实践后,终于找到了可复现的实战代码,最终将详细的代码总结如下。希望对同学们有所帮助。
文章来源地址https://www.toymoban.com/news/detail-793052.html
到了这里,关于Python提取PDF中部分页面的实战代码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!