背景
现在我们在面向增删改查开发时,数据库数据量大时或者对响应要求较快,我们就需要用到Redis来拿取数据。
Redis:是一种高性能的内存数据库,它将数据以键值对的形式存储在内存中,具有读写速度快、支持多种数据类型、原子性操作、丰富的特性等优势。
优势:
- 性能极高:Redis的读速度可以达到110000次/s,写速度可以达到81000次/s,这主要得益于它基于内存存储的特点,以及其单线程事件驱动架构的设计。
- 丰富的数据类型:Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储,这些数据结构可以满足多种应用场景的需求。
- 原子性操作:Redis的所有操作都是原子性的,这意味着这些操作要么成功执行,要么失败完全不执行。这为Redis在实现事务和并发控制方面提供了极大的便利。
- 丰富的特性:Redis还支持发布/订阅、通知、键过期、事务、管道、Lua脚本、集群分片和数据复制等功能。这些特性使得Redis在实现消息队列、缓存系统、分布式系统等方面具有很大的优势。
- 支持持久化:Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。这使得Redis的数据不会因为重启或者宕机而丢失。
- 支持备份和恢复:Redis支持数据的备份和恢复,即master-slave模式的数据备份。这为Redis的数据安全提供了保障。
- 丰富的客户端:Redis支持各种各样的语言的客户端接入,包括Python、Java、C#、PHP等。这使得开发者可以使用自己熟悉的编程语言来操作Redis。
综上所述,对Redis有个简单的理解。
常用方式
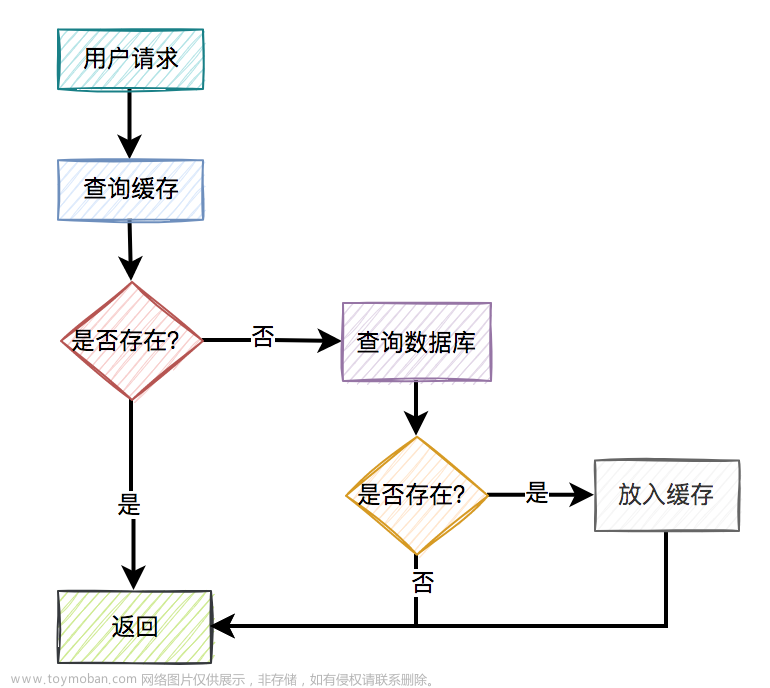
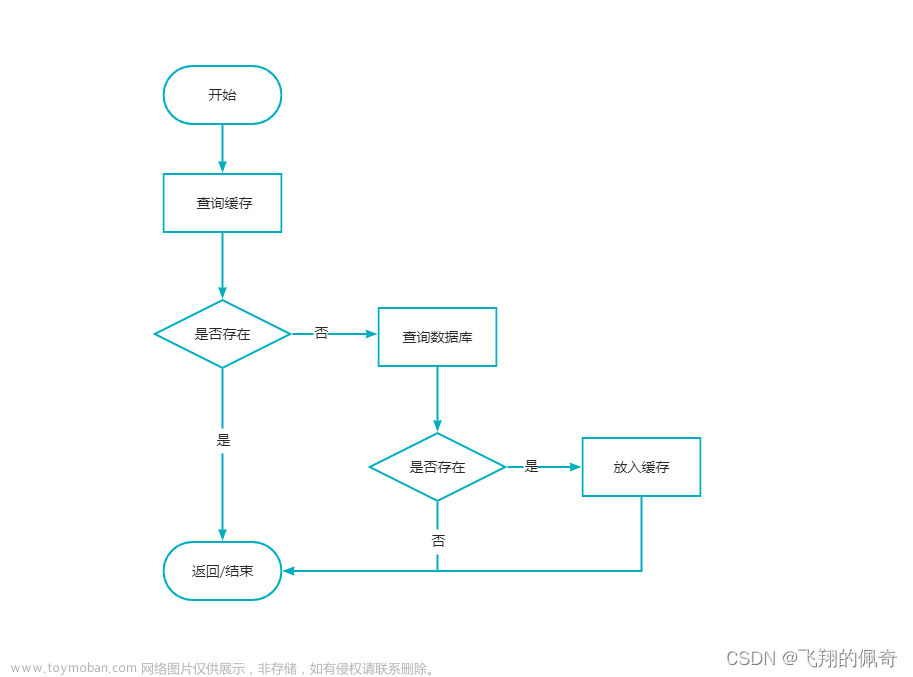
- 启动项目时将热点数据放入redis缓存中(如果没这样做,直接看第二点)
- 用户请求过来之后,先查缓存有没有数据,如果有则直接返回。
- 如果缓存没数据,再继续查数据库。
- 如果数据库有数据,则将查询出来的数据,放入缓存中,然后返回该数据。
- 如果数据库也没数据,则直接返回空。
此时,问题来了,假如说我们的热点数据是人员信息,此时新增了一条张三的信息,你再去缓存拿取的时候是不会有张三这条信息的,因为数据只是更新在了数据库并没有更新在缓存中。此时测试人员可能就会有疑问,明明新增成功了,但是数据呢?所以我们需要保证Redis缓存与数据库数据一致的问题。
解决
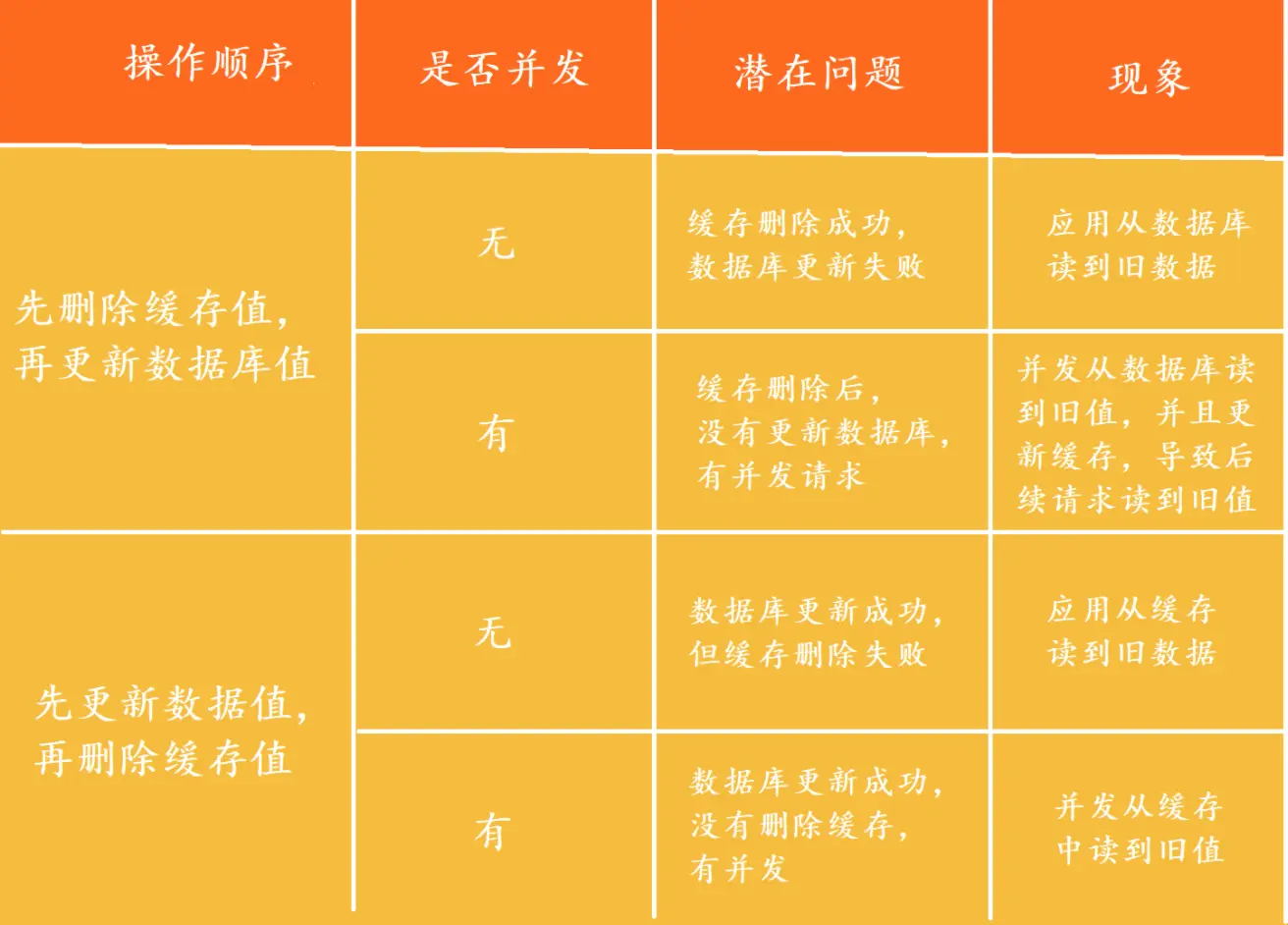
1 先删缓存,再更新数据库
先删除缓存,数据库还没有更新成功,此时如果读取缓存,缓存不存在,去数据库中读取到的是旧值,缓存不一致发生。
1.1 解决方案:延时双删
延时双删的方案的思路是,为了避免更新数据库的时候,其他线程从缓存中读取不到数据,就在更新完数据库之后,再 sleep 一段时间,然后再次删除缓存。
sleep 的时间要对业务读写缓存的时间做出评估,sleep 时间大于读写缓存的时间即可。
流程如下:
- 线程1删除缓存,然后去更新数据库
- 线程2来读缓存,发现缓存已经被删除,所以直接从数据库中读取,这时候由于线程1还没有更新完成,所以读到的是旧值,然后把旧值写入缓存
- 线程1,根据估算的时间,sleep,由于sleep的时间大于线程2读数据+写缓存的时间,所以缓存被再次删除
- 如果还有其他线程来读取缓存的话,就会再次从数据库中读取到最新值。
2 先更新数据库,再删除缓存
如果反过来操作,先更新数据库,再删除缓存呢?
这个就更明显的问题了,更新数据库成功,如果删除缓存失败或者还没有来得及删除,那么,其他线程从缓存中读取到的就是旧值,还是会发生不一致。
2.1 解决方案一:借用消息中间件帮助完成
先更新数据库,成功后往消息队列发消息,消费到消息后再删除缓存,借助消息队列的重试机制来实现,达到最终一致性的效果。
问题:
- 引入消息中间件之后,问题更复杂了,怎么保证消息不丢失,怎么样保证消息的有序性等问题随之而来。
- 就算更新数据库和删除缓存都没有发生问题,消息的延迟也会带来短暂的不一致性,不过这个延迟相对来说还是可以接受的
2.2 设置缓存过期时间
每次放入缓存的时候,设置一个过期时间,比如 5 分钟,以后的操作只修改数据库,不操作缓存,等待缓存超时后从数据库重新读取。文章来源:https://www.toymoban.com/news/detail-793285.html
问题:
如果数据更新的特别频繁,不一致性的问题就很麻烦文章来源地址https://www.toymoban.com/news/detail-793285.html
到了这里,关于Redis如何保证缓存和数据库一致性?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!