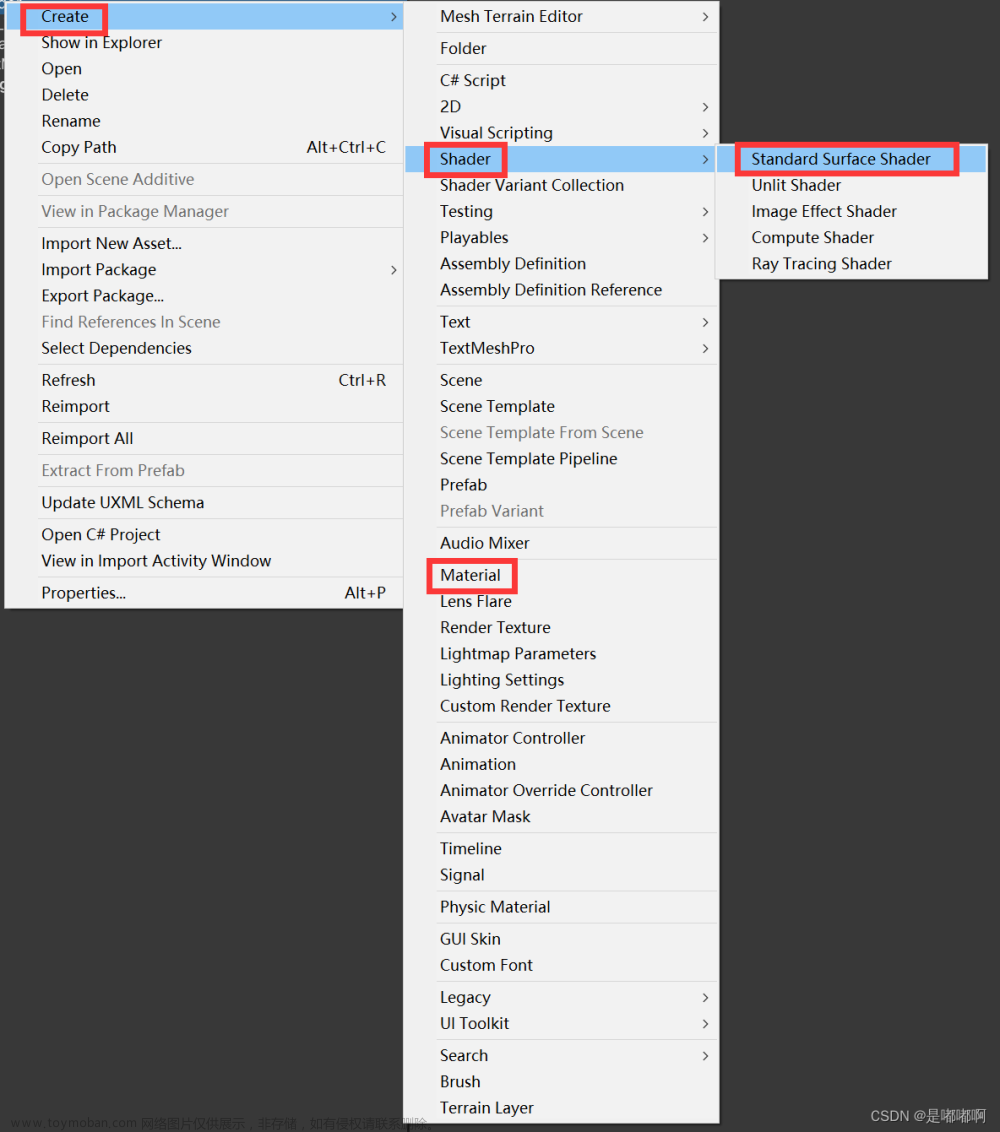
ComputeShader
一、学习链接
王江荣:Compute Shader的基础介绍与使用
Cluster_Unity实现详解三GpuDriven
用GPU代替CPU进行计算:
- 定义核函数:可以定义很多个,最终会在GPU中被执行
#pragma kernel CSMain
- 定义纹理:RWTexture2D可读写,默认的Texture2D只可读
RWTexture2D<float4> Result;
- 定义线程组,其中定义了线程的数量
[numthreads(8,8,1)]
-
uint3 id : SV_DispatchThreadID
大佬博客讲的很详细,简而言之就是可以根据内置进行多线程处理每个像素,在dispatch时,根据纹理大小和线程数量进行设置线程组数量:dispatch(1024/8, 1024/8, 1)
二、案例学习
学习项目链接
1.Compute_Texture
使用ComputeShader在GPU端修改和写入纹理,Shader中可以直接使用该纹理进行渲染。
例子中2d/3d的流体相关的函数看不太懂,基本流程是
1.创建纹理 CreateTexture
2.在shader里设置纹理
3.固定帧中Dispatch各个核函数
2.StructuredBuffer
它是一个可读写的buffer,并且我们可以指定buffer中的数据类型为我们自定义的struct类型,不用再局限于int,float这类的基本类型。
不是纹理,(你可以把它看作是像素值的数组),它可以是结构化缓冲区(一个自定义值的数组)。
- 定义结构体
//结构体
struct Particle
{
float3 prevposition;
float3 position;
};
//结构体缓冲
StructuredBuffer<Particle> particleBuffer;
- ComputeBuffer
//初始化 ComputeBuffer中的stride大小必须和RWStructuredBuffer中每个元素的大小一致。
ComputeBuffer buffer = new ComputeBuffer(int count, int stride)
//赋值
buffer.SetData(T[]);
//传递到CS中
public void SetBuffer(int kernelIndex, string name, ComputeBuffer buffer)
//和opengl一样,使用完Release
cBuffer.Release();
ComputerShader
#pragma kernel main
struct Particle
{
float3 position;
};
RWStructuredBuffer<Particle> particleBuffer; //has to be same name with rendering shader
//这里是
[numthreads(32,1,1)]
void main (uint3 id : SV_DispatchThreadID)
{
float3 pos = particleBuffer[id.x].position;
float a = 0.01f;
//绕x轴进行旋转的旋转矩阵
float3x3 m = {
1, 0, 0,
0, cos(a), -sin(a),
0, sin(a), cos(a)
};
particleBuffer[id.x].position = mul( m , pos );
}
- warpSize 是GPU里每个warp的线程数量
- Dispatch定义的线程组结构 (warpCount, 1, 1):相当于一行很长的线程组
- 由于DIspatch的限制,所以在核函数里设置 numthreads也需要注意,每个线程组处理32个像素,[numthreads(32,1,1)]里XYZ应等于32,常理说可以修改成其他,但是particleBuffer是线性的,为了简单获取,将numthreads的X设置为32,此时id.x就可以轻松地设置为particleBuffer的索引
Script:
using UnityEngine;
using System.Collections;
public class ComputeParticlesDirect_Builtin : MonoBehaviour
{
struct Particle
{
public Vector3 position;
};
public int warpCount = 1;
public Material material;
public ComputeShader computeShader;
private const int warpSize = 32;
private ComputeBuffer particleBuffer;
private int particleCount;
private Particle[] plists;
void Start ()
{
particleCount = warpCount * warpSize;
// Init particles
plists = new Particle[particleCount];
for (int i = 0; i < particleCount; ++i)
{
plists[i].position = Random.insideUnitSphere * 4f;
}
//Set data to buffer
particleBuffer = new ComputeBuffer(particleCount, 12); // 12 = sizeof(Particle)
particleBuffer.SetData(plists);
//Set buffer to computeShader and Material
computeShader.SetBuffer(0, "particleBuffer", particleBuffer);
material.SetBuffer ("particleBuffer", particleBuffer);
}
void Update ()
{
computeShader.Dispatch(0, warpCount, 1, 1);
}
void OnRenderObject()
{
material.SetPass(0);
Graphics.DrawProceduralNow(MeshTopology.Points,1,particleCount);
}
void OnDestroy()
{
particleBuffer.Release();
}
}
ComputeParticlesDirect.shader
-
渲染shader里的StructuredBuffer必须和ComputeShader里的名字一样
-
SV_InstanceID:instanceID主要作用是使用GPU实例化时,用作顶点属性的索引
-
InstanceID
Shader "ComputeParticlesDirect"
{
Properties
{
_Color1("_Color1", color) = (1,1,1,1)
_Color2("_Color2", color) = (1,1,1,1)
_pSize("Particle Size",Range(1,5)) = 2 //seems only work for Metal :(
}
SubShader
{
Pass
{
Blend SrcAlpha OneMinusSrcAlpha
CGPROGRAM
#pragma target 5.0
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct Particle
{
float3 position;
};
StructuredBuffer<Particle> particleBuffer; //has to be same name with compute shader
struct v2f
{
float4 color : COLOR;
float4 position : SV_POSITION;
float pSize : PSIZE;
};
float4 _Color1;
float4 _Color2;
float _pSize;
v2f vert (uint id : SV_VertexID, uint inst : SV_InstanceID)
{
v2f o;
float4 pos = float4(particleBuffer[inst].position, 1);
float f = inst / 320000.0f;
o.position = UnityObjectToClipPos (pos);
o.color.rgb = lerp( _Color1 , _Color2 , f );
o.color.a = 1;
o.pSize = _pSize;
return o;
}
float4 frag (v2f IN) : SV_Target
{
return IN.color;
}
ENDCG
}
}
}
3.GPU_to_CPU
Traffic: CPU instructs -> GPU writes the data -> CPU take the data for doing other stuff
CPU指令-> GPU写数据-> CPU取数据
Instead of textures (which you can see it as an array of pixels values), it can be structured buffers (an array of custom set of values).
不是纹理,可以理解为像素数组或者缓冲
- 和使用StructuredBuffer类似,正常创建和使用StructuredBuffer
- 重点是可以从Buffer获取数据,从GPU取出放入CPU
方法一:直接获取
//设置CS的Buffer
computeShader.SetBuffer(0, "particleBuffer", cBuffer);
//调度CS
computeShader.Dispatch(0, warpCount, 1, 1);
//Get data back from GPU to CPU 获取数据
cBuffer.GetData(particleArray);
方法二:回调
NativeArray
//GPU回调
private AsyncGPUReadbackRequest request;
//Request AsyncReadback (不使用回调函数)
request = AsyncGPUReadback.Request(cBuffer);
----------------------------------------------------------------------
//The callback will be run when the request is ready
private static event System.Action<AsyncGPUReadbackRequest> asyncGPUReadbackCallback;
//Request AsyncReadback (使用回调函数)
asyncGPUReadbackCallback -= AsyncGPUReadbackCallback;
asyncGPUReadbackCallback += AsyncGPUReadbackCallback;
request = AsyncGPUReadback.Request(cBuffer,asyncGPUReadbackCallback);
public void AsyncGPUReadbackCallback(AsyncGPUReadbackRequest request)
{
//TODO
request = AsyncGPUReadback.Request(cBuffer,asyncGPUReadbackCallback);
}
4.Indirect(间接使用)
Traffic: CPU instructs (tell what maximum workload is) -> GPU filters the work based on some conditions -> GPU perform only on the filtered work -> Shader takes the data for rendering
CPU->GPU过滤->GPU只执行过滤后的工作->Shader
This way the data never need to go back to CPU, and GPU doesn’t always need to do expensive maths on all of the data, so it’s fast.
数据永远不需要返回到CPU, GPU也不需要对所有数据进行昂贵的计算,所以速度很快。
代码解析:
- AppendStructuredBuffer:允许我们像处理Stack一样处理Buffer,例如动态添加和删除元素。
- args参数设置要求
- CopyCount设置计数器的作用
#pragma kernel main1
struct Particle
{
float3 position;
uint idx;
float4 color;
};
AppendStructuredBuffer<uint> particleFiltered; //Filtered index
RWStructuredBuffer<Particle> particleBuffer; //has to be same name with rendering shader
float _Time;
float3 myrotate(float3 pos, float a)
{
float3x3 m = {
1, 0, 0,
0, cos(a), -sin(a),
0, sin(a), cos(a)
};
return mul( m , pos );
}
[numthreads(1,1,1)]
void main1 (uint3 id : SV_DispatchThreadID)
{
//take the actual particle id in array
uint idx = particleBuffer[id.x].idx;
//Move the particles
float3 pos = particleBuffer[idx].position;
pos = myrotate(pos,0.01f);
particleBuffer[idx].position = pos;
//Moving filter
float f = sin(_Time)*4;
//only want the filtered ones
if (pos.x <= f)
{
particleFiltered.Append(idx);
}
}
ComputeParticlesIndirect.cs
- buffer.SetCounterValue(0); //计数器值为0
- 随着AppendStructuredBuffer.Append方法,我们计数器的值会自动的++
using UnityEngine;
using System.Collections;
public class ComputeParticlesIndirect : MonoBehaviour
{
//The stride passed when constructing the buffer must match structure size, be a multiple of 4 and less than 2048
struct Particle
{
public Vector3 position;
public uint idx;
public Color color;
};
public int particleCount = 5000;
public Material material;
public ComputeShader computeShader;
private int _kernelDirect;
private ComputeBuffer particleBuffer;
private ComputeBuffer particleFilteredResultBuffer;
private ComputeBuffer argsBuffer;
private int[] args;
private Particle[] plists;
private Bounds bounds;
void Start ()
{
//just to make sure the buffer are clean
release();
//kernels
_kernelDirect = computeShader.FindKernel("main1");
// Init particles position
plists = new Particle[particleCount];
for (int i = 0; i < particleCount; ++i)
{
plists[i].idx = (uint)i;
plists[i].position = Random.insideUnitSphere * 4f;
plists[i].color = Color.yellow;
}
//particleBuffer, for rendering
particleBuffer = new ComputeBuffer(particleCount, 4+12+16); // 4+12+16 = sizeof(Particle)
particleBuffer.SetData(plists);
//filtered result buffer, storing only the idx value of a particle
//过滤的结果缓冲区,只存储一个粒子的索引值
particleFilteredResultBuffer = new ComputeBuffer(particleCount, sizeof(uint), ComputeBufferType.Append);
//bind buffer to computeShader and Material
computeShader.SetBuffer(_kernelDirect, "particleFiltered", particleFilteredResultBuffer);
computeShader.SetBuffer(_kernelDirect, "particleBuffer", particleBuffer);
material.SetBuffer ("particleBuffer", particleBuffer);
material.SetBuffer ("particleResult", particleFilteredResultBuffer);
//Args for indirect draw
//间接引出的参数
args = new int[]
{
(int)1, //vertex count per instance
(int)particleCount, //instance count
(int)0, //start vertex location
(int)0 //start instance location
};
//IndirectArguments:
//被用作 Graphics.DrawProceduralIndirect,
//ComputeShader.DispatchIndirect
//或Graphics.DrawMeshInstancedIndirect这些方法的参数。
//buffer大小至少要12字节,DX11底层UAV为R32_UINT,SRV为无类型的R32。
//缓冲传递四个int元素
argsBuffer = new ComputeBuffer(args.Length, sizeof(int), ComputeBufferType.IndirectArguments);
argsBuffer.SetData(args);
//just a big enough bounds for drawing
bounds = new Bounds(Vector3.zero,Vector3.one*400f);
}
void Update ()
{
//Reset count
particleFilteredResultBuffer.SetCounterValue(0);
//Direct dispatch to do filter
computeShader.SetFloat("_Time",Time.time);
computeShader.Dispatch(_kernelDirect, particleCount, 1, 1);
//Copy Count - visually no change but this is necessary in terms of performance! (拷贝计数-视觉上没有变化,但这在性能方面是必要的!)
//because without this, shader will draw full amount of particles, just overlapping(因为没有这个,着色器将绘制全部数量的粒子,只是重叠)
//Check Profiler > GPU > Hierarchy search Graphics.DrawProcedural > GPU time(检查Profiler > GPU >层次搜索图形。DrawProcedural > GPU时间)
//4 is the offset byte. "particleCount" is the second int in args[], and 1 int = 4 bytes(4是偏移字节。“particleCount”是args[]中的第二个int, 1个int = 4个字节)
//获取计数器的值
//particleFilteredResultBuffer计数器的值会拷贝到argsBuffer的计数器中
//dstOffsetBytes 为argsBuffer中的偏移
ComputeBuffer.CopyCount(particleFilteredResultBuffer, argsBuffer, 4);
//Draw
//3*4 is the offset byte, where the indirect draw in args starts
//直接从ComputeBuffer中读取几何数据
Graphics.DrawProceduralIndirect(material, bounds, MeshTopology.Points,argsBuffer, 0);
}
private void release()
{
if (particleFilteredResultBuffer != null)
{
particleFilteredResultBuffer.Dispose();
particleFilteredResultBuffer.Release();
particleFilteredResultBuffer = null;
}
if (particleBuffer != null)
{
particleBuffer.Dispose();
particleBuffer.Release();
particleBuffer = null;
}
if (argsBuffer != null)
{
argsBuffer.Dispose();
argsBuffer.Release();
argsBuffer = null;
}
}
void OnDestroy()
{
release();
}
void OnApplicationQuit()
{
release();
}
}
Shader
Shader "ComputeParticlesIndirect"
{
Properties
{
_pSize("Particle Size",Range(1,5)) = 2 //seems only work for Metal :(
}
SubShader
{
Pass
{
Blend SrcAlpha OneMinusSrcAlpha
CGPROGRAM
#pragma target 5.0
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct Particle
{
float3 position;
uint idx;
float4 color;
};
StructuredBuffer<Particle> particleBuffer; //has to be same name with compute shader
StructuredBuffer<uint> particleResult; //has to be same name with compute shader
struct v2f
{
float4 color : COLOR;
float4 position : SV_POSITION;
float pSize : PSIZE;
};
float _pSize;
v2f vert (uint inst : SV_InstanceID)
{
v2f o;
uint id = particleResult[inst];
float4 pos = float4(particleBuffer[id].position, 1);
o.position = UnityObjectToClipPos (pos);
o.color.rgb = particleBuffer[id].color.rgb;
o.color.a = 1;
o.pSize = _pSize;
return o;
}
float4 frag (v2f IN) : SV_Target
{
return IN.color;
}
ENDCG
}
}
}
5. Shader_to_CPU
Traffic: CPU instructs -> Shader does rendering also writes the data -> CPU reads the data for doing other stuff
CPU向Shader写入Buffer,Shader渲染后再次写入,CPU读取数据再处理
Not only compute shaders let CPU to read it’s data, normal shader can also do that.
If you use SRP, you can use the ShaderDebugPrint feature
非ComputeShader也可以用Buffer
SRP
private ComputeBuffer fieldbuf;
mat.SetBuffer("Field", fieldbuf);
fieldbuf.GetData(fdata);
Shader:
#ifdef UNITY_COMPILER_HLSL
RWStructuredBuffer<float> Field : register(u6); //match with C# script "targetID"
#endif
v2f vert(appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
return o;
}
fixed4 frag(v2f i) : SV_Target
{
//Rainbow color
float3 c;
c.r = frac(sin(_Time.x*_Speed));
c.g = frac(sin(_Time.z*_Speed));
c.b = frac(sin(_Time.w*_Speed));
#ifdef UNITY_COMPILER_HLSL
Field[0] = c.r;
Field[1] = c.g;
Field[2] = c.b;
#endif
float4 col = tex2D(_MainTex, i.uv);
col.rgb *= c;
return col;
}
ENDCG
6.Compute_Mesh
本质上就是GPU处理顶点数据,Shader渲染时再使用修改后的顶点数据
Traffic (06_1 & 06_2): CPU instructs -> GPU writes the data -> Shader uses this data instead of original vertex buffer from MehsRenderer
CPU指令-> GPU写入数据-> Shader使用这些数据而不是MehsRenderer的原始顶点缓冲区
Traffic (other): CPU instructs -> shader is able to read the skinned vertex buffer from other meshes, do something with it and use it instead of it’s original vertex buffer from MehsRenderer
CPU指令-> shader能够从其他网格中读取蒙皮的顶点缓冲区,对它做一些事情,并使用它来代替MehsRenderer的原始顶点缓冲区
You can treat these vertex buffers as structured buffers.
可以将这些顶点缓冲区视为结构化缓冲区。
CPU:
- 和普通设置Buffer差不多
public class ComputeVertex : MonoBehaviour
{
public struct VertexData
{
public uint id;
public Vector4 pos;
public Vector3 nor;
public Vector2 uv;
public Color col;
public Vector4 opos;
public Vector3 velocity;
}
//The mesh
private Mesh mesh;
private Material mat;
//For Mesh Color
private Color col_default = Color.black;
//Compute
public ComputeShader shader;
private int _kernel;
private int dispatchCount = 0;
private ComputeBuffer vertexBuffer;
private VertexData[] meshVertData;
void Start()
{
//The Mesh (instanced)
MeshFilter filter = this.GetComponent<MeshFilter>();
mesh = filter.mesh;
mesh.name = "My Mesh";
//Unity's sphere has no vertex color,
//i.e. the array is 0 size, so we need to initiate it
List<Color> meshColList = new List<Color>();
for (int j=0; j< mesh.vertexCount; j++)
{
meshColList.Add(col_default);
}
mesh.SetColors(meshColList);
//Random vector
Vector3 s = Vector3.one;
s.x = UnityEngine.Random.Range(0.1f,1f);
s.y = UnityEngine.Random.Range(0.1f,1f);
s.z = UnityEngine.Random.Range(0.1f,1f);
//MeshVertexData array
meshVertData = new VertexData[mesh.vertexCount];
for (int j=0; j< mesh.vertexCount; j++)
{
meshVertData[j].id = (uint)j;
meshVertData[j].pos = mesh.vertices[j];
meshVertData[j].nor = mesh.normals[j];
meshVertData[j].uv = mesh.uv[j];
meshVertData[j].col = mesh.colors[j];
meshVertData[j].opos = meshVertData[j].pos;
meshVertData[j].velocity = s;
}
//Compute Buffer
vertexBuffer = new ComputeBuffer(mesh.vertexCount, 21*4); // sizeof(VertexData) in bytes
vertexBuffer.SetData(meshVertData);
//Compute Shader
_kernel = shader.FindKernel ("CSMain");
uint threadX = 0;
uint threadY = 0;
uint threadZ = 0;
shader.GetKernelThreadGroupSizes(_kernel, out threadX, out threadY, out threadZ);
dispatchCount = Mathf.CeilToInt(meshVertData.Length / threadX);
shader.SetBuffer(_kernel, "vertexBuffer", vertexBuffer);
shader.SetInt("_VertexCount",meshVertData.Length);
//The Material
MeshRenderer ren = this.GetComponent<MeshRenderer>();
mat = ren.material;
mat.name = "My Mat";
mat.SetBuffer("vertexBuffer", vertexBuffer);
}
void Update()
{
//Run compute shader
shader.SetFloat("_Time",Time.time);
shader.Dispatch (_kernel, dispatchCount , 1, 1);
}
void OnDestroy()
{
vertexBuffer.Release();
}
}
GPU:设置buffer文章来源:https://www.toymoban.com/news/detail-793356.html
#pragma kernel CSMain
struct VertexData
{
uint id;
float4 pos;
float3 nor;
float2 uv;
float4 col;
float4 opos;
float3 velocity;
};
RWStructuredBuffer<VertexData> vertexBuffer;
float _Time;
uint _VertexCount;
[numthreads(1,1,1)]
void CSMain (uint3 id : SV_DispatchThreadID)
{
//Real id
uint rid = vertexBuffer[id.x].id;
//Prev / next id
uint rid_prev = rid - 1; if(rid_prev < 0) rid_prev = _VertexCount-1;
uint rid_next = rid + 1; if(rid_prev >= _VertexCount) rid_next = 0;
//Positions for knowing which is the first vertex
float4 pos0 = vertexBuffer[0].pos;
float4 pos = vertexBuffer[rid].pos;
float dist = distance(pos,pos0);
//color animation
if(rid == 0 || dist < 0.01f)
{
//Rainbow color for the first vertex
float3 c;
c.r = frac(sin(_Time + vertexBuffer[rid].velocity.x));
c.g = frac(sin(_Time + vertexBuffer[rid].velocity.y));
c.b = frac(sin(_Time + vertexBuffer[rid].velocity.z));
vertexBuffer[rid].col = float4(c,1);
}
else
{
vertexBuffer[rid].col = vertexBuffer[rid_prev].col;
}
//Vertex animation
vertexBuffer[rid].pos.xz = vertexBuffer[rid].opos.xz * (1 + sin(_Time + vertexBuffer[rid].opos.y * 3.0f) * 0.3f);
}
Shader:获得buffer里的数据,使用顶点着色器文章来源地址https://www.toymoban.com/news/detail-793356.html
Shader "ComputeVertex"
{
Properties
{
_MainTex ("_MainTex (RGBA)", 2D) = "white" {}
_Color ("_Color", Color) = (1,1,1,1)
}
SubShader
{
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
// Same with the one with compute shader & C# script
struct vertexData
{
uint id;
float4 pos;
float3 nor;
float2 uv;
float4 col;
float4 opos;
float3 velocity;
};
StructuredBuffer<vertexData> vertexBuffer;
struct v2f
{
float4 vertex : SV_POSITION;
float2 uv : TEXCOORD0;
fixed4 color : COLOR;
};
sampler2D _MainTex;
float4 _MainTex_ST;
float4 _Color;
v2f vert (uint id : SV_VertexID)
{
v2f o;
uint realid = vertexBuffer[id].id;
o.vertex = UnityObjectToClipPos(vertexBuffer[realid].pos);
o.uv = TRANSFORM_TEX(vertexBuffer[realid].uv, _MainTex);
o.color = vertexBuffer[realid].col;
return o;
}
fixed4 frag (v2f i) : SV_Target
{
fixed4 col = tex2D(_MainTex, i.uv);
col.rgb *= i.color.rgb;
return col*_Color;
}
ENDCG
}
}
}
到了这里,关于【unity】ComputeShader的学习使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!