前言
Flink CDC 于 2021 年 11 月 15 日发布了最新版本 2.1,该版本通过引入内置 Debezium 组件,增加了对 Oracle 的支持。对该版本进行试用并成功实现了对 Oracle 的实时数据捕获以及性能调优,现将试用过程中的一些关键细节进行分享。
使用环境
Oracle:11.2.0.4.0(RAC 部署)
Flink:1.13.1
Hadoop:3.2.1
问题
1、无法连接数据库
根据官方文档说明,在 Flink SQL CLI 中输入以下语句:
create table TEST (A string)
WITH ('connector'='oracle-cdc',
'hostname'='10.230.179.125',
'port'='1521',
'username'='myname',
'password'='***',
'database-name'='MY_SERVICE_NAME',
'schema-name'='MY_SCHEMA',
'table-name'='TEST' );
之后尝试通过 select * from TEST 观察,发现无法正常连接 Oracle,报错如下:
[ERROR] Could not execute SQL statement. Reason:
oracle.net.ns.NetException: Listener refused the connection with the following error:
ORA-12505, TNS:listener does not currently know of SID given in connect descriptor
从报错信息来看,可能是由于 Flink CDC 误将连接信息中提供的 MY_SERVICE_NAME (Oracle 的服务名) 错认为 SID。于是尝试阅读 Flink CDC 涉及到 Oracle Connector 的源码,发现在 com.ververica.cdc.connectors.oracle.OracleValidator 中,对于 Oracle 连接的代码如下:
public static Connection openConnection(Properties properties) throws SQLException {
DriverManager.registerDriver(new oracle.jdbc.OracleDriver());
String hostname = properties.getProperty("database.hostname");
String port = properties.getProperty("database.port");
String dbname = properties.getProperty("database.dbname");
String userName = properties.getProperty("database.user");
String userpwd = properties.getProperty("database.password");
return DriverManager.getConnection(
"jdbc:oracle:thin:@" + hostname + ":" + port + ":" + dbname, userName, userpwd);
}
由上可以看出,在当前版本的 Flink CDC 中,对于 SID 和 Service Name 的连接方式并未做区分,而是直接在代码中写死了 SID 的连接方式 (即 port 和 dbname 中间使用 “ : ” 分隔开)。
从 Oracle 8i 开始,Oracle 已经引入了 Service Name 的概念以支持数据库的集群 (RAC) 部署,一个 Service Name 可作为一个数据库的逻辑概念,统一对该数据库不同的 SID 实例的连接。据此,可以考虑以下两种方式:
- 在 Flink CDC 的 create table 语句中,将 database-name 由 Service Name 替换成其中一个 SID。该方式能解决连接问题,但无法适应主流的 Oracle 集群部署的真实场景;
- 对该源码进行修改。具体可在新建工程中,重写 com.ververica.cdc.connectors.oracle.OracleValidator 方法,修改为 Service Name 的连接方式 (即 port 和 dbname 中间使用 “ / ” 分隔开),即:
“jdbc:oracle:thin:@” + hostname + “:” + port + “/” + dbname, userName, userpwd);
2、无法连接数据库无法找到 Oracle 表
按照上述步骤,再次通过 select * from TEST 观察,发现依然无法正常获取数据,报错如下:
[ERROR] Could not execute SQL statement. Reason:
io.debezium.DebeziumException: Supplemental logging not configured for table MY_SERVICE_NAME.MY_SCHEMA.test. Use command: ALTER TABLE MY_SCHEMA.test ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS
观察到错误日志中提到的表是 MY_SERVICE_NAME.MY_SCHEMA.test,为什么数据库名、Schema 名都是大写,而表名是小写?
注意到该错误由 io.debezium 包报出,通过分析该包的源代码 (通过 Flink CDC 的 pom.xml 文件可知,目前使用的是 debezium 1.5.4 版本) 可知,在 io.debezium.relational.Tables 中有如下代码:
private TableId toLowerCaseIfNeeded(TableId tableId) {
return tableIdCaseInsensitive ? tableId.toLowercase() : tableId;
}
可见,Debezium 的开发者将 “大小写不敏感” 统一定义为了 “需要将表名转换为小写”。对于 Debezium 支持的 PostgreSQL、Mysql 等确实如此。然而对于 Oracle 数据库,“大小写不敏感” 却意味着在内部元信息存储时,需要将表名转换为大写。
因而 Debezium 在读取到 “大小写不敏感” 的配置后,按照上述代码逻辑,只会因为尝试去读取小写的表名而报错。
由于 Debezium 直到目前最新的稳定版本 1.7.1,以及最新的开发版本 1.8.0 都未修复该问题,我们可以通过以下两种方法绕过该问题:
- 如需使用 Oracle “大小写不敏感” 的特性,可直接修改源码,将上述 toLowercase 修改为 toUppercase (这也是笔者选择的方法);
- 如果不愿意修改源码,且无需使用 Oracle “大小写不敏感” 的特性,可以在 create 语句中加上 ‘debezium.database.tablename.case.insensitive’=‘false’,如下示例:
create table TEST (A string) WITH ('connector'='oracle-cdc', 'hostname'='10.230.179.125', 'port'='1521', 'username'='myname', 'password'='***', 'database-name'='MY_SERVICE_NAME', 'schema-name'='MY_SCHEMA', 'table-name'='TEST', 'debezium.database.tablename.case.insensitive'='false' );
该方法的弊端是丧失了 Oracle “大小写不敏感” 的特性,在 ‘table-name’ 中必须显式指定大写的表名。
需要注明的是,对于 database.tablename.case.insensitive 参数,Debezium 目前仅对 Oracle 11g 默认设置为 true,对其余 Oracle 版本均默认设置为 false。所以读者如果使用的不是 Oracle 11g 版本,可无需修改该参数,但仍需显式指定大写的表名。
3、数据延迟较大
数据延迟较大,有时需要 3-5 分钟才能捕捉到数据变化。对于该问题,在 Flink CDC FAQ 中已给出了明确的解决方案:在 create 语句中加上如下两个配置项:
'debezium.log.mining.strategy'='online_catalog',
'debezium.log.mining.continuous.mine'='true'
那么为什么要这样做呢?我们依然可以通过分析源码和日志,结合 Oracle Logminer 的工作原理来加深对工具的理解。
对 Logminer 的抽取工作,主要在 Debezium 的 io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource 中 execute 方法进行。为节约篇幅,本文不列出实际的源码,仅提炼出关键过程绘于下面的流程图,有兴趣的读者可以对照该流程图,结合实际源码进行分析:

采用 redo_log_catalog 的方式,可以监控数据表的 DDL 信息,且由于 archive logs 被永久保存到磁盘上,可以在数据库宕机后依然正常获取到宕机前的所有 DDL 和 DML 操作。但由于涉及到比 online catalog 更多的信息监控,以及由此带来的频繁的日志切换和日志转储操作,其代价也是惊人的。
一般来说,Flink CDC 所需要监控的表,特别是对于业务系统有重大意义的表,一般不会进行 DDL 操作,仅需要捕捉 DML 操作即可,且对于数据库宕机等极特殊情况,也可使用在数据库恢复后进行全量数据更新的方式保障数据的一致性。因而,online_catalog 的方式足以满足我们的需要。
另外,无论使用 online_catalog,还是默认的 redo_log_catalog,都会存在第 ② 步找到的日志和第 ⑤ 步实际需要的日志不同步的问题,因此,加入 ‘debezium.log.mining.continuous.mine’=‘true’ 参数,将实时搜集日志的工作交给 Oracle 自动完成,即可规避这一问题。
按照这两个参数配置后,数据延迟一般可以从数分钟降至 5 秒钟左右。
4、调节参数继续降低数据延迟
上述流程图的第 ③ 步和第 ⑦ 步,提到了根据配置项来确定 LogMiner 监控时序范围,以及确定休眠时间。下面对该过程进行进一步分析,并对单个表的进一步调优给出一般性的方法论。
通过观察 io.debezium.connector.oracle.logminer.LogMinerHelper 类中的 getEndScn 方法,可了解到 debezium 对监控时序范围和休眠时间的调节原理。为便于读者理解,将该方法用流程图说明如下: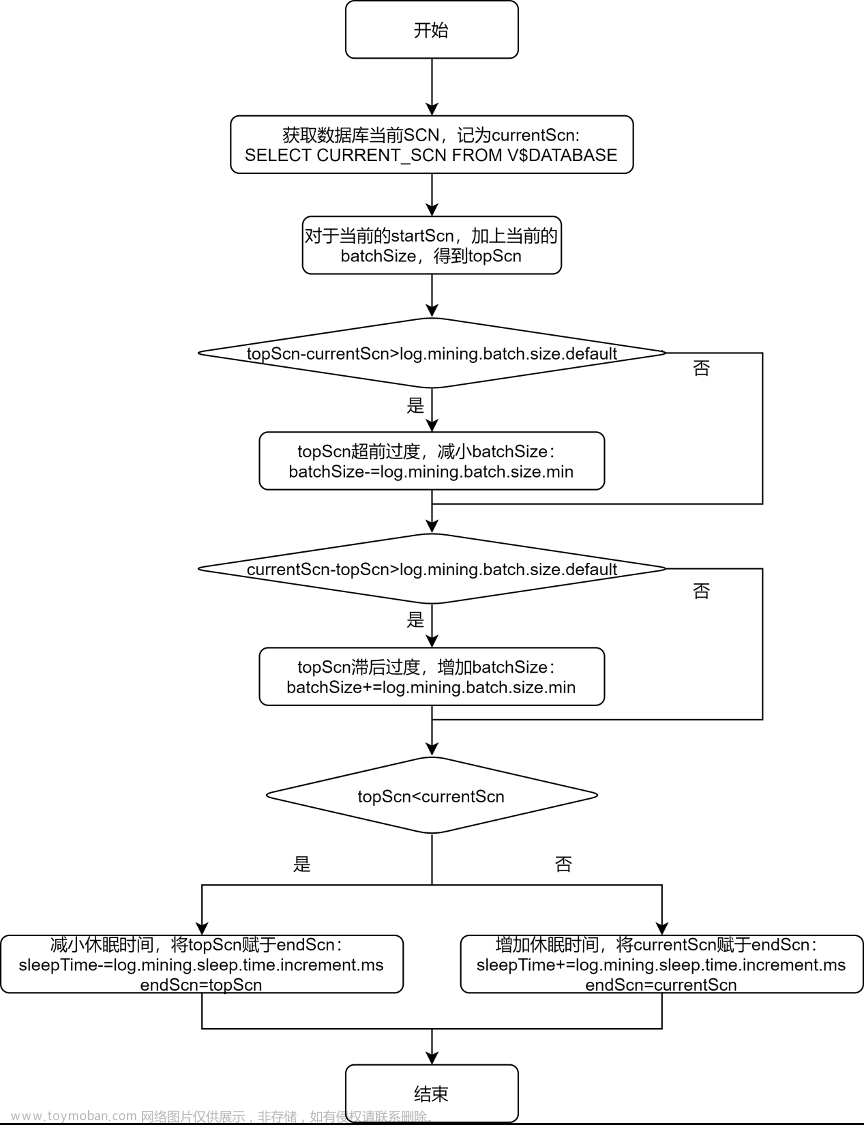
从上述的流程图中可以看出,debezium 给出 log.mining.batch.size.* 和 log.mining.sleep.time.* 两组参数,就是为了让每一次 logMiner 运行的步长能够尽可能和数据库自身 SCN 增加的步长一致。由此可见:
- log.mining.batch.size.* 和 log.mining.sleep.time.* 参数的设定,和数据库整体的表现有关,和单个表的数据变化情况无关;
- log.mining.batch.size.default 不仅仅是监控时序范围的起始值,还是监控时序范围变化的阈值。所以如果要实现更灵活的监控时序范围调整,可考虑适当减小该参数;
- 由于每一次确定监控时序范围时,都会根据 topScn 和 currentScn 的大小来调整 sleepTime,所以为了实现休眠时间更灵活的调整,可考虑适当增大 log.mining.sleep.time.increment.ms;
- log.mining.batch.size.max 不能过小,否则会有监控时序范围永远无法追上数据库当前 SCN 的风险。为此,debezium 在 io.debezium.connector.oracle.OracleStreamingChangeEventSourceMetrics 中存在以下逻辑:
if (currentBatchSize == batchSizeMax) {
LOGGER.info("LogMiner is now using the maximum batch size {}. This could be indicative of large SCN gaps", currentBatchSize);
}
如果当前的监控时序范围达到了 log.mining.batch.size.max,那么 debezium 会在日志中给出如上提示。在实际应用中,观察 Flink CDC 产生的 log 是否包含该提示,便可得知 log.mining.batch.size.max 的值是否合理。
5、Debezium Oracle Connector的隐藏参数
事实上从上文中我们已经了解到了两个隐藏参数:
debezium.database.tablename.case.insensitive (见第二节内容)
debezium.log.mining.continuous.mine (见第三节内容)
这两个参数在 Debezium 的官方文档中均未给出实际说明,但实际上可以使用。通过分析源码,现给出 Debezium Oracle Connector 的所有隐藏参数,以及其说明如下:

除了上面我们已经用到的两个参数以外,同样值得重点关注的是 log.mining.history.recorder.class 参数。
由于该参数目前默认为 io.debezium.connector.oracle.logminer.NeverHistoryRecorder,是一个空类;
所以我们在分析 Flink CDC 行为时,通过自定义实现 io.debezium.connector.oracle.logminer.HistoryRecorder 接口的类,可在不修改源码的情况下,实现对 Flink CDC 行为的个性化监控。文章来源:https://www.toymoban.com/news/detail-793466.html
更多文章请扫码关注公众号,有问题的小伙伴也可以在公众号上提出。 文章来源地址https://www.toymoban.com/news/detail-793466.html
文章来源地址https://www.toymoban.com/news/detail-793466.html
到了这里,关于Flink CDC 实时抽取 Oracle 数据-排错&调优的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!