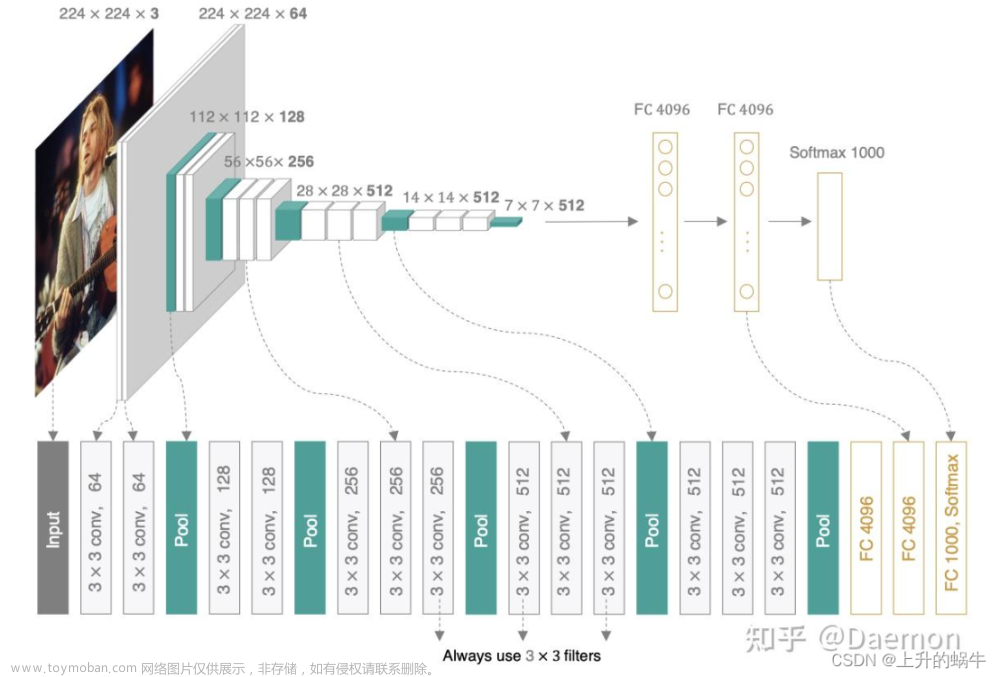
1、网络结构
VGG16模型很好的适用于分类和定位任务,其名称来自牛津大学几何组(Visual Geometry Group)的缩写。
根据卷积核的大小核卷积层数,VGG共有6种配置,分别为A、A-LRN、B、C、D、E,其中D和E两种是最为常用的VGG16和VGG19。
介绍结构图:
- conv3-64 :是指第三层卷积后维度变成64,同样地,conv3-128指的是第三层卷积后维度变成128;
- input(224x224 RGB image) :指的是输入图片大小为224244的彩色图像,通道为3,即224224*3;
- maxpool :是指最大池化,在vgg16中,pooling采用的是2*2的最大池化方法(如果不懂最大池化,下面有解释);
- FC-4096 :指的是全连接层中有4096个节点,同样地,FC-1000为该层全连接层有1000个节点;
- padding:指的是对矩阵在外边填充n圈,padding=1即填充1圈,5X5大小的矩阵,填充一圈后变成7X7大小;
- 最后补充,vgg16每层卷积的滑动步长stride=1,padding=1,卷积核大小为333;

如上图VGG16的网络结构为,VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。具体信息如下:
- 卷积-卷积-池化-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-卷积-卷积-卷积-池化-全连接-全连接-全连接
- 通道数分别为64,128,512,512,512,4096,4096,1000。卷积层通道数翻倍,直到512时不再增加。通道数的增加,使更多的信息被提取出来。全连接的4096是经验值,当然也可以是别的数,但是不要小于最后的类别。1000表示要分类的类别数。
- 用池化层作为分界,VGG16共有6个块结构,每个块结构中的通道数相同。因为卷积层和全连接层都有权重系数,也被称为权重层,其中卷积层13层,全连接3层,池化层不涉及权重。所以共有13+3=16层。
- 对于VGG16卷积神经网络而言,其13层卷积层和5层池化层负责进行特征的提取,最后的3层全连接层负责完成分类任务。
2、VGG16的卷积核
- VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
- 卷积层全部都是3*3的卷积核,用上图中conv3-xxx表示,xxx表示通道数。其步长为1,用padding=same填充。
- 池化层的池化核为2*2
3、卷积计算

具体的过程:
- 输入图像尺寸为224x224x3,经64个通道为3的3x3的卷积核,步长为1,padding=same填充,卷积两次,再经ReLU激活,输出的尺寸大小为224x224x64
- 经max pooling(最大化池化),滤波器为2x2,步长为2,图像尺寸减半,池化后的尺寸变为112x112x64
- 经128个3x3的卷积核,两次卷积,ReLU激活,尺寸变为112x112x128
- max pooling池化,尺寸变为56x56x128
- 经256个3x3的卷积核,三次卷积,ReLU激活,尺寸变为56x56x256
- max pooling池化,尺寸变为28x28x256
- 经512个3x3的卷积核,三次卷积,ReLU激活,尺寸变为28x28x512
- max pooling池化,尺寸变为14x14x512
- 经512个3x3的卷积核,三次卷积,ReLU,尺寸变为14x14x512
- max pooling池化,尺寸变为7x7x512
- 然后Flatten(),将数据拉平成向量,变成一维51277=25088。
- 再经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活
- 最后通过softmax输出1000个预测结果
从上面的过程可以看出VGG网络结构还是挺简洁的,都是由小卷积核、小池化核、ReLU组合而成。其简化图如下(以VGG16为例):

4、权重参数(不考虑偏置)
1)输入层有0个参数,所需存储容量为224x224x3=150k
2)对于第一层卷积,由于输入图的通道数是3,网络必须要有通道数为3的的卷积核,这样的卷积核有64个,因此总共有(3x3x3)x64 = 1728个参数。
所需存储容量为224x224x64=3.2M
计算量为:输入图像224×224×3,输出224×224×64,卷积核大小3×3。
所以Times=224×224×3x3×3×64=8.7×107
3)池化层有0个参数,所需存储容量为 图像尺寸x图像尺寸x通道数=xxx k
4)全连接层的权重参数数目的计算方法为:前一层节点数×本层的节点数。因此,全连接层的参数分别为:
7x7x512x4096 = 1027,645,444
4096x4096 = 16,781,321
4096x1000 = 4096000
按上述步骤计算的VGG16整个网络总共所占的存储容量为24M*4bytes=96MB/image 。
所有参数为138M
VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力;
但同时缺点也很明显:
即训练时间过长,调参难度大。
需要的存储容量大,不利于部署。
5、VGG模型所需要的内存容量
借鉴一下大佬的图:
 文章来源:https://www.toymoban.com/news/detail-793685.html
文章来源:https://www.toymoban.com/news/detail-793685.html
6、总结文章来源地址https://www.toymoban.com/news/detail-793685.html
- 通过增加深度能有效地提升性能;
- VGG16是最佳的模型,从头到尾只有3x3卷积与2x2池化,简洁优美;
- 卷积可代替全连接,可适应各种尺寸的图片。
到了这里,关于深度学习——VGG16模型详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!