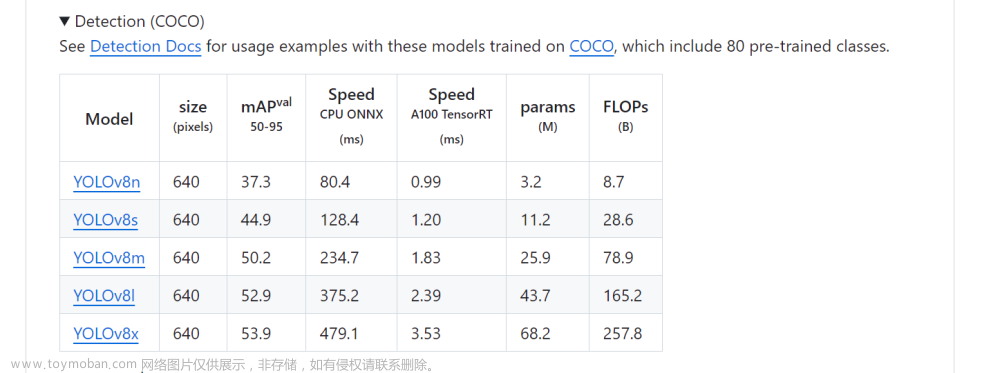
源码地址:
github地址:https://github.com/Ahmednull/L2CS-Net
L2CS-Net介绍:
眼睛注视(eye gaze) 是在各种应用中使用的基本线索之一。
它表示用户在人机交互和开放对话系统中的参与程度。此外,它还被用于增强现实,用于预测用户的注意力,从而提高设备的感知能力,降低功耗。
因此,研究人员开发了多种方法和技术来准确估计人类的凝视。这些方法分为两类: 基于模型的方法和基于外观的方法。
基于模型的方法通常需要专用硬件,这使得它们难以在不受约束的环境(unconstrained environment)中使用。
基于外观的方法将人类的视线直接从廉价的现成相机拍摄的图像中还原出来,使它们很容易在不受约束的设置下在不同的位置生成。
目前,基于CNN的方法是基于外观的方法是最常用的凝视估计方法,因为它提供了更好的凝视性能。
大部分的相关工作专注于开发新颖的基于CNN的网络,主要由流行的骨干(如VGG, ResNet-18 , ResNet-50等) 组成,来提取凝视特征,最终输出凝视方向。
这些网络的输入可以是单个流 (例如:如面部或眼睛图像)或多个流(如面部和眼睛图像)。
用于注视估计任务的最常见的损失函数是均方损失或L2损失。
尽管基于CNN的方法提高了注视精度,但它们缺乏鲁棒性和泛化性,特别是在无约束环境下。
本文介绍了一种新的估计方法来在RGB图像中估计3D凝视角度,使用一种 multi-loss 的方法。
我们建议使用两个全连接层独立回归每个凝视角度(偏航,俯仰),以提高每个角度的预测精度。
此外,我们对每个凝视角度使用两个单独的损失函数。每一种损失都由注视二值分类和回归组成。
最后,这两种损失通过网络反向传播,精确微调网络权重,提高网络泛化。
我们通过使用softmax层和交叉熵损失(cross-entropy loss)来执行gaze bin分类,以便网络以鲁棒的方式估计注视角的邻域。
基于所提出的损失函数和softmax层 (L2 loss+ cross-entropy loss+ softmax层),我们提出了一种新的网络(L2CS-Net)来预测无约束设置下的3D凝视向量。
最后,我们在两个流行的数据集MPIIGaze和Gaze360上评估了我们的网络的鲁棒性。L2CS-Net在MPIIGaze和Gaze360数据集上实现了SOAT的性能。
测试环境:
VS2019
.net framework 4.7.2
OpenCvSharp 4.8.0
Microsoft.ML.OnnxRuntime 1.16.3
效果:
![[C#]OpenCvSharp结合yolov8-face实现L2CS-Net眼睛注视方向估计或者人脸朝向估计,C#,YOLO](https://imgs.yssmx.com/Uploads/2024/01/793692-1.jpeg)
实现部分代码:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Diagnostics;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using OpenCvSharp;
namespace FIRC
{
public partial class Form1 : Form
{
Mat src = new Mat();
FaceDetector fd = new FaceDetector();
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
OpenFileDialog openFileDialog = new OpenFileDialog();
openFileDialog.Filter = "图文件(*.*)|*.jpg;*.png;*.jpeg;*.bmp";
openFileDialog.RestoreDirectory = true;
openFileDialog.Multiselect = false;
if (openFileDialog.ShowDialog() == DialogResult.OK)
{
src = Cv2.ImRead(openFileDialog.FileName);
pictureBox1.Image = OpenCvSharp.Extensions.BitmapConverter.ToBitmap(src);
}
}
private void button2_Click(object sender, EventArgs e)
{
if(pictureBox1.Image==null)
{
return;
}
var results = fd.Inference(src);
var resultMat = fd.DrawImage(src,results);
pictureBox2.Image= OpenCvSharp.Extensions.BitmapConverter.ToBitmap(resultMat); //Mat转Bitmap
}
private void Form1_Load(object sender, EventArgs e)
{
fd.LoadWeights(Application.StartupPath+"\\weights\\yolov8n-face.onnx", Application.StartupPath + "\\weights\\l2cs_net_1x3x448x448.onnx");
}
private void btn_video_Click(object sender, EventArgs e)
{
}
}
}
视频演示:
bilibili.com/video/BV19t4y1f7rN/
源码地址:
参考文献:文章来源:https://www.toymoban.com/news/detail-793692.html
1.https://blog.csdn.net/gaoqing_dream163/article/details/132149150文章来源地址https://www.toymoban.com/news/detail-793692.html
到了这里,关于[C#]OpenCvSharp结合yolov8-face实现L2CS-Net眼睛注视方向估计或者人脸朝向估计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!