开篇:
图片是本人随笔画的,有点粗糙,望大家谅解,如有不妥之处,请联系我们,感谢
一、索引到底是什么
.索引是帮助mysql高效获取数据的排好序的数据结构
.索引是存储在文件里的
.数据结构: 二叉树 HASH BTREE
如果没有索引的话,循环一条一条的找,找一次就是一次IO,这样速度就会很慢
我们知道数据库数据都是存在磁盘上的,当我们查找数据时,就会从磁盘上取数据,每取一次就是一次IO,IO是非常耗时的,为了速度快会把数据放到缓存里,然后在缓存里进行操作
二、磁盘存取原理
当查找数据的时候,就是磁头循环找此道,就会一直循环查找,一次查找就是一次IO,IO是很耗时的
三、Mysql数据结构详解
就拿上面的7条数据来说,如果没有索引,当我们查找第7条数据时,就会循环7次,如果有百万级别的数据,那么就会查找百万次,显然这样是不行的,就需要数据结构算法来优化,那我们就从二叉树----HASH---BTREE来一一说起
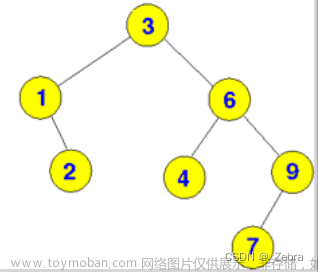
二叉树:
二叉树节点保存的都是单个索引,高度会随着数据增大而增高,但是比一条一条的循环会快
不用二叉树是因为的极端情况下会出现单边增长,这样在数量大的情况下,和一条一条查找没有区别。
红黑树:
红黑树有自平衡性质,不会出现单边增长,它会动态自旋转,在性能上比二叉树又高一点,但是mysql也没有用这种数据结构,因为数据量超大的情况下,数据高度也会一直增大,在最终这个树高度也非常大,解决不了根本问题
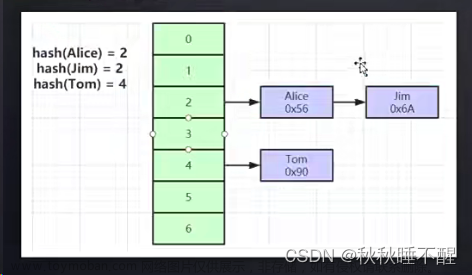
HASH:
hash算法一次就会定位到文件指针,速度快,但是还是没有用,如果范围查找的话就没有办法了,如果只是内存中的话,他的时间复杂度是O(1),速度会会很快,但是索引文件也是保存在磁盘上,而且hash是不连续的放在磁盘上的,这样查询起来也很慢,这才是不用hash的最根本原因
B-TREE:
相比上面的数据结构,b-tree增加了横向大小(度Degree),那么在高度上就减小了,查找次数就少了
15,56,77.。。。。是索引,data就是对应的一行数据
那么在横向的度上最大多少合适呢??总不能横向上一直扩展下呀,磁盘一次IO,就是取一个横向的节点(度),把一个节点的数据放在缓存中,那么一次IO也不能把所用的数据全取出来,所以最好是一次io,就把这个节点全取处理,电脑操作系统从磁盘一次取数据到内存中一般是4K,而mysql取一次数据一般是16K,所以横向节点一般设置为16K。因为一个节点设置成16K的话,这个节点保存了索引和索引对应行的数据,那么这个节点横向保存不了太多的数据,所以,这种数据结构也不合适,引入新的数据结构
B+Tree
查找一次数据就是和磁盘一次IO,一次IO会把这个数据相邻的数据一下全部查处理,这样速度会更快,这样的一页就是咱们说的一个节点(4K),分配空间的时候也是一页一页分配的,这样会更快,一页就是一个节点
mysql 常用的引擎有MyISAM和InNoDb,两种引擎得索引结构是不一样的
MyISAM的数据结构:
.frm表结构文件 .myd表数据文件 .myi表索引文件
myisam引擎的主键索引数据结构是左上图,普通索引是右上图,叶子节点存的不是数据本身,是数据文件指针,和b_tree数据不一样,注意:每类的索引,都是各自的树,不是混合在一起的
.frm表结构文件 .ibd 表数据和索引文件
主键索引是聚集索引,因为叶子节点是所有的数据,就是一行数据,非主键索引叶子节点只包括索引和主键,再用主键找对应数据
非主键索引叶子节点只包括索引和主键,再用主键找对应数据,这样是为了节省空间和数据一致性
联合索引:
要满足最左原则
联合索引(col1, col2, col3)也是一棵B+树,其非叶子节点存储的是第一个关键字的索引,而叶子节点存储的则是三个关键字col1、col2、col3三个关键字的数据,且按照col1-col2-col3的顺序进行排序。
例如:
如果执行的是,SELECT * FROM T WHERE B=‘Tom’ AND C=4567;
那么无法使用索引,因为索引是用A字段先排序的,如果没有先确定A,直接查找B和C,那么将会是全表查询。
如果执行的是,SELECT * FROM T WHERE A=‘30’ ;
那么,会先找到A字段,再在A等于30的数据中(比如有很多条),找B等于Demi的数据。这样是可以用到索引的。
如果执行的是,SELECT * FROM T WHERE A=‘18’ AND C=1234;
那么,A字段可以索引,而C不能索引。所以可以部分索引,也比全表查询快。
如果执行 SELECT * FROM T WHERE B=Demi AND C=1234 and A=‘18’
是用到索引的,在and的情况下如果把第一个放到最后位置也是能用到索引的
现在我想大家应该了解了什么为什么是最左原则。因为,B+树是按照最左边的字段以此构建的。
作者:京东零售 韩航云文章来源:https://www.toymoban.com/news/detail-793738.html
来源:京东云开发者社区 转载请注明来源文章来源地址https://www.toymoban.com/news/detail-793738.html
到了这里,关于一文让你对mysql索引底层实现明明白白的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!