使用方法

注意分页的字段需要在代码里面定制化修改,根据你爬取的接口,他的业务规则改代码中的字段。比如我这里总条数叫total,人家的不一定。返回的数据我这里是data.rows,看看人家的是叫什么字段,改改代码。再比如我这里的分页叫pageNum,人家的可能叫pageNo
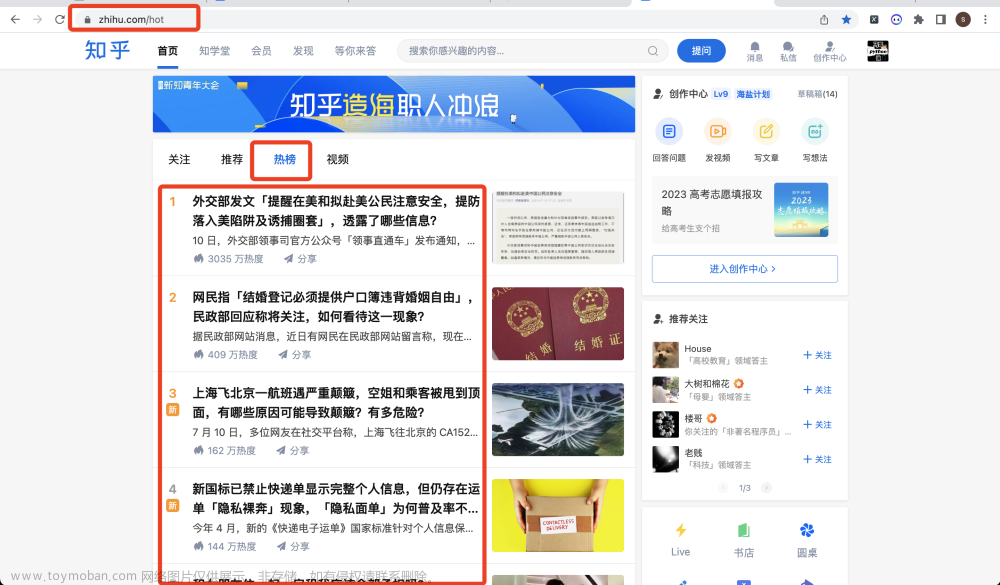
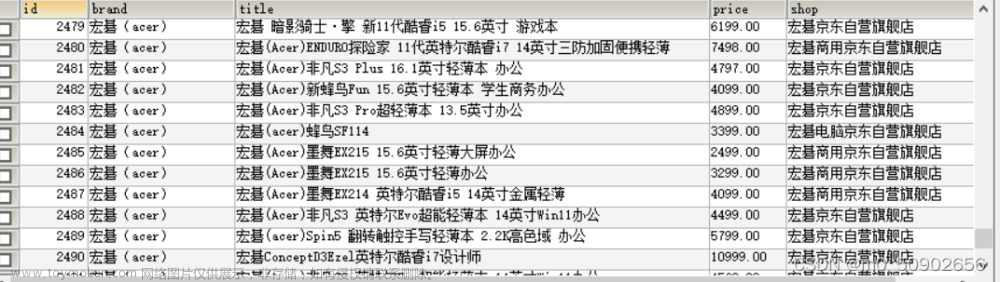
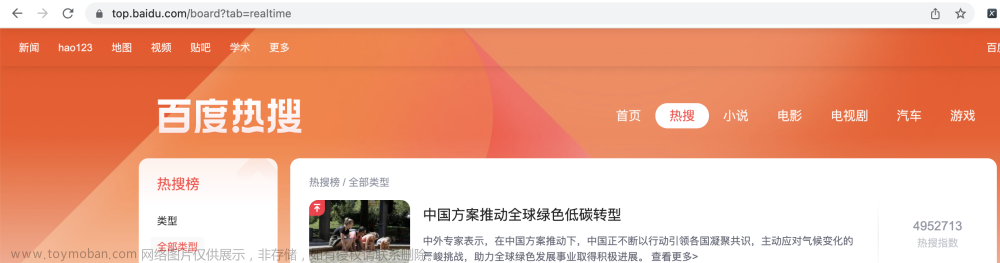
效果
分页下载
上源码
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>爬虫</title>
<style>
.container{
width: 50%;
margin: 50px auto;
}
input,
textarea {
height: 30px;
width: -webkit-fill-available;
margin-bottom: 15px;
}
textarea {
height: 120px;
}
button {
height: 40px;
width: 110px;
font-size: 18px;
}
#h1,
#h2 {
text-align: center;
}
</style>
</head>
<body>
<div class="container">
<div>
接口:<input id="api" type="text" /> <br />
请求头:<textarea id="headers" type="text" placeholder="要json格式"></textarea><br />
参数:<textarea id="textarea" placeholder="要json格式"></textarea>
</div>
<div style="text-align: right;">
<button onclick="crawling()">拉取</button>
</div>
<h1 id="h1"></h1>
<h2 id="h2"></h2>
</div>
<script>
var total = 0;
var pageNum = 1;
var pageSize = 30;
var api = "";
var headers = "";
var textarea = "";
const h1 = document.querySelector("#h1");
const h2 = document.querySelector("#h2");
async function crawling() {
api = document.querySelector("#api").value;
headers = document.querySelector("#headers").value;
textarea = document.querySelector("#textarea").value;
h1.innerHTML = "开始爬取...";
const data = await getData();
total = data.total;
const page = Math.ceil(total / pageSize);
saveFile(data.rows,`第 1 页 / 共${page}页`);
loading();
}
async function loading() {
const page = Math.ceil(total / pageSize);
h2.innerHTML = `一共${total}条,${page}页`;
for (let i = 1; i < page; i++) {
pageNum++;
h2.innerHTML = `一共${total}条,${page}页,正在第${i+1}页`;
const data = await getData();
saveFile(data.rows,`第${i+1}页 / 共${page}页`);
}
h1.innerHTML = "爬取完毕,已下载数据";
h2.innerHTML = "";
total = 0;
pageNum = 1;
}
async function getData() {
const response = await fetch(api, {
method: "POST",
mode: "cors",
cache: "no-cache",
credentials: "same-origin",
headers: {
"Content-Type": "application/json",
...JSON.parse(headers)
},
body: JSON.stringify({
...JSON.parse(textarea),
"pageSize": pageSize,
"pageNum": pageNum
})
});
return response.json();
}
function saveFile(data,name) {
const blob = new Blob([JSON.stringify(data)], {
type: "application/json"
});
let link = document.createElement("a"); // 创建下载的实体标签
link.href = URL.createObjectURL(blob); // 创建下载的链接
link.download = name + ".json"; // 下载的文件名
link.click(); // 执行下载
URL.revokeObjectURL(link.href); // 下载完成释放掉blob对象
}
</script>
</body>
</html>
开始在小小的网站里面爬呀爬呀爬吧…
还有一种
整体下载为一个文件
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>爬虫</title>
<style>
.container {
width: 50%;
margin: 50px auto;
}
input,
textarea {
height: 30px;
width: -webkit-fill-available;
margin-bottom: 15px;
}
textarea {
height: 120px;
}
button {
height: 40px;
width: 110px;
font-size: 18px;
}
#h1,
#h2,
#error {
text-align: center;
}
#error {
color: red;
}
</style>
</head>
<body>
<div class="container">
<div>
接口:<input id="api" type="text" /> <br />
token:<input id="token" type="text" /><br />
参数:<textarea id="textarea" placeholder="要json格式"></textarea>
</div>
<div style="text-align: right;">
<button onclick="crawling()">拉取</button>
</div>
<h1 id="h1"></h1>
<h2 id="h2"></h2>
<p id="error"></p>
</div>
<script>
var total = 0;
var datas = [];
var pageNum = 1;
var pageSize = 30;
var api = "";
var token = "";
var textarea = "";
const h1 = document.querySelector("#h1");
const h2 = document.querySelector("#h2");
const error = document.querySelector("#error");
async function crawling() {
api = document.querySelector("#api").value;
token = document.querySelector("#token").value;
textarea = document.querySelector("#textarea").value;
h1.innerHTML = "开始爬取...";
const res = await getData();
if (res.code !== 0) {
error.innerHTML = `第 1 页错误`;
return;
}
total = res.total;
datas.push(res.rows);
loading();
};
async function getData() {
const response = await fetch(api, {
method: "POST",
mode: "cors",
cache: "no-cache",
credentials: "same-origin",
headers: {
"Content-Type": "application/json",
Authorization: token
},
body: JSON.stringify({
...JSON.parse(textarea),
"pageSize": pageSize,
"pageNum": pageNum
})
});
return response.json();
};
async function loading() {
const page = Math.ceil(total / pageSize);
h2.innerHTML = `一共${total}条,${page}页`;
for (let i = 1; i < page; i++) {
pageNum++;
h2.innerHTML = `一共${total}条,${page}页,正在第${i+1}页`;
const res = await getData();
if (res.code !== 0) {
error.innerHTML += `第${i}页错误`;
continue;
}
datas.push(res.rows);
};
saveFile(datas);
h1.innerHTML = "爬取完毕,已下载数据";
reset();
};
function saveFile(data) {
const blob = new Blob([JSON.stringify(data)], {
type: "application/json"
});
let link = document.createElement("a"); // 创建下载的实体标签
link.href = URL.createObjectURL(blob); // 创建下载的链接
link.download = "数据" + ".json"; // 下载的文件名
link.click(); // 执行下载
URL.revokeObjectURL(link.href); // 下载完成释放掉blob对象
};
function reset() {
h2.innerHTML = "";
total = 0;
pageNum = 1;
datas = [];
};
</script>
</body>
</html>

拓展
怎么爬取微信小程序的接口?
使用Charles 拿到接口、请求头、参数,再回来使用界面爬取文章来源:https://www.toymoban.com/news/detail-794076.html
node方式爬取文章来源地址https://www.toymoban.com/news/detail-794076.html
到了这里,关于前端远原生js爬取数据的小案例的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!