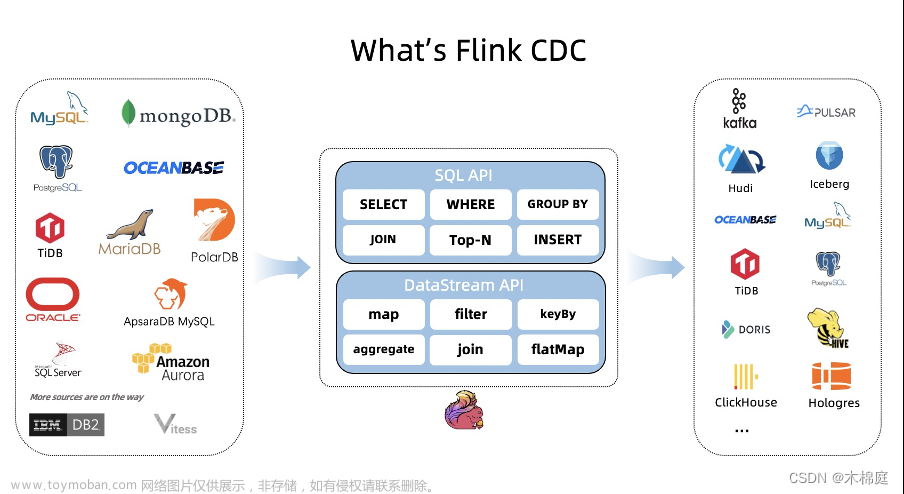
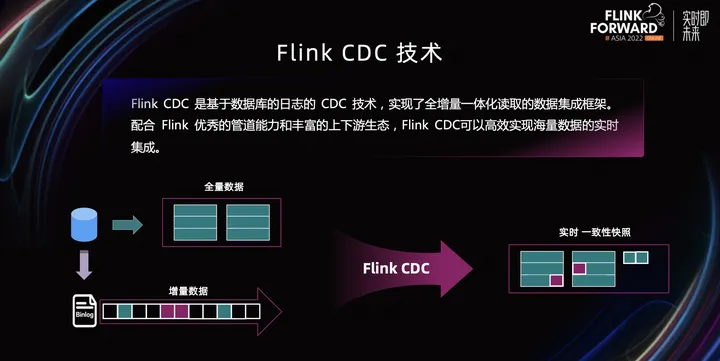
一、CDC简介
cdc全称 Change Data Capture 变更数据捕获。通俗来讲只要能捕获到变更的数据的技术都可以称为cdc。常见的开源技术有以下几种:
canal:https://github.com/alibaba/canal
maxwell:https://github.com/zendesk/maxwell
Debezium:https://github.com/debezium/debezium
flink-cdc:https://github.com/ververica/flink-cdc-connectors
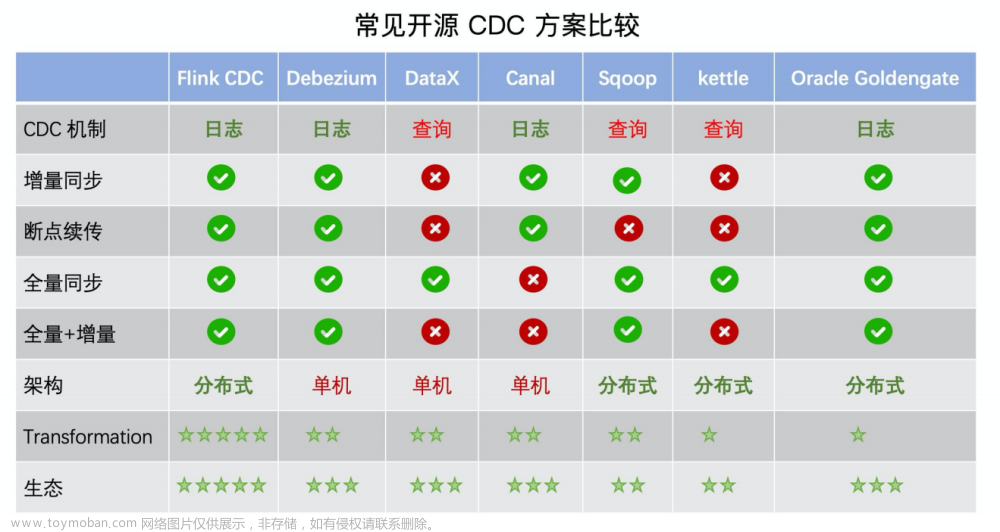
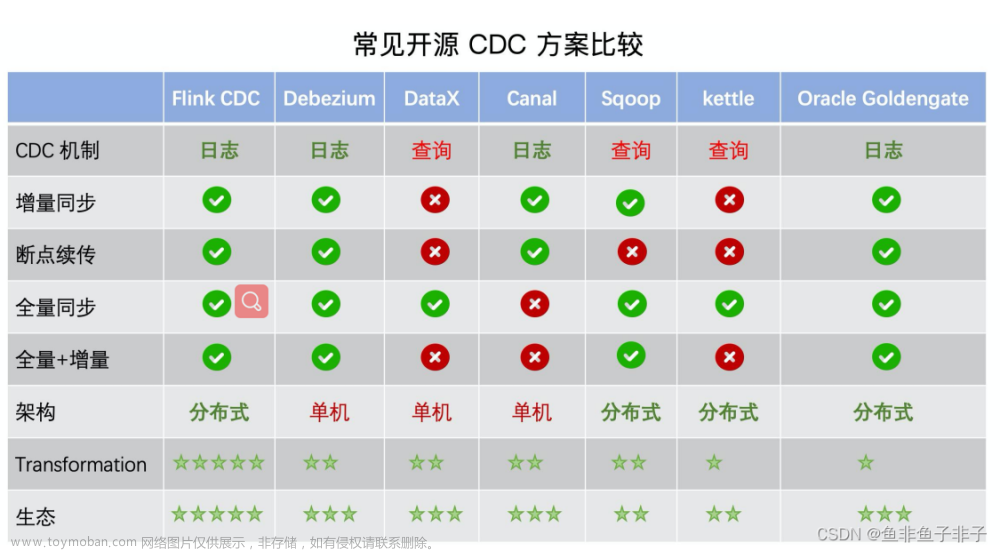
以下是几种技术的横向对比
二、canal+maxwell
两者实现原理类似。canal模拟mysql主从复制过程,把自己当做从库。通过dump操作把binlog从主库读取到从库,然后根据binlog进行数据还原。maxwell原理同理。两者区别在于maxwell是一款轻量级框架,可拓展性较少。比如它支持处理json格式数据,并把数据发送到kafka、redis等中。而canal可以自定义数据格式,而且并不局限于将数据发送到特定的数据存储介质中。
下面以canal举例说明:
2.1 安装canal
安装很简单,选择release版本下载解压即可:https://github.com/alibaba/canal/releases?page=2。
这里需要说明的是deployer是个人开发版。
2.2 配置canal
下载解压完成之后如下:
进入conf/example/instance.porperties中修改如下配置
在canal安装目录下的conf下找到canal.properties,主要修改数据需要发送的介质。默认配置是tcp,这个可以自定义将数据写入到其他地方,如果需要将canal采集到的数据写入kafka topic就选择第二种。
配置完成之后启动:/bin/startup.sh
2.3 配置mysql binlog
mysql数据源需要提前开启binlog,找到my.cnf配置如下:
然后重启mysql服务。
登录mysql执行一下,然后查看是on就代表开启成功
2.4代码实现
pom依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.4</version>
</dependency>
import com.alibaba.fastjson.JSON;
import com.alibaba.google.common.base.CaseFormat;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.HashMap;
import java.util.List;
public class CanalClientApp {
public static void main(String[] args) throws Exception{
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), //本地部署就用localhost,端口默认
"example", null, null);
//设置死循环,一直访问connector中数据
while (true){
connector.connect(); //进行链接
connector.subscribe("test.*");//设置需要监控的库表
Message message = connector.get(100);//设置获取一批数据量大小
List<CanalEntry.Entry> entries = message.getEntries(); //获取一批消息的list集合
if(entries.size() > 0){ //如果list中有数据就遍历取出
for (CanalEntry.Entry entry : entries) {
String tableName = entry.getHeader().getTableName(); //获取header中请求到的表名
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(entry.getStoreValue());//value值转换成string类型
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
//insert update delete ...
CanalEntry.EventType eventType = rowChange.getEventType();
if(eventType == CanalEntry.EventType.INSERT){
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
HashMap<String, String> map = new HashMap<>();
for (CanalEntry.Column column : afterColumnsList) {
String key = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, column.getName());
map.put(key, column.getValue());
}
/**
* TODO...
* 到这一步,下面要做的事情就是把map的数据发送到想要的地方去...
*/
System.out.println("tableName:"+ tableName + " , " + JSON.toJSONString(map));
}
}
}
}
}
}
}
mysql写入数据:
idea实时打印输出
三、Debezium+Flink-CDC
Debezium是为Kafka Connect而建的一系列Source Connectors,每个Source Connector会根据对应数据库特性来捕获数据变更记录。不像其他方法,例如,轮询或者双写等。Debezium是基于日志进行捕获变更的。而flink-cdc(1.x版本)和Debezium一脉相承。接下来通过案例简单了解下flink-cdc的使用方式。
3.1 flink-cdc解析


官方社区的解析已经很清晰明了,通过两种方式对比发现,flink-cdc节省了很大一部分运维成本。传统etl中flink只负责计算,而flink-cdc将采集计算为一体。当然看到了flink-cdc的优势,也需要了解当前版本(1.x)的局限性。因为flink-cdc底层采用了Debezium框架,数据读取分为全量+增量模式。在全量读取数据的时候为了保证数据一致性会加上一个全局锁,如果数据量非常大读取数据会以小时级别计算。切如果在全量读取阶段任务运行失败是无法进行checkpoint的。
简单来说,flink-cdc第一阶段读取全量数据时默认会加一个全局锁,会拒绝其他事务提交update操作,这样可以保证数据一致性,但数据量特别大时,可能会导致数据库hang住。
于是官方又更新了flink-cdc 2.x版本。这个版本主要解决锁还有无法checkpoint的问题。主要原理是chunk算法+SourceEnumerator组件实现。
flink-cdc 2.x版本读取流程如上图所述,首先根据chunk算法对binlog进行切片。每个i切片分区内数据不重合。正在读写的切片如果有数据更新的话,会将更新后的数据输出。从而实现不加锁的方式下保证数据读的一致性。
3.2 flink-cdc读取mysql binlog数据
实现方式分为两种:https://ververica.github.io/flink-cdc-connectors/master/content/overview/cdc-connectors.html#usage-for-datastream-api
Datastream Api
pom依赖里需要添加如下:
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.3.0</version>
<scope>provided</scope>
</dependency>
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlBinlogSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // 默认json反序列化器,进阶版可以用自定义反序列化器
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}
}
Table Api文章来源:https://www.toymoban.com/news/detail-794492.html
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkTableCDCApp {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableenv = StreamTableEnvironment.create(env);
env.setParallelism(1);
tableenv.executeSql("create table mysql_bin(" +
"id INT primary key, " +
"name STRING" +
") with(" +
"'connector' = 'mysql-cdc'," +
"'hostname' = 'ip'," +
"'port' = '3306'," +
"'username' = 'yourUsername'," +
"'password' = 'yourPassword'," +
"'database-name' = 'yourDatabaseName'," +
"'table-oname' = 'yourTableName'" +
")"
);
Table table = tableenv.sqlQuery("select * from mysql_bin");
tableenv.toRetractStream(table, Row.class).print();
env.execute();
}
}
这里需要注意的是当前只是本地编译,没有提交flink。如果任务上环境提交运行需要提前将此jar放在FLINK_HOME/lib/目录下去。
还需要有一点说明的是,我在本地编译的时候选择flink-cdc的版本是1.x,如上图。实际上不同版本的flink-cdc对应的flink版本都不同。以下版本对应关系。 文章来源地址https://www.toymoban.com/news/detail-794492.html
文章来源地址https://www.toymoban.com/news/detail-794492.html
到了这里,关于Flink学习13-Flink CDC的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!