实验目的
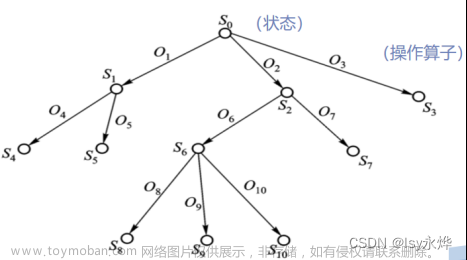
熟悉和掌握启发式搜索的定义、估价函数和算法过程
实验平台
Python 3.7 +
实验要求
熟练掌握A*算法的基本原理。分析不同启发式函数对问题求解的提升效果。
- 实现A*算法的求解,要求设计两种不同的估价函数:设置相同的初始状态和目标状态,针对不同估价函数,求得问题的届,比较它们对搜索算法性能的影响,包括扩展节点数、生成节点数、运行时间等。
- 画出流程图。
- 源程序代码
实验结果(可以包含数据集分析、实验过程、结果截图、结果分析等)
- 八数码问题
- 不同的估价函数对搜索算法性能的影响
(1)、曼哈顿距离:曼哈顿距离是八数码问题中常用的估价函数之一。在这个算法中,每个状态都会计算曼哈顿距离,并将距离加入优先队列中。曼哈顿距离具有良好的准确性和高效性,因此在这个算法中表现良好。
(2)、欧几里得距离:欧几里得距离是另一个常用的估价函数。在这个算法中,每个状态都会计算欧几里得距离,并将距离加入优先队列中。与曼哈顿距离相比,欧几里得距离可以更好地反映状态之间的真实距离,但是由于它需要进行平方根计算,因此计算成本更高。
(3)、切比雪夫距离:切比雪夫距离是一种更为简单的估价函数,它只需要取两个状态之间横向和纵向距离的最大值。在这个算法中,每个状态都会计算切比雪夫距离,并将距离加入优先队列中。与曼哈顿距离相比,切比雪夫距离更为简单,计算成本更低,但它可能不如曼哈顿距离那么准确。
- 流程图

源程序代码
from queue import PriorityQueue
# 定义状态类
class State:
def __init__(self, board, moves, previous):
self.board = board
self.moves = moves
self.previous = previous
# 定义状态比较函数,用于在优先队列中比较状态
def __lt__(self, other):
return self.moves + self.manhattan_distance() < other.moves + other.manhattan_distance()
# 计算曼哈顿距离
def manhattan_distance(self):
distance = 0
for i in range(3):
for j in range(3):
if self.board[i][j] == 0:
continue
x, y = divmod(self.board[i][j] - 1, 3)
distance += abs(x - i) + abs(y - j)
return distance
# 判断状态是否为目标状态
def is_goal(self):
return self.board == [[1, 2, 3], [4, 5, 6], [7, 8, 0]]
# 获取当前状态的下一步状态
def get_next_states(self):
next_states = []
i, j = next((i, j) for i in range(3) for j in range(3) if self.board[i][j] == 0)
for x, y in ((i+1, j), (i-1, j), (i, j+1), (i, j-1)):
if 0 <= x < 3 and 0 <= y < 3:
board = [row[:] for row in self.board]
board[i][j], board[x][y] = board[x][y], board[i][j]
next_states.append(State(board, self.moves+1, self))
return next_states
# 获取从初始状态到达当前状态的路径
def get_path(self):
path = []
state = self
while state is not None:
path.append(state)
state = state.previous
return reversed(path)
# A*搜索算法
def solve(start_board):
start_state = State(start_board, 0, None)
queue = PriorityQueue()
queue.put(start_state)
visited = set()
while not queue.empty():
state = queue.get()
if state.is_goal():
return state.get_path()
if tuple(map(tuple, state.board)) in visited:
continue
visited.add(tuple(map(tuple, state.board)))
for next_state in state.get_next_states():
queue.put(next_state)
return None
# 测试代码
if __name__ == '__main__':
start_board = [[1, 2, 3], [4, 5, 6], [0, 7, 8]]
path = solve(start_board)
if path is None:
print("无解")
else:
for i, state in enumerate(path):
print(f"步骤 {i}:")
for row in state.board:
print(row)
- 5*5迷宫寻路问题
- 不同的估价函数对搜索算法性能的影响
(1)、切比雪夫距离估价函数:对于55迷宫的起点和目标点,在网格上可视为同一正方形角落的两个点。因此,用切比雪夫距离可以轻松快速地计算出任意两点之间的代价。使用切比雪夫距离作为估价函数的A算法可以有效地搜索整个网格,直接到达目标点,并尽可能少地探索其他节点。因此,此估价函数能够有效地提高搜索算法性能。
(2)、曼哈顿距离估价函数:曼哈顿距离是指两点之间横向和纵向的距离之和。在5*5迷宫中,使用曼哈顿距离可以快速估算出两点之间的代价,但是这种估价方式会导致搜索算法探索更多的区域,因此相比于切比雪夫距离估价函数,曼哈顿距离估价函数在搜索算法性能方面稍逊一筹。
(3)、欧几里得距离估价函数:欧几里得距离是指两点之间的直线距离。在5*5迷宫中,使用欧几里得距离可以准确地估算出两点之间的代价,但是此估价方式需要更多的计算资源,因此可能会导致搜索算法性能下降。
综上所述,在5*5迷宫寻路问题中,估价函数的选择对搜索算法性能具有重要影响,切比雪夫距离估价函数可以在这个问题中提高搜索算法性能。
- 流程图

源程序代码
import numpy as np
import heapq
class Node:
def __init__(self, x: int, y: int, parent=None):
self.x = x
self.y = y
self.parent = parent
self.g = 0
self.h = 0
def __lt__(self, other):
return self.g + self.h < other.g + other.h
def heuristic(a: tuple, b: tuple) -> int:
return abs(b[0] - a[0]) + abs(b[1] - a[1])
def astar(maze: np.array, start: tuple, end: tuple) -> list:
open_set = []
closed_set = set()
start_node = Node(start[0], start[1])
end_node = Node(end[0], end[1])
heapq.heappush(open_set, start_node)
while len(open_set) > 0:
current_node = heapq.heappop(open_set)
if current_node.x == end_node.x and current_node.y == end_node.y:
path = []
while current_node is not None:
path.append((current_node.x, current_node.y))
current_node = current_node.parent
return path[::-1]
closed_set.add((current_node.x, current_node.y))
for x, y in [(0, -1), (0, 1), (-1, 0), (1, 0)]:
node = Node(current_node.x + x, current_node.y + y, current_node)
if node.x < 0 or node.y < 0 or node.x >= maze.shape[0] or node.y >= maze.shape[1]:
continue
if maze[node.x][node.y] == 1:
continue
if (node.x, node.y) in closed_set:
continue
node.g = current_node.g + 1
node.h = heuristic((node.x, node.y), (end_node.x, end_node.y))
heapq.heappush(open_set, node)
return None
if __name__ == '__main__':
start = (0, 0)
end = (4, 4)
maze = np.array([
[0, 0, 0, 0, 1],
[1, 1, 1, 0, 1],
[0, 0, 0, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 0]
])
path = astar(maze, start, end)
print(path)
实验总结
通过这次实验,我掌握了如何使用A*搜索算法解决迷宫问题和八数码问题。这是一种常用的人工智能搜索算法,可以用于寻找路径和规划。
在实验中,首先学习了迷宫问题的定义和A算法的基本思路。我们使用Python编写代码,在55大小的迷宫中,通过A*算法计算出从起点到终点的最短路径。其中,需要考虑迷宫的障碍物、每个节点的代价值和启发式函数等因素,也需要用到优先队列来存储待扩展的节点。最后,通过绘制迷宫地图和标注路径,完成了实验任务。
接着,学习了八数码问题的定义和A算法的适用性。同样利用Python编写代码,通过A算法计算出从初始状态到目标状态的最短路径。在实验中,为了提高算法效率和减少搜索深度,设计了一种简单而可行的启发式函数,并使用优先队列存储待扩展的节点,最终完成了实验任务。文章来源:https://www.toymoban.com/news/detail-794498.html
通过这次实验,除了掌握了A*搜索算法的应用,还进一步了解了Python的函数定义语法和相关知识,同时也加深了对算法原理和机制的理解。文章来源地址https://www.toymoban.com/news/detail-794498.html
到了这里,关于人工智能之A*算法求解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!