😄伙伴们,好久不见!这里是 叶苍ii
❀ 作为一名大数据博主,我一直致力于分享最新的技术趋势和实战经验。近期,我在参加Flink的顾客营销项目,使用了PyFlink项目进行数据处理和分析。
❀ 在这个文章合集中,我将与大家分享我的实战经验,探索PyFlink项目的魅力。
2.1. 了解Flink框架
了解集群结构/角色
了解程序结构:Source、Sink、算子、taskManager、Jobmanager、Task等概念
了解编程模型:有界、无界、批处理
了解编码模板
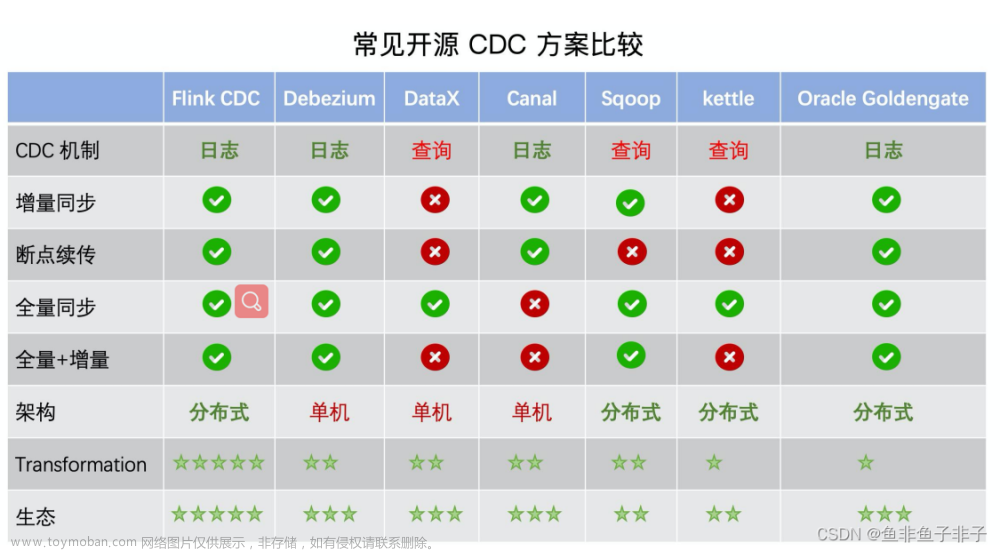
先上图:

2.1.1. Flink简介
Flink是一个开源的流处理和批处理框架,具有高吞吐量、低延迟和容错性等特点。
它支持事件驱动的流处理模型,可以处理实时数据流和批量数据集。
2.1.2. Flink、Spark、MR 区别
MapReduce、Spark和Flink都是用于大数据处理的分布式计算框架,但它们在设计理念和功能上有一些区别。
设计理念:
- MapReduce:MapReduce是一种简化的编程模型,主要关注数据的并行处理和分布式计算。它适合批处理任务,但对于迭代计算和实时处理等场景相对不够灵活。
- Spark:Spark是一个通用的分布式计算引擎,提供了更丰富的API和功能,包括批处理、交互式查询、流处理和机器学习等。它通过内存计算和弹性数据集(Resilient Distributed Datasets,RDD)的概念,实现了高效的数据处理和迭代计算。
- Flink:Flink是一个流式处理引擎,专注于实时数据处理和流式计算。它支持事件时间和处理时间,并提供了窗口操作、状态管理和容错机制等功能,使得实时数据处理更加灵活和可靠。
数据处理模型:
- MapReduce:MapReduce采用了经典的Map和Reduce操作模型,适合处理离散的批量数据。它将数据切分成小块进行并行处理,并通过中间结果的合并来得到最终结果。
- Spark:Spark引入了弹性数据集(RDD)的概念,它是一个可分布式计算的不可变数据集合。Spark提供了丰富的转换操作(如map、filter、reduce等)和动作操作(如count、collect等),可以在内存中高效地进行数据处理和迭代计算。
- Flink:Flink支持流式处理和批处理,并提供了统一的编程模型。它将数据视为无限的流,可以对流进行窗口操作、状态管理和复杂的流处理逻辑。
执行引擎:
- MapReduce:MapReduce使用了分布式文件系统(如HDFS)和资源管理器(如YARN)来管理任务的调度和执行。
- Spark:Spark引擎通过自己的集群管理器(如Standalone、YARN或Mesos)来管理任务的调度和执行。它还提供了交互式Shell和图形化界面,方便开发者进行调试和监控。
- Flink:Flink引擎具有自己的分布式运行时,可以独立地管理任务的调度和执行。它支持故障恢复和容错机制,可以保证数据处理的可靠性和一致性。
总体而言,MapReduce适用于简单的批处理任务,Spark适用于更广泛的数据处理场景,而Flink则专注于实时数据处理和流式计算。选择哪个框架取决于具体的需求和应用场景。
2.1.3. Flink集群角色:taskManager、Jobmanager、Task
在Apache Flink中,提交任务和执行任务有几个关键组件:Client、TaskManager、JobManager和Task。

2.1.3.1. Client(客户端):
代码由客户端获取并且做转换,之后提交给Jobmanger
2.1.3.2. JobManager(作业管理器):
相当于"管理者"
- JobManager是Flink集群中的主节点,负责整个作业的管理和调度。它负责接收用户提交的作业,并将作业进行解析、优化和分配给TaskManager执行。
- JobManager维护着整个作业的执行状态和元数据信息,并负责故障恢复和容错机制。它会监控TaskManager的健康状态,并在需要时重新分配任务或重启失败的任务。
- JobManager还提供了Web界面和REST API,用于作业的监控、管理和查询。
2.1.3.3. TaskManager(任务管理器):
相当于"工作者"/“干活的人”,进行数据处理操作。
- TaskManager是Flink集群中的工作节点,负责执行具体的任务。每个TaskManager可以运行多个任务,并且可以在不同的机器上进行分布式部署。
- TaskManager负责接收来自JobManager的任务分配,并根据任务的需求进行资源分配和管理。它会将任务划分为多个子任务(Subtask),并通过线程池来执行这些子任务。
- TaskManager还负责与其他TaskManager之间进行数据交换和通信,以支持任务之间的数据流转和协调。
2.1.3.4. Task(任务):
- Task是Flink中最小的执行单元,它是作业中实际执行的计算任务。一个作业可以由多个Task组成,每个Task负责处理数据的一部分。
- Task接收输入数据,并通过用户定义的操作(如map、filter、reduce等)对数据进行处理和转换。它还负责将处理结果发送给下游的Task或输出到外部系统。
- Task之间通过网络进行数据交换和通信,以实现数据流的传递和协调。
总结:
在Flink中,TaskManager是执行具体任务的工作节点,负责任务的执行和资源管理;
JobManager是整个作业的管理节点,负责作业的调度和故障恢复;
Task是最小的执行单元,负责具体的数据处理和计算操作。这三个组件共同协作,实现了Flink的分布式计算和流式处理能力。
2.1.3.5. 举例:select city,sum(xxx) from table A group by city ;
Select(选择)操作
- Select操作用于选择需要的字段或列,并可以进行一些简单的转换和计算。例如,从输入数据中选择特定的列,或者对某些列进行数值运算。
- Select操作通常由一个或多个Task来执行。每个Task负责处理输入数据的一部分,并根据选择条件和转换规则进行相应的处理。
Sum(求和)操作:
- Sum操作用于对某个字段或列进行求和计算。它通常结合Group By操作使用,将输入数据按照指定的字段进行分组,然后对每个分组内的数据进行求和。
- 在Flink中,Sum操作也可以由一个或多个Task来执行。每个Task负责处理输入数据的一部分,并根据分组键进行数据分组和求和计算。
Group By(分组)操作:
- Group By操作用于将输入数据按照指定的字段进行分组。它将具有相同分组键的数据划分到同一个组中,以便进行聚合操作(如求和、平均值等)。
- 在Flink中,Group By操作通常涉及到数据重分区和洗牌操作,以确保具有相同分组键的数据被发送到同一个Task进行处理。
数据集:
A 1
A 2
B 3
A 1
B 3
A 1
具体的任务划分和调度策略取决于Flink的配置和算法。
2.1.4. Flink程序结构
Flink程序的结构组件为Source、Transformation和Sink

2.1.4.1. Source
Source(数据源):Source是Flink程序的起点,用于读取输入数据。
从各种数据源(如文件、消息队列、Socket等)读取数据,并将其转化为Flink内部的数据流。
2.1.4.2. Transformation--》算子
Transformation(转换操作):Transformation是对数据流进行处理和转换的操作。
包括各种数据转换、过滤、聚合、分组等操作,用于对输入数据进行加工和处理。
Flink提供了丰富的转换操作函数和算子,可以根据需求进行灵活的数据处理。
2.1.4.3. Sink
Sink(数据接收器):Sink是Flink程序的终点,用于将处理后的数据输出到外部系统或存储介质。它可以将数据写入文件、数据库、消息队列等目标,或者发送给其他应用程序进行进一步处理。
2.1.5. 编程模型:有界、无界
Flink是一个流式处理框架,它支持有界数据集(Batch)和无界数据流(Streaming)的处理。这使得Flink具备了灵活处理不同类型数据的能力。
- 有界数据集(Batch Processing):有界数据集是指在处理之前已经存在的、有限大小的数据集合。在有界数据集模型中,Flink会将整个数据集加载到内存中进行处理。这种模型适用于离线批处理任务,如数据分析、报表生成等。Flink提供了丰富的转换操作和算子,可以对有界数据集进行高效的批处理。

- 无界数据流(Stream Processing):无界数据流是指以连续、无限的方式产生的数据流。在无界数据流模型中,Flink会实时地处理数据流,并根据事件时间或处理时间进行窗口操作、聚合、过滤等实时计算。这种模型适用于实时数据处理场景,如实时监控、实时推荐等。Flink提供了强大的流处理功能,支持事件时间处理、状态管理、容错机制等。

Flink编程模型的关键概念是“流”(Stream)和“转换”(Transformation)。在Flink中,数据被视为连续的流,通过一系列的转换操作来实现数据的加工和处理。转换操作可以包括数据转换、过滤、聚合、分组等操作,用于对输入数据进行处理。Flink提供了丰富的转换操作函数和算子,可以根据需求进行灵活的数据处理。
无论是有界数据集还是无界数据流,Flink都提供了统一的编程接口和API,使得开发者可以使用相同的编程模型来处理不同类型的数据。这种统一的编程模型使得Flink非常适合在实时和离线场景中进行大规模数据处理和分析。
2.1.6. 编程固定模式:
- 创建执行环境
- 读取源数据
- 转换数据
- 输出转换结果
- 触发任务执行
了解完Flink,此合集的下集<搭建PyFLink环境>、<PyFLink的WordCount编程>,我们会继续讲解:
(2)要搭建PyFlink环境,我们需要准备什么内容文章来源:https://www.toymoban.com/news/detail-794631.html
(3)PyFLink的WordCount编程文章来源地址https://www.toymoban.com/news/detail-794631.html
到了这里,关于Flink实战(1)-了解Flink的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[Flink01] 了解Flink](https://imgs.yssmx.com/Uploads/2024/02/827570-1.png)






