机器学习中的数据处理和特征工程是非常关键的步骤,它们直接影响模型的性能和泛化能力。以下是一些常见的数据处理和特征工程技术:
数据处理:
-
缺失值处理: 处理数据中的缺失值,可以选择删除缺失值、填充均值/中位数/众数,或使用插值方法。
-
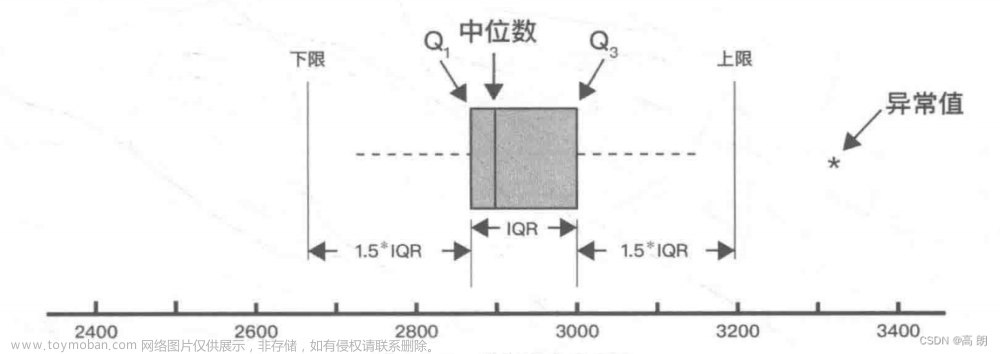
异常值处理: 检测和处理异常值,可以使用统计方法或基于模型的方法。
-
数据标准化和归一化: 将不同特征的值范围缩放到相似的尺度,以避免某些特征对模型的影响过大。
-
类别特征编码: 将分类变量转换为模型可以处理的格式,如独热编码或标签编码。
-
日期和时间处理: 提取有用的信息,如年份、月份、星期几等,可以帮助模型捕捉时间相关的模式。
-
数据分割: 将数据集分为训练集、验证集和测试集,以便评估模型的泛化性能。
特征工程:
-
特征选择: 选择最相关的特征,去除冗余信息,减少模型复杂性。
-
衍生特征: 根据现有特征创建新的特征,以提供更多信息。
-
多项式特征: 将特征的多项式组合加入数据,以捕捉特征之间的非线性关系。
-
文本特征处理: 对文本数据进行向量化,可以使用词袋模型、TF-IDF等方法。
-
特征缩放: 将特征缩放到相似的范围,以避免某些特征对模型的影响过大。
-
特征交叉: 将不同特征进行组合,创造新的特征,以便更好地捕捉数据之间的关系。
-
Embedding: 对类别型特征进行嵌入表示,将其映射到低维空间。
-
处理高维数据: 使用降维技术如主成分分析(PCA)或 t-SNE 处理高维数据。
-
滑动窗口: 对时间序列数据应用滑动窗口,以提取滚动统计信息。文章来源:https://www.toymoban.com/news/detail-794712.html
以上这些技术在实际应用中通常结合使用,具体选择取决于数据集的特点和机器学习任务的要求。数据处理和特征工程的质量直接关系到模型的性能和泛化能力,因此需要仔细调整和优化这些步骤。文章来源地址https://www.toymoban.com/news/detail-794712.html
到了这里,关于机器学习:数据处理与特征工程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!