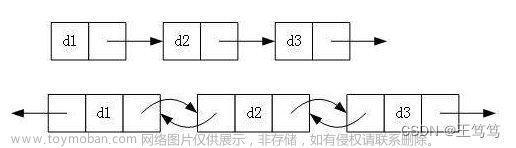
上篇内容给大家带来了单链表的构建,那么本期内容继续给大家带来链表的相关内容----双向链表。
什么是双向链表?双向链表与单链表有什么区别?
在单链表中,咱们每个结点的指针域存放了后继指针,以便于链接每个结点,随后讲到按位查找,从头结点开始,设置工作指针来不断延续搜索,然后找到该结点并返回其位置,But如果我们想要找到该结点的前驱结点怎么办呢?因为我们每个结点的指针域存放的是后继结点的地址,所以我们还需要重新查找该链表,那么这个时候的时间复杂度会有所提升,这个时候我们就要使用双向链表了。
双向链表与单链表的区别无非是其指针域内存放的是前驱结点的地址和后继节点的位置。那么我们采用结构体的形式来定义双向链表:
typedef struct Node
{
int data;//数据域
struct Node* prior;//前驱
struct Node* next;//后继
}node,*linklist;我们了解到了双向链表的定义,接下俩我们就要探讨插入操作了。
我们在插入一个结点的时候要保证其与前后结点能够链接,而双向链表每两个结点之间拥有两条线,所以这个时候就需要链接四条线(两前驱+两后继),举个例子:当前要把结点p插入到结点s的后面:p的前驱指向s,p的后继指向s的后继,s的后继指向p,s的后继的前驱指向p。
p->prior = s;
p->next = s->next;
s->next = p;
s->next->prior = p;完整的插入代码与单链表的代码差不多,这里就不给大家展示了,大家可以看我上期博客讲述的单链表的插入。
接下来咱们该说一下如何删除结点p?
首先我们要断开四条线,让p的前驱与p的后继链接起来,所以就只需要链接两条线就可以了。
p的前驱的后继指向p的后继,p的后继的前驱指向p的前驱。
p-prior->next = p->next;
p->next->prior = p->prior;其实理解也就是表述p的前后地址,然后让p的前驱与p的后继相连的过程。
想删除建立的双向链表,直接构造一个析构函数,设置一个工作指针(负责记录删除的结点的指针域指向的位置),用delete释放就over了。文章来源:https://www.toymoban.com/news/detail-795017.html
好了本期内容就到这里了,感谢收看,希望给个三连支持。文章来源地址https://www.toymoban.com/news/detail-795017.html
到了这里,关于双向链表的构建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!