《Flink 详解》系列(已完结),共包含以下 10 10 10 篇文章:
- 【大数据】Flink 详解(一):基础篇(架构、并行度、算子)
- 【大数据】Flink 详解(二):核心篇 Ⅰ(窗口、WaterMark)
- 【大数据】Flink 详解(三):核心篇 Ⅱ(状态 State)
- 【大数据】Flink 详解(四):核心篇 Ⅲ(Checkpoint、Savepoint、Exactly-Once)
- 【大数据】Flink 详解(五):核心篇 Ⅳ(反压、序列化、内存模型)
- 【大数据】Flink 详解(六):源码篇 Ⅰ(作业提交、Local 方式、YARN 方式、K8s 方式)
- 【大数据】Flink 详解(七):源码篇 Ⅱ(作业图、执行图、调度、作业生命周期、Task Slot)
- 【大数据】Flink 详解(八):SQL 篇 Ⅰ(Flink SQL)
- 【大数据】Flink 详解(九):SQL 篇 Ⅱ(Flink SQL CEP)
- 【大数据】Flink 详解(十):SQL 篇 Ⅲ(Flink SQL CDC)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
82.Flink SQL 有没有使用过?
在 Flink 中,一共有四种级别的抽象,而 Flink SQL 作为最上层,是 Flink API 的一等公民。

在标准 SQL 中,SQL 语句包含四种类型
-
数据操作语言(
DML,Data Manipulation Language):用来定义数据库记录(数据)。 -
数据控制语言(
DCL,Data Control Language):用来定义访问权限和安全级别。 -
数据查询语言(
DQL,Data Query Language):用来查询记录(数据)。 -
数据定义语言(
DDL,Data Definition Language):用来定义数据库对象(库,表,列等)。
Flink SQL 包含 DML 数据操作语言、 DDL 数据定义语言, DQL 数据查询语言,不包含 DCL 语言。
🚀 可以参考我的这篇博客:【数据库】DDL、DML、DCL简介
83.Flink 被称作流批一体,那从哪个版本开始,真正实现流批一体的?
从 1.9.0 版本开始,引入了阿里巴巴的 Blink ,对 FIink TabIe & SQL 模块做了重大的重构,保留了 Flink Planner 的同时,引入了 Blink PIanner,没引入以前,Flink 没考虑流批作业统一,针对流批作业,底层实现两套代码,引入后,基于流批一体理念,重新设计算子,以流为核心,流作业和批作业最终都会被转为 transformation。
84.Flink SQL 使用哪种解析器?
Flink SQL 使用 Apache Calcite 作为解析器和优化器。
Calcite 一种动态数据管理框架,它具备很多典型数据库管理系统的功能 如 SQL 解析、 SQL 校验、 SQL 查询优化、 SQL 生成 以及 数据连接查询 等,但是又省略了一些关键的功能,如 Calcite 并不存储相关的元数据和基本数据,不完全包含相关处理数据的算法等。
85.Calcite 主要功能包含哪些?
Calcite 主要包含以下五个部分:
-
SQL 解析(
Parser)- Calcite SQL 解析是通过 JavaCC 实现的,使用 JavaCC 编写 SQL 语法描述文件,将 SQL 解析成未经校验的 AST 语法树。
-
SQL 校验(
Validato)- 无状态的校验:即验证 SQL 语句是否符合规范。
- 有状态的校验:即通过与元数据结合验证 SQL 中的 Schema、Field、 Function 是否存在,输入输出类型是否匹配等。
-
SQL 查询优化
- 对上个步骤的输出(RelNode,逻辑计划树)进行优化,得到优化后的物理执行计划。优化有两种:基于规则的优化 和 基于代价的优化,后面会详细介绍。
-
SQL 生成
- 将物理执行计划生成为在特定平台 / 引擎的可执行程序,如生成符合 MySQL 或 Oracle 等不同平台规则的 SQL 查询语句等。
-
数据连接与执行
- 通过各个执行平台执行查询,得到输出结果。 在 Flink 或者其他使用 Calcite 的大数据引擎中,一般到 SQL 查询优化即结束,由各个平台结合 Calcite SQL 代码生成和平台实现的代码生成,将优化后的物理执行计划组合成可执行的代码,然后在内存中编译执行。
86.Flink SQL 处理流程说一下?
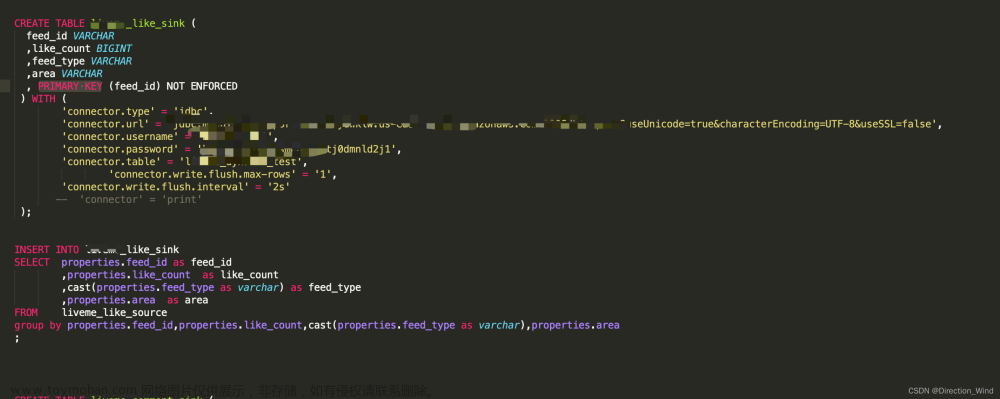
下面举个例子,详细描述一下 Flink SQL 的处理流程,如下所示:
SET table.sql-dialect=default;
CREATE TABLE log_kafka (
user_id STRING,|
order_amount DOUBLE,
log_ts TIMESTAMP(3),
WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND
) WITH (
'connector'='kafka',
'property-version' = 'universal',
'topic' = 'test',
'properties.bootstrap.servers'= 'hlink163:9092',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'properties.group.id' = 'flink1'
);
我们写一张 Source 表,来源为 Kafka,当执行 create table log_kafka 之后 Flink SQL 将做如下操作:

- 首先,Flink SQL 底层使用的是 Apache Calcite 引擎来处理 SQL 语句,Calcite 会使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的
Parser.jj文件,生成一系列的 Java 代码,生成的 Java 代码会 把 SQL 转换成 AST 抽象语法树(即 SqlNode 类型)。 - 生成的 SqlNode 抽象语法树,它是一个未经验证的抽象语法树,这时,SQL Validator 会获取 Flink Catalog 中的元数据信息来验证 SQL 语法,元数据信息检查包括表名,字段名,函数名,数据类型等检查。然后生成一个校验后的 SqlNode。
- 到达这步后,只是将 SQL 解析到 Java 数据结构的固定节点上,并没有给出相关节点之间的关联关系以及每个节点的类型信息。所以,还 需要将 SqlNode 转换为逻辑计划,也就是 LogicalPlan,在转换过程中,会使用
SqlToOperationConverter类,来将 SqlNode 转换为 Operation,Operation 会根据 SQL 语法来执行创建表或者删除表等操作,同时FlinkPlannerImpl.rel()方法会将 SqlNode 转换成 RelNode 树,并返回 RelRoot。 - 第 4 步将执行 Optimize 操作,按照预定义的优化规则 RelOptRule 优化逻辑计划。Calcite 中的优化器 RelOptPlanner 有两种,一是基于规则优化(
RBO)的HepPlanner,二是基于代价优化(CBO)的VolcanoPlanner。然后得到优化后的 RelNode, 再基于 Flink 里面的rules将优化后的逻辑计划转换成物理计划。 - 第 5 步,执行 Execute 操作,会通过代码生成
transformation,然后递归遍历各节点,将 DataStreamRelNode 转换成 DataStream,在这期间,会依次递归调用DataStreamUnion、DataStreamCalc、DataStreamScan类中重写的translateToPlan方法。递归调用各节点的translateToPlan,实际是利用 CodeGen 元编成 Flink 的各种算子,相当于直接利用 Flink 的 DataSet 或者 DataStream 开发程序。 - 最后进一步编译成可执行的 JobGraph 提交运行。
87.Flink SQL 包含哪些优化规则?
下图为执行流程图:
总结就是:
- 先解析,然后验证,将 SqlNode 转化为 Operation 来创建表,然后调用
rel方法将 SqlNode 变成逻辑计划(RelNodeTree),紧接着对逻辑计划进行优化。 - 优化之前,会根据 Calcite 中的优化器中的基于规则优化的 HepPlanner 针对四种规则进行预处理,处理完之后得到 Logic RelNode,紧接着使用代价优化的 VolcanoPlanner 使用
Logical_Opt_Rules(逻辑计划优化)找到最优的执行 Planner,并转换为 Flink Logical RelNode。 - 最后运用 Flink 包含的优化规则,如
DataStream_Opt_Rules(流式计算优化)、DataStream_Deco_Rules(装饰流式计算优化),将优化后的逻辑计划转换为物理计划。
优化规则包含如下:
-
子查询优化:
Table_subquery_rules -
扩展计划优化:
Expand_plan_rules -
扩展计划优化:
Post_expand_clean_up_rules -
正常化流处理:
Datastream_norm_rules -
逻辑计划优化:
Logical_Opt_Rules -
流式计算优化:
DataStream_Opt_Rules -
装饰流式计算优化:
DataStream_Deco_Rules
88.Flink SQL 中涉及到哪些 Operation?
先介绍一下什么是 Operation:在 Flink SQL 中,涉及的 DDL,DML,DQL 操作都是 Operation,在 Flink 内部表示,Operation 可以和 SqlNode 对应起来。
Operation 执行在优化前,执行的函数为 executeQperation,如下图所示,为执行的所有 Operation。

89.Flink Hive 有没有使用过?
Flink 社区在 Flink 1.11 版本进行了重大改变,如下图所示:
90.Flink 与 Hive 集成时都做了哪些操作?
如下所示为 Flink 与 Hive 进行连接时的执行图:
- Flink
1.1新引入了 Hive 方言,所以在 Flink SQL 中可以编写 Hive 语法,即 Hive Dialect。 - 编写 Hive SQL 后,FlinkSQL Planner 会将 SQL 进行解析,验证,转换成逻辑计划,物理计划,最终变成 Jobgraph。
- HiveCatalog 作为 Flink 和 Hive 的表元素持久化介质,会将不同会话的 Flink 元数据存储到 Hive Metastore 中。用户利用 HiveCatalog 可以将 Hive 表或者 Kafka 表存储到 Hive Metastore 中。
BlinkPlanner 是在 Flink 1.9 版本新引入的机制,Blink 的查询处理器则实现流批作业接口的统一,底层的 API 都是 Transformation。真正实现流 & 批的统一处理,替代原 FlinkPlanner 将流 & 批区分处理的方式。在 1.11 版本后已经默认为 Blink Planner。
91.HiveCatalog 类包含哪些方法?
重点方法如下:
HiveCatalog 主要是持久化元数据,所以一般的创建类型都包含,如 database、Table、View、Function、Partition,还有 is_Generic 字段判断等。
92.Flink SQL 1.11 新增了实时数仓功能,介绍一下?
Flink 1.11 版本新增的一大功能是实时数仓,可以实时的将 Kafka 中的数据插入 Hive 中,传统的实时数仓基于 Kafka + Flink Streaming,定义全流程的流计算作业,有着秒级甚至毫秒的实时性,但实时数仓的一个问题是历史数据只有
3
−
15
3-15
3−15 天,无法在其上做 Ad-hoc 的查询。
针对这个特点,Flink 1.11 版本将 FlieSystemStreaming Sink 重新修改,增加了分区提交和滚动策略机制,让 HiveStreaming Sink 重新使用文件系统流接收器。
Flink 1.11 的 Table / SQL API 中,FileSystemConnector 是靠增强版 StreamingFileSink 组件实现,在源码中名为 StreamingFileWriter。
只有在 Checkpoint 成功时,StreamingFileSink 写入的文件才会由 Pending 状态变成 Finished 状态,从而能够安全地被下游读取。所以,我们一定要打开 Checkpointing,并设定合理的间隔。
93.Flink - Hive 实时写数据介绍下?
StreamingWrite,从 Kafka 中实时拿到数据,使用分区提交将数据从 Kafka 写入 Hive 表中,并运行批处理查询以读取该数据。
93.1 Flink-SQL 写法
- Source 源

- Sink 目的

- Insert 插入

93.2 Flink-Table 写法
- Source 源

- Sink 目的

- Insert 插入

94.Flink - Hive 实时读数据介绍下?

Flink 源码中在对 Hive 进行读取操作时,会经历以下几个步骤:
- Flink 都是基于 Calcite 先解析 SQL,确定表来源于 Hive,如果是 Hive 表,将会在 HiveCatalog 中创建 HiveTableFactory。
- HiveTableFactory 会基于配置文件创建 HiveTableSource,然后 HiveTableSource 在真正执行时,会调用
getDataStream方法,通过getDataStream方法来确定查询匹配的分区信息,然后创建表对应的 InputFormat,然后确定并行度,根据并行度确定slot分发 HiveMapredSplitReader 任务。 - 在 TaskManager 端的
slot中,Split 会确定读取的内容,基于 Hive 中定义的序列化工具,InputFormat 执行读取反序列化,得到value值。 - 最后循环执行
reader.next获取value,将其解析成 Row。
95.Flink - Hive 实时写数据时,如何保证已经写入分区的数据何时才能对下游可见呢?
如下图所示:

首先可以看一下,在实时的将数据存储到 Hive 数仓中,FileSystemConnector 为了与 Flink-Hive 集成的大环境适配,最大的改变就是分区提交,可以看一下左下图,官方文档给出的,分区可以采取 日期 + 小时 的策略,或者 时分秒 的策略。
那如何保证已经写入分区的数据何时才能对下游可见呢? 这就和 触发机制 有关, 触发机制包含 process-time 和 partition-time 以及时延。
partition-time 指的是根据事件时间中提取的分区触发。当 'watermark' > 'partition-time' + 'delay',选择 partition-time 的数据才能提交成功,
process-time 指根据系统处理时间触发,当加上时延后,要想让分区进行提交,当 'currentprocessing time' > 'partition creation time' + 'delay' 选择 process-time 的数据可以提交成功。文章来源:https://www.toymoban.com/news/detail-795044.html
但选择 process-time 触发机制会有缺陷,就是当数据迟到或者程序失败重启时,数据不能按照事件时间被归入正确分区。所以一般会选择 partition-time。文章来源地址https://www.toymoban.com/news/detail-795044.html
到了这里,关于【大数据】Flink 详解(八):SQL 篇 Ⅰ的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!