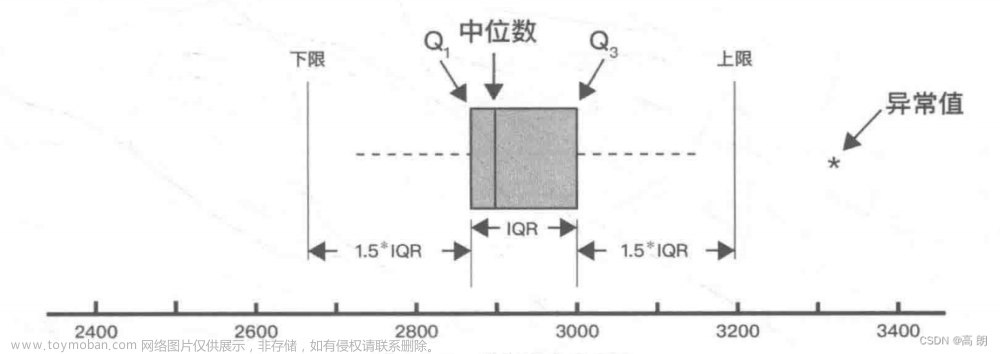
不平衡数据集指的是数据集各个类别的样本数目相差巨大,例如2000的人群中,某疾病的发生只有100 (5%)人,那么疾病发生与不发生为 1:19。这种情况下的数据称为不平衡数据。在真实世界中,不管是二分类或三分类,不平衡数据的现象普遍存在,尤其是罕见病领域。

image.png文章来源:https://www.toymoban.com/news/detail-795143.html
如果训练集的90%的样本是属于同一个类别,而我们的模型将所有的样本都分类为该类,在这种情况下,该分类器是无效的,尽管最后的分类准确度为90%。
所以在数据不均衡时,准确度(Accuracy)这个评价指标参考意义就不大了。实际上,如果不均衡比例超过4:1,分类器模型就会偏向于占比大的类别。
不平衡数据集的主要处理方法
这里我们主要介绍目前常用的方法。
- 对数据集进行重采样
- 评价指标选用召回率
接下来,我们将进行案例展示,随机产生5000份样本数据,预测变量为2分类。分别介绍不同的采样方法及最后评价指标。评估各种方法的优劣 。
数据
library(caret) # for model-building
library(DMwR) # for smote implementation
library(purrr) # for functional programming (map)
library(pROC) # for AUC calculations
set.seed(2969)
imbal_train = twoClassSim(3000,
intercept = -25,
linearVars = 20,
noiseVars = 10)
imbal_test = twoClassSim(2000,
intercept = -25,
linearVars = 20,
noiseVars = 10)
prop.table(table(imbal_train$Class))
head(imbal_train)
1.数据集进行重采样
接下来我们将使用相同的模型进行展示。下面的例子都使用随机森林模型。
1.1原始数据
首先我们不对Traning数据集进行任何的采样,使用10 x 5的重复交叉验证进行随机森林建模。然后在测试集中测量最终模型的性能。
# Set up control function for training
ctrl <- trainControl(method = "repeatedcv",
number = 10,
repeats = 5,
summaryFunction = twoClassSummary,
classProbs = TRUE)
# Build a standard classifier using a Random Forest
set.seed(42)
model_rf = train(Class ~ .,
data = imbal_train,
method = "rf",
metric = "ROC",
preProcess = c("scale", "center"),
trControl = ctrl)
## predict
confusionMatrix(predict(model_rf, imbal_test), imbal_test$Class)
1.2 Under-sampling
Caret包可以很容易地将采样技术与交叉验证重采样结合起来。我们可以通过缸盖trainControl中sampling参数,并选择"down"-向下采样(也称为向下采样)。其余部分与上述模型设置相同。
ctrl <- trainControl(method = "repeatedcv",
number = 10,
repeats = 5,
verboseIter = FALSE,
sampling = "down")
set.seed(42)
model_rf_under = train(Class ~ .,
data = imbal_train,
method = "rf",
preProcess = c("scale", "center"),
trControl = ctrl)
2.2 Oversampling
对于过度抽样(也称为向上抽样),我们只需更改sampling="up".
## Oversampling
ctrl <- trainControl(method = "repeatedcv",
number = 10,
repeats = 5,
verboseIter = FALSE,
sampling = "up")
set.seed(42)
model_rf_over = train(Class ~ .,
data = imbal_train,
method = "rf",
preProcess = c("scale", "center"),
trControl = ctrl)
2.3 ROSE
除了过采样和欠采样,还有一些混合方法将欠采样与额外数据的生成结合起来。其中最受欢迎的两个是ROSE和SMOTE。
From Nicola Lunardon, Giovanna Menardi and Nicola Torelli’s “ROSE: A Package for Binary Imbalanced Learning” (R Journal, 2014, Vol. 6 Issue 1, p. 79): “The ROSE package provides functions to deal with binary classification problems in the presence of imbalanced classes.
Artificial balanced samples are generated according to a smoothed bootstrap approach and allow for aiding both the phases of estimation and accuracy evaluation of a binary classifier in the presence of a rare class. Functions that implement more traditional remedies for the class imbalance and different metrics to evaluate accuracy are also provided. These are estimated by holdout, bootstrap, or cross-validation methods.”
ctrl <- trainControl(method = "repeatedcv",
number = 10,
repeats = 5,
verboseIter = FALSE,
sampling = "rose")
set.seed(42)
model_rf_rose <- train(Class ~ .,
data = imbal_train,
method = "rf",
preProcess = c("scale", "center"),
trControl = ctrl)
2.4 SMOTE
我们只需更改sampling="smote".
From Nitesh V. Chawla, Kevin W. Bowyer, Lawrence O. Hall and W. Philip Kegelmeyer’s “SMOTE: Synthetic Minority Over-sampling Technique” (Journal of Artificial Intelligence Research, 2002, Vol. 16, pp. 321–357): “This paper shows that a combination of our method of over-sampling the minority (abnormal) class and under-sampling the majority (normal) class can achieve better classifier performance (in ROC space) than only under-sampling the majority class. This paper also shows that a combination of our method of over-sampling the minority class and under-sampling the majority class can achieve better classifier performance (in ROC space) than varying the loss ratios in Ripper or class priors in Naive Bayes. Our method of over-sampling the minority class involves creating synthetic minority class examples.”
## SMOTE
ctrl <- trainControl(method = "repeatedcv",
number = 10,
repeats = 5,
verboseIter = FALSE,
sampling = "smote")
set.seed(42)
model_rf_smote <- train(Class ~ .,
data = imbal_train,
method = "rf",
preProcess = c("scale", "center"),
trControl = ctrl)
2.模型预测评价
在数据平衡的分类问题中,分类器好坏的评估指标常用准确率。数据不平衡的分类问题中,常用f1-score、ROC-AUC曲线见CSDN数据不平衡处理方法。
image.png
2.1 ROC曲线
# Build custom AUC function to extract AUC
# from the caret model object
test_roc <- function(model, data) {
roc(data$Class,
predict(model, data, type = "prob")[, "Class2"])
}
model_list_roc <- models %>%
map(test_roc, data = imbal_test)
model_list_roc %>%
map(auc)
$original
Area under the curve: 0.9523
$under
Area under the curve: 0.9686
$over
Area under the curve: 0.9797
$smote
Area under the curve: 0.9752
$rose
Area under the curve: 0.9832
## plot
results_list_roc <- list(NA)
num_mod <- 1
for(the_roc in model_list_roc){
results_list_roc[[num_mod]] <-
data_frame(tpr = the_roc$sensitivities,
fpr = 1 - the_roc$specificities,
model = names(models)[num_mod])
num_mod <- num_mod + 1
}
results_df_roc <- bind_rows(results_list_roc)
# Plot ROC curve for all 5 models
ggplot(aes(x = fpr, y = tpr, group = model), data = results_df_roc) +
geom_line(aes(color = model), size = 1) +
#scale_color_manual(values = custom_col) +
geom_abline(intercept = 0, slope = 1, color = "gray", size = 1) +
labs(
x = "False Positive Rate (1-Specificity)",
y = "True Positive Rate (Sensitivity)")+
theme_bw(base_size = 18)
通过上述结果可以看出,不采用重采样,AUC=0.9523;而rose采样方法的AUC最大,为0.983.但是AUC结果可能存在误差。
image.png
2.2 AUPRC曲线
在不平衡类的情况下使用AUC时也会产生误差,见 Issues with using ROC for imbalanced classes,谨慎选择AUC作为评价指标:对于数据极端不平衡时,可以观察观察不同算法在同一份数据下的训练结果的precision和recall,这样做有两个好处,一是可以了解不同算法对于数据的敏感程度,二是可以明确采取哪种评价指标更合适。针对机器学习中的数据不平衡问题,建议更多PR(Precision-Recall曲线),而非ROC曲线,如果采用ROC曲线来作为评价指标,很容易因为AUC值高而忽略实际对少两样本的效果其实并不理想的情况。Fawcett (2005). 。
Saito和Rehmsmeier(2015)建议在不平衡类别的情况下,检查准确率-召回率曲线,因为它比ROC曲线更能提供明确的信息。我们可以使用R中的PRROC包来计算5个模型的精确查全率曲线下的面积area under the precision-recall curve (AUPRC)。
#####
## Issues with using ROC for imbalanced classes
calc_auprc <- function(model, data){
index_class2 <- data$Class == "Class2"
index_class1 <- data$Class == "Class1"
predictions <- predict(model, data, type = "prob")
pr.curve(predictions$Class2[index_class2],
predictions$Class2[index_class1],
curve = TRUE)
}
# Get results for all 5 models
model_list_pr <- models %>%
map(calc_auprc, data = imbal_test)
model_list_pr %>%
map(function(the_mod) the_mod$auc.integral)
$original
[1] 0.6493153
$under
[1] 0.4875021
$over
[1] 0.5818407
$smote
[1] 0.5053534
$rose
[1] 0.7213629
## plot
# Plot the AUPRC curve for all 5 models
results_list_pr <- list(NA)
num_mod <- 1
for(the_pr in model_list_pr){
results_list_pr[[num_mod]] <-
data_frame(recall = the_pr$curve[, 1],
precision = the_pr$curve[, 2],
model = names(model_list_pr)[num_mod])
num_mod <- num_mod + 1
}
results_df_pr <- bind_rows(results_list_pr)
ggplot(aes(x = recall, y = precision, group = model),
data = results_df_pr) +
geom_line(aes(color = model), size = 1) +
geom_abline(intercept =
sum(imbal_test$Class == "Class2")/nrow(imbal_test),
slope = 0, color = "gray", size = 1) +
theme_bw()
我们看到rose采样提供了最好的精度和召回性能,这取决于所选择的阈值,而不采样的模型所在阈值上的性能实际上也达到了0.649。
image.png
例如,rose采样分类器同时具有75%的查全率和50%的查准率,F1得分为0.6,而原分类器(original)的查全率为75%,查准率为25%,F1得分为0.38。换句话说,当两个分类器都能预测结局,如果使用同一个阈值来分类,他们都正确地识别出了75%实际上属于少数群体的情况。 然而,rose采样分类器在这些预测中的效率更高,因为预测为少数群体类的观察结果中有50%实际属于少数群体类,而对于原始分类器,预测为少数群体类的观察结果中只有25%实际属于少数群体类。
2.3 所有模型评价指标
我们已经可以看到不同的抽样技术是如何影响模型性能的。Precision描述的是真实的阳性结果,即来自良性样本的良性预测的比例。F1是precision和sensitivity/ recall的加权平均值。
更多详细细节,请见 caret documentation
-
精度/特异性:有多少个选定的相关实例。
-
调用/灵敏度:选择了多少个相关实例。
-
F1得分:精度和召回的谐波平均值。
-
MCC:观察和预测的二进制分类之间的相关系数。
-
AUC:正确率与误报率之间的关系。
get parameters
comparison=tibble()
for (M in 1:length(models)) {
model <- confusionMatrix(predict(models[[M]], imbal_test), imbal_test C l a s s ) n a m e = n a m e s ( m o d e l s ) [ M ] x a = t i b b l e ( m o d e l n a m e = n a m e , S e n s i t i v i t y = m o d e l Class) name=names(models)[M] xa= tibble( modelname=name, Sensitivity = model Class)name=names(models)[M]xa=tibble(modelname=name,Sensitivity=modelbyClass[“Sensitivity”],
Specificity = model b y C l a s s [ " S p e c i f i c i t y " ] , P r e c i s i o n = m o d e l byClass["Specificity"], Precision = model byClass["Specificity"],Precision=modelbyClass[“Precision”],
Recall = model b y C l a s s [ " R e c a l l " ] , F 1 = m o d e l byClass["Recall"], F1 = model byClass["Recall"],F1=modelbyClass[“F1”])
print(name)
comparison=xa %>% bind_rows(comparison)
}plot all
comparison %>%
gather(x, y, Sensitivity:F1) %>%
ggplot(aes(x = x, y = y, color = modelname)) +
geom_jitter(width = 0.2, alpha = 0.5, size = 3)
image.png
在不平衡类的情况下,精确-召回曲线下的面积可以是一个有用的指标,帮助区分两个竞争的模型。对于AUC,加权和抽样技术可能只提供适度的改进。然而,这种改进通常会影响早期的检索性能,从而使模型的整体精度得到更大的提高。在尝试加权或抽样的同时,我们也建议在评估一个有不平衡类的分类器的性能时,不要只依赖AUC,因为它可能是一个误导性的指标。上面的代码显示了在有不平衡类的情况下,使用一个更敏感的分类性能指标(AUPRC)。文章来源地址https://www.toymoban.com/news/detail-795143.html
到了这里,关于机器学习Caret--R处理不平衡数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!