一、Upsert Kafka SQL 连接器
- Scan Source: Unbounded 、
- Sink: Streaming Upsert Mode
Upsert Kafka 连接器支持以 upsert 方式从 Kafka topic 中读取数据并将数据写入 Kafka topic。
作为 source,upsert-kafka 连接器生产 changelog 流,其中每条数据记录代表一个更新或删除事件。更准确地说,数据记录中的 value 被解释为同一 key 的最后一个 value 的 UPDATE,如果有这个 key(如果不存在相应的 key,则该更新被视为 INSERT)。用表来类比,changelog 流中的数据记录被解释为 UPSERT,也称为 INSERT/UPDATE,因为任何具有相同 key 的现有行都被覆盖。另外,value 为空的消息将会被视作为 DELETE 消息。
作为 sink,upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中。
二、依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.2-1.18</version>
</dependency>
三、完整示例
下面的示例展示了如何创建和使用 Upsert Kafka 表:
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = '...',
'key.format' = 'avro',
'value.format' = 'avro'
);
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP,
user_region STRING,
WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'pageviews',
'properties.bootstrap.servers' = '...',
'format' = 'json'
);
-- 计算 pv、uv 并插入到 upsert-kafka sink
INSERT INTO pageviews_per_region
SELECT
user_region,
COUNT(*),
COUNT(DISTINCT user_id)
FROM pageviews
GROUP BY user_region;
确保在 DDL 中定义主键。
这段代码是用来创建两个表,一个是"pageviews_per_region",另一个是"pageviews",并定义了它们的结构和连接器。
-
"pageviews_per_region"表包含了三个字段:user_region(用户所在地区,字符串类型)、pv(页面访问量,长整型)和uv(独立访客量,长整型)。该表的主键为user_region,但不强制执行。
-
"pageviews"表包含了四个字段:user_id(用户ID,长整型)、page_id(页面ID,长整型)、viewtime(访问时间,时间戳类型)和user_region(用户所在地区,字符串类型)。该表还定义了一个称为"viewtime"的水位线(watermark),它指定了在两秒之前的数据不再考虑为计算pv和uv。
这两个表都使用了Kafka连接器来读写数据。'connector’属性指定了使用的连接器类型,'topic’属性指定了连接器读写的Kafka主题,'properties.bootstrap.servers’属性指定了Kafka集群的地址。
对于"pageviews_per_region"表,'key.format’和’value.format’属性指定了数据的序列化格式为Avro。
对于"pageviews"表,'format’属性指定了数据的序列化格式为JSON。
最后,使用INSERT INTO语句,在"pageviews_per_region"表中计算出每个地区的pv和uv,并将结果插入到upsert-kafka sink中。
总之,这段代码的作用是通过Kafka连接器创建两个表,并将"pageviews"表中的数据计算出每个地区的pv和uv,并插入到"pageviews_per_region"表中。
四、可用元数据
连接器参数
| 参数 | 是否必选 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 必选 | (none) | String | 指定要使用的连接器,Upsert Kafka 连接器使用:‘upsert-kafka’。 |
| topic | 必选 | (none) | String | 用于读取和写入的 Kafka topic 名称。 |
| properties.bootstrap.servers | 必选 | (none) | String | 以逗号分隔的 Kafka brokers 列表。 |
| properties.* | 可选 | (none) | String | 该选项可以传递任意的 Kafka 参数。选项的后缀名必须匹配定义在 Kafka 参数文档中的参数名。 Flink 会自动移除 选项名中的 “properties.” 前缀,并将转换后的键名以及值传入 KafkaClient。 例如,你可以通过 ‘properties.allow.auto.create.topics’ = ‘false’ 来禁止自动创建 topic。 但是,某些选项,例如’key.deserializer’ 和 ‘value.deserializer’ 是不允许通过该方式传递参数,因为 Flink 会重写这些参数的值。 |
| key.format | 必选 | (none) | String | 用于对 Kafka 消息中 key 部分序列化和反序列化的格式。key 字段由 PRIMARY KEY 语法指定。支持的格式包括 ‘csv’、‘json’、‘avro’ |
| key.fields-prefix | 可选 | (none) | String | 为键格式的所有字段定义自定义前缀,以避免与值格式的字段发生名称冲突。默认情况下,前缀为空。如果定义了自定义前缀,则表架构和“key.fields”都将使用前缀名称。构造密钥格式的数据类型时,将删除前缀,并在密钥格式中使用无前缀的名称。请注意,此选项要求“value.fields-include”必须设置为“EXCEPT_KEY”。 |
| value.format | 必选 | (none) | String | 用于对 Kafka 消息中 value 部分序列化和反序列化的格式。支持的格式包括 ‘csv’、‘json’、‘avro’。 |
| value.fields-include | 必选 | ‘ALL’ | String | 控制哪些字段应该出现在 value 中。可取值:ALL:消息的 value 部分将包含 schema 中所有的字段,包括定义为主键的字段。EXCEPT_KEY:记录的 value 部分包含 schema 的所有字段,定义为主键的字段除外。 |
| sink.parallelism | 可选 | (none) | Integer | 定义 upsert-kafka sink 算子的并行度。默认情况下,由框架确定并行度,与上游链接算子的并行度保持一致。 |
| sink.buffer-flush.max-rows | 可选 | 0 | Integer | 缓存刷新前,最多能缓存多少条记录。当 sink 收到很多同 key 上的更新时,缓存将保留同 key 的最后一条记录,因此 sink 缓存能帮助减少发往 Kafka topic 的数据量,以及避免发送潜在的 tombstone 消息。 可以通过设置为 ‘0’ 来禁用它。默认,该选项是未开启的。注意,如果要开启 sink 缓存,需要同时设置 ‘sink.buffer-flush.max-rows’ 和 ‘sink.buffer-flush.interval’ 两个选项为大于零的值。 |
| sink.buffer-flush.interval | 可选 | 0 | Duration | 缓存刷新的间隔时间,超过该时间后异步线程将刷新缓存数据。当 sink 收到很多同 key 上的更新时,缓存将保留同 key 的最后一条记录,因此 sink 缓存能帮助减少发往 Kafka topic 的数据量,以及避免发送潜在的 tombstone 消息。 可以通过设置为 ‘0’ 来禁用它。默认,该选项是未开启的。注意,如果要开启 sink 缓存,需要同时设置 ‘sink.buffer-flush.max-rows’ 和 ‘sink.buffer-flush.interval’ 两个选项为大于零的值。 |
五、键和值格式
此连接器需要键和值格式,其中键字段源自 PRIMARY KEY 约束。
以下示例显示如何指定和配置键和值格式。格式选项以“键”或“值”加上格式标识符作为前缀。
CREATE TABLE KafkaTable (
`ts` TIMESTAMP(3) METADATA FROM 'timestamp',
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
PRIMARY KEY (`user_id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
...
'key.format' = 'json',
'key.json.ignore-parse-errors' = 'true',
'value.format' = 'json',
'value.json.fail-on-missing-field' = 'false',
'value.fields-include' = 'EXCEPT_KEY'
)
六、主键约束
Upsert Kafka 始终以 upsert 方式工作,并且需要在 DDL 中定义主键。在具有相同主键值的消息按序存储在同一个分区的前提下,在 changelog source 定义主键意味着 在物化后的 changelog 上主键具有唯一性。定义的主键将决定哪些字段出现在 Kafka 消息的 key 中。
七、一致性保证
默认情况下,如果启用 checkpoint,Upsert Kafka sink 会保证至少一次将数据插入 Kafka topic。
这意味着,Flink 可以将具有相同 key 的重复记录写入 Kafka topic。但由于该连接器以 upsert 的模式工作,该连接器作为 source 读入时,可以确保具有相同主键值下仅最后一条消息会生效。因此,upsert-kafka 连接器可以像 HBase sink 一样实现幂等写入。
八、为每个分区生成相应的watermark
Flink 支持根据 Upsert Kafka 的 每个分区的数据特性发送相应的 watermark。当使用这个特性的时候,watermark 是在 Kafka consumer 内部生成的。 合并每个分区 生成的 watermark 的方式和 stream shuffle 的方式是一致的。 数据源产生的 watermark 是取决于该 consumer 负责的所有分区中当前最小的 watermark。如果该 consumer 负责的部分分区是 idle 的,那么整体的 watermark 并不会前进。在这种情况下,可以通过设置合适的 table.exec.source.idle-timeout 来缓解这个问题。文章来源:https://www.toymoban.com/news/detail-795252.html
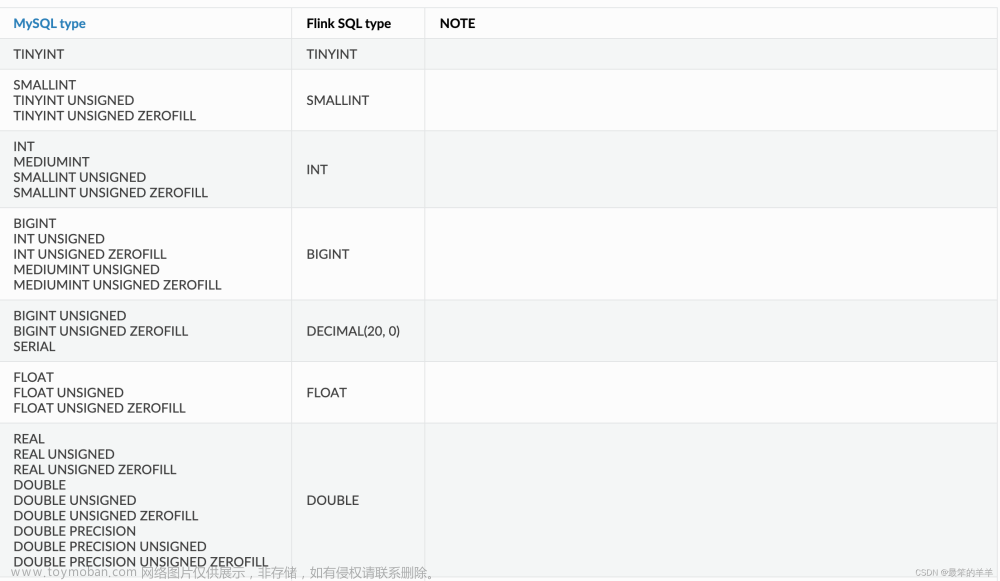
九、数据类型映射
Upsert Kafka 用字节存储消息的 key 和 value,因此没有 schema 或数据类型。消息按格式进行序列化和反序列化,例如:csv、json、avro。因此数据类型映射表由指定的格式确定。文章来源地址https://www.toymoban.com/news/detail-795252.html
到了这里,关于Flink系列之:Upsert Kafka SQL 连接器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!