一、问题描述
用Pandas读取csv文件,read_csv(),使用默认的 encoding = ‘utf-8’ 和 encoding = ‘gbk’ 都报错,如下图。最终通过统一编码方式解决了,操作很简单,但是问题解决的探索过程并不是特别顺利,所以记录一下,给朋友们参考~

二、问题解决
统一编码方式,将csv文件的编码格式改为utf-8。
具体操作:用记事本打开csv文件,可以看到右下角显示的编码方式为ANSI,另存为文件,编码选择UTF-8。

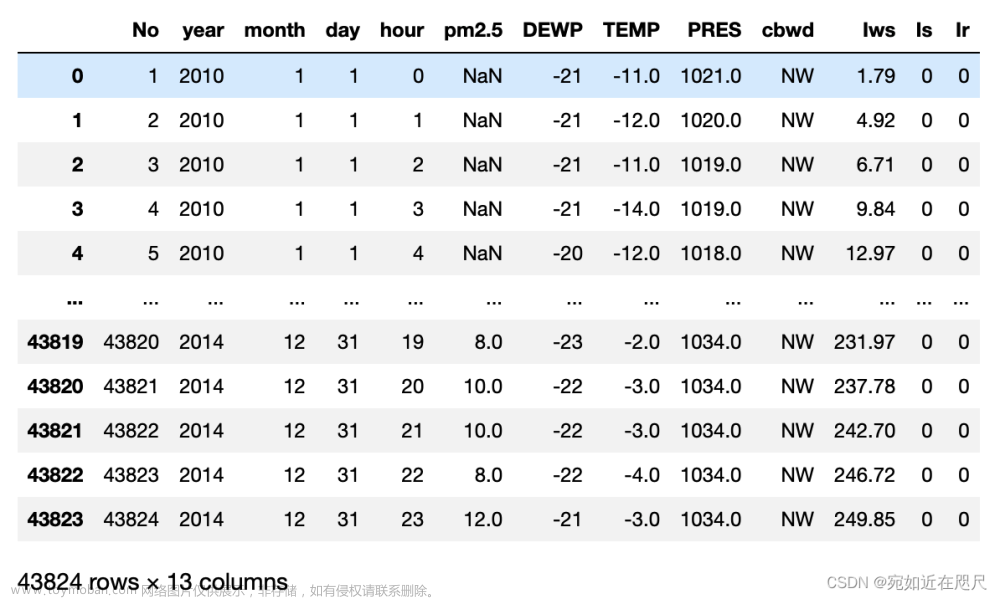
成功读取文件: 文章来源:https://www.toymoban.com/news/detail-795337.html
文章来源:https://www.toymoban.com/news/detail-795337.html
三、解决过程及分析总结
- 一开始是通过修改默认编码方式为encoding = ‘gbk’ ,发现文件内容的是混合了两种编码方式。
- 尝试通过网页搜索相关的问题经验贴,有相关的,但也并不能解决我的问题。
- 借助文心一言,AI可以直接提供代码,尝试了几种途径都没有成功,包括:使用chardet库来检测文件的编码、将Pandas库中的read_csv()参数chunksize设置为1逐行读取、使用csv模块和codecs模块来逐行读取CSV文件并条件判断使用编码方式为UTF-8或GBK。
- 转变思路,直接将csv文件统一好格式,再读取文件。记事本一键另存为,后面非常顺利地用pd.read_csv()读取成功。
总结:文章来源地址https://www.toymoban.com/news/detail-795337.html
- 遇到问题不要慌,虽然有时候尝试好几次报错就会很烦。
- 借助大模型是个好办法,代码不一定能顺利运行,但可以给你提供一些思路,比如可以用哪些库和函数,而且发现AI写的代码,编程思维还是体现得很不错的,尤其是函数的设计。
- 学会转换思路(放松大脑),尝试用尽可能简单的办法解决问题,比如这个问题可以记事本直接另存为,统一文件编码方式。
到了这里,关于python,Pandas读取csv文件gbk编码和utf-8编码都报错的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!