目录
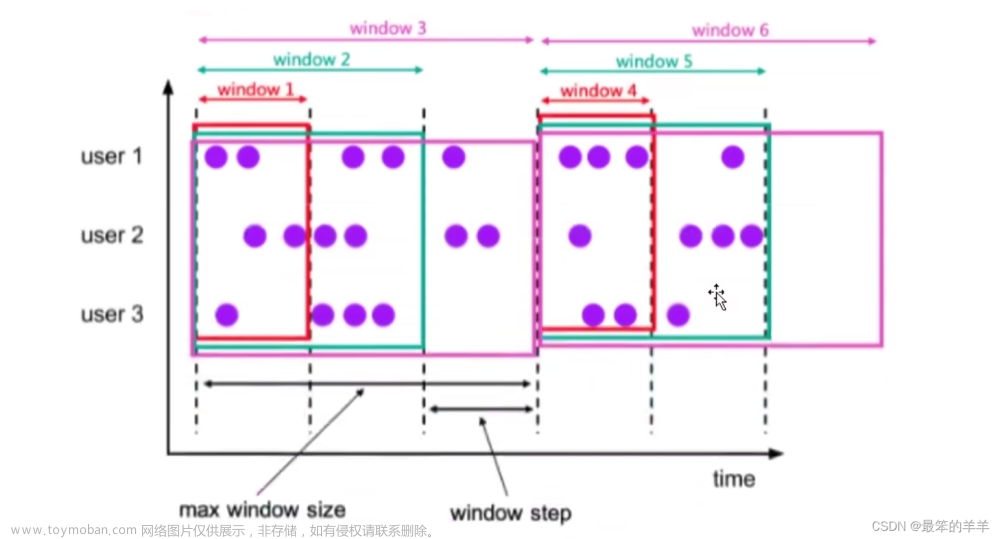
窗口分配器
时间窗口
计数窗口
全局窗口
窗口函数
增量聚合函数
全窗口函数(full window functions)
增量聚合和全窗口函数的结合使用
Window API 主要由两部分构成:窗口分配器(Window Assigners)和窗口函数(Window Functions)
stream.keyBy(<key selector>)
.window(<window assigner>) //指明窗口的类型
.aggregate(<window function>) //定义窗口具体的处理逻辑在window()方法中传入一个窗口分配器;
在aggregate()方法中传入一个窗口函数;
窗口分配器
指定窗口的类型,定义数据应该被“分配”到哪个窗口
方法:.window()
参数:WindowAssigner
返回值:WindowedStream
如果是非按键分区窗口,那么直接调用.windowAll()方法,同样传入一个WindowAssigner,返回的是 AllWindowedStream
时间窗口
滚动处理时间窗口
stream.keyBy(...)
//1..of()方法需要传入一个 Time 类型的参数 size,表示滚动窗口的大小
.window(TumblingProcessingTimeWindows.of(Time.seconds(5))) //窗口大小
//2.通过设置偏移量offset 来调整起始点的时间戳
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))) //窗口大小,偏移量
.aggregate(...)默认的窗口起始点时间戳是窗口大小的整倍数
如果我们定义 1 天的窗口,默认就从 0 点开始;如果定义 1 小时的窗口,默认就从整点开始
如果不想用默认值,就需要设置好偏移量
偏移量的作用:标准时间戳其实就是1970 年 1 月 1 日 0 时 0 分 0 秒 0 毫秒开始计算的一个毫秒数,而这个时间是以 UTC 时间,也就是 0 时区(伦敦时间)为标准的。我们所在的时区是东八区,也就是 UTC+8,跟 UTC 有 8小时的时差。我们定义 1 天滚动窗口时,如果用默认的起始点,那么得到就是伦敦时间每天 0点开启窗口,这时是北京时间早上 8 点。那怎样得到北京时间每天 0 点开启的滚动窗口呢?只要设置-8 小时的偏移量就可以了
滑动处理时间窗口
stream.keyBy(...)
//窗口大小,滑动步长(同样也可以设置偏移量)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)处理时间会话窗口
stream.keyBy(...)
//超时时间
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)以上是静态设置了超时时间,也可以动态设置:
.window(ProcessingTimeSessionWindows.withDynamicGap(newSessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) {
// 提取 session gap 值返回, 单位毫秒
//提取了数据元素的第一个字段,用它的长度乘以 1000 作为会话超时的间隔
return element.f0.length() * 1000;
}
}滚动事件时间窗口
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)滑动事件时间窗口
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)事件时间会话窗口
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)处理时间和事件时间的逻辑完全相同
计数窗口
滚动计数窗口:.countWindow(10) //窗口大小
滑动计数窗口:.countWindow(10,3) //窗口大小,滑动步长
每个窗口统计 10 个数据,每隔 3 个数据就统计输出一次结果
全局窗口
.window(GlobalWindows.create());
需要自定义触发器
窗口函数
WindowedStream——>DataStream
增量聚合函数
像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以
区别在于不立即输出结果,而是要等到窗口结束时间
归约函数(ReduceFunction):和简单聚合时使用的ReduceFunction完全一样
聚合函数(AggregateFunction):取消类型一致的限制,直接基于 WindowedStream 调 用.aggregate()方法,不需要经过map处理;这个方法需要传入一个AggregateFunction 的实现类作为参数,源码如下:
@PublicEvolving
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {
/**
* Creates a new accumulator, starting a new aggregate.
*
* <p>The new accumulator is typically meaningless unless a value is added via {@link
* #add(Object, Object)}.
*
* <p>The accumulator is the state of a running aggregation. When a program has multiple
* aggregates in progress (such as per key and window), the state (per key and window) is the
* size of the accumulator.
*
* @return A new accumulator, corresponding to an empty aggregate.
*/
ACC createAccumulator();
/**
* Adds the given input value to the given accumulator, returning the new accumulator value.
*
* <p>For efficiency, the input accumulator may be modified and returned.
*
* @param value The value to add
* @param accumulator The accumulator to add the value to
* @return The accumulator with the updated state
*/
ACC add(IN value, ACC accumulator);
/**
* Gets the result of the aggregation from the accumulator.
*
* @param accumulator The accumulator of the aggregation
* @return The final aggregation result.
*/
OUT getResult(ACC accumulator);
/**
* Merges two accumulators, returning an accumulator with the merged state.
*
* <p>This function may reuse any of the given accumulators as the target for the merge and
* return that. The assumption is that the given accumulators will not be used any more after
* having been passed to this function.
*
* @param a An accumulator to merge
* @param b Another accumulator to merge
* @return The accumulator with the merged state
*/
ACC merge(ACC a, ACC b);
}IN:输入数据类型
ACC:累加器类型
OUT:输出数据类型
AggregateFunction 接口中有四个方法:

除了继承AggregateFunction,自定义聚合函数之外,Flink为我们提供了一系列预定义的简单聚合方法,如sum()/max()/maxBy()/min()/minBy(),可以直接基于WindowedStream调用
全窗口函数(full window functions)
全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算
典型的批处理方式,适用于一些基于全部数据才能进行的运算等等
窗口函数(WindowFunction)
stream
.keyBy(<key selector>)
.window(<window assigner>)
//基于 WindowedStream 调用.apply()方法,传入一个 WindowFunction 的实现类
.apply(new MyWindowFunction());WindowFunction的实现类中可以获取到包含窗口所有数据的可迭代集合(Iterable),还可以拿到窗口本身的信息
功能可以被 ProcessWindowFunction(处理窗口函数,见下) 全覆盖
处理窗口函数(ProcessWindowFunction)
增强版的 WindowFunction
基于 WindowedStream 调用.process()方法,传入一个 ProcessWindowFunction 的实现类
ProcessWindowFunction的泛型:
ProcessWindowFunction<IN,OUT,KEY,W>分别是输入数据类型,输出数据类型,分区键的类型,Window类型(比如,是时间窗口,就是TimeWindow)
process()方法的定义:

示例代码如下,自定义窗口处理函数来处理数据:
public class UvCountByWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 将数据全部发往同一分区,按窗口统计UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
//自定义窗口处理函数
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow>{
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
HashSet<String> userSet = new HashSet<>();
// 遍历所有数据,放到Set里去重
for (Event event: elements){
userSet.add(event.user);
}
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect("窗口: " + new Timestamp(start) + " ~ " + new Timestamp(end)
+ " 的独立访客数量是:" + userSet.size());
}
}
}这里的Event是一个POJO类,ClickSource是自定义的数据源,其代码如下:
Event.java:
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}ClickSource.java:
public class ClickSource implements SourceFunction<Event> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<Event> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
while (running) {
ctx.collect(new Event(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar.getInstance().getTimeInMillis()
));
// 隔1秒生成一个点击事件,方便观测
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}
增量聚合和全窗口函数的结合使用
增量聚合函数处理计算会更高效;而全窗口函数的优势在于提供了更多的信息
我们之前在调用 WindowedStream 的.reduce()和.aggregate()方法时,只是简单地直接传入了一个 ReduceFunction 或 AggregateFunction 进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是 WindowFunction 或者 ProcessWindowFunction
处理机制:
基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了 Iterable 类型的输入。一般情况下,这时的可迭代集合中就只有一个元素了文章来源:https://www.toymoban.com/news/detail-795471.html
学习课程链接:【尚硅谷】Flink1.13实战教程(涵盖所有flink-Java知识点)_哔哩哔哩_bilibili 文章来源地址https://www.toymoban.com/news/detail-795471.html
到了这里,关于Flink窗口(2)—— Window API的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!