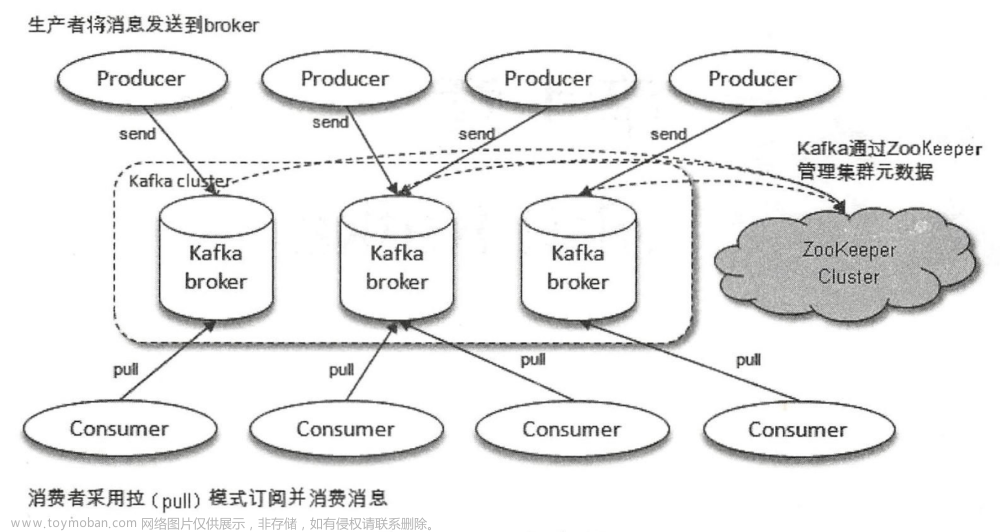
Zookeeper 架构理解
整体架构

- Follower server 可以直接处理读请求,但不能直接处理写请求。写请求只能转发给 leader server 进行处理。
- 最终所有的写请求在 leader server 端串行执行。(因为分布式环境下永远无法精确地确认不同服务器不同事件发生的先后顺序)
- ZooKeeper 集群中的所有节点的数据状态通过 ZAB 协议保持一致。ZAB 有两种工作模式:
(1)崩溃恢复:集群没有 Leader 角色,内部在执行选举。
(2)原子广播:集群有 Leader 角色,Leader 主导分布式事务的执行,向所有的 Follower 节点,按照严格顺序广播事务。
(3)补充一点:实际上,ZAB 有四种工作模式,分别是:ELECTION,DISCOVERY,SYNCHRONIZATION,BROADCAST。
Zookeeper 节点服务组件

Zookeeper 到底是 cp 还是 ap ?
- 严格意义上讲,ZooKeeper 实现了 P 分区容错性、C 中的写入强一致性,丧失的是 C 中的读取一致性。ZooKeeper 并不保证读取的是最新数据。
- 如果客户端刚好链接到一个刚好没执行事务成功的节点,也就是说没和 Leader 保持一致的 Follower 节点的话,是有可能读取到非最新数据的。
- 如果要保证读取到最新数据,请使用 sync 回调处理。这个机制的原理:是先让 Follower 保持和 Leader 一致,然后再返回结果给客户端。
- 关于 zookeeper 到底是 CP 还是 AP 的讨论,zk 的 ap 和 cp 是从不同的角度分析的:
(1)从一个读写请求分析,保证了可用性(不用阻塞等待全部 follwer 同步完成),保证不了数据的一致性,所以是ap。
(2)但是从zk架构分析,zk在leader选举期间,会暂停对外提供服务(为啥会暂停,因为zk依赖leader来保证数据一致性),所以丢失了可用性,保证了一致性,即cp。 再细点话,这个 c 不是强一致性,而是最终一致性。即上面的写案例,数据最终会同步到一致,只是时间问题。
(3)综上,zk 广义上来说是 cp,狭义上是 ap。
ZNode 数据模型
概述
ZooKeeper 的数据模型系统是一个类文件系统结构,每个节点称之为 ZNode,具体代码实现类是 DataNode。既不是文件夹,也不是文件,但是既具有文件夹的能力,也具有文件的能力。
ZNode 分类
3.4.x 及以下版本,ZNode 分为按照 临时/ 持久、 带序列编号/ 不带序列编号 分为 4 种:
- CreateMode.PERSISTENT 持久
- CreateMode.PERSISTENT_SEQUENTIAL 持久带序列编号
- CreateMode.EPHEMERAL 临时
- CreateMode.EPHEMERAL_SEQUENTIAL 临时带序列编号
临时节点的下面不能挂载子节点。临时节点,只能作为叶子节点,其生命周期和会话绑定。
3.5.x 及以上版本,加入以下三种: - CONTAINER:容器节点,其最后一个子对象被删除时,该容器将在一段时间后删除。
- PERSISTENT_WITH_TTL:zookeeper的扩展类型,如果znode在给定的TTL内没有被修改,它将在没有子节点时被删除。
- PERSISTENT_SEQUENTIAL_WITH_TTL:同上,是不过是带序号的。
Zookeeper 不适合写入大量数据的原因
- 因为 ZooKeeper 系统内部每个节点都会做数据同步,在执行写请求的时候,事实上就是原子广播。待写入数据越大,原子广播的效率就越低,成功难度也越大。
- 所有的请求,都是严格的顺序串行执行, 这个 ZooKeeper 集群在某一个时刻只能执行一个事务,如果上一个事务执行耗时,则会阻塞后面的请求的执行。
- 正因为每个节点都会存储一份完整的 ZooKeeper 系统数据,所以如果系统数据过大,甚至超过了单个 Follower 的存储能力了,系统服务大受影响甚至崩溃。
- ZooKeeper 的设计初衷,就不是为了给用户提供一个大规模数据存储服务,而是提供了一个为了解决一些分布式问题而需要进行一些状态存储的数据模型系统。
Watcher 监听机制

注册监听的三种方式
zk.getData(znodePath, watcher); // 关注节点的数据变化
zk.exists(znodePath, watcher); // 关注节点的存在与否的状态变化
zk.getChildren(znodePath, watcher); // 关注节点的子节点个数变化
触发监听的三种方式
zk.setData(); // 更改节点数据,触发监听
zk.create(); // 创建节点
zk.delete(); // 删除节点
四种事件类型
NodeCreated // 节点被创建
NodeDeleted // 节点被删除
NodeDataChanged // 节点数据发生改变
NodeChildrenChanged // 节点的子节点个数发生改变

Zookeeper 应用场景
Zookeeper 作为分布式协调服务,最常见应用场景是分布式锁和集群管理。例如 HDFS NameNode 高可用模式,YARN ResourceManager 高可用模式,HBase RegionServer 的管理与元数据存储,Flink 主节点组件 ResourceManager、JobManager、Dispatcher 的高可用模式等等。
分布式锁

集群管理

Zookeeper 源码剖析
Zookeeper 基础组件详解
Zookeeper 序列化机制
序列化的 API 主要在 zookeeper-jute 子项目中。
class ZNode implements Record{
int id;
String name;
// 反序列化
void deserialize(InputArchive archive, String tag){
archive.readBytes();
archive.readInt();
}
// 序列化
void serialize(OutputArchive archive, String tag)
}
Zookeeper 持久化机制
简介
1、数据模型:DataTree + DataNode
2、持久化机制:FileTxnSnalLog = TxnLog + SnapLog
3、zk数据库:ZKDataBase = DataTree + FileTxnSnapLog
补充1:
1、每个节点上都保存了整个系统的所有数据 ( leader 存储了数据,所有的 follower 节点都是 leader 的副本节点)。
2、每个节点上的都把数据放在磁盘一份,放在内存一份。
补充2:
1、DataNode znode 系统中的一个节点的抽象。
2、DataTree znode 系统的完整抽象。
3、ZKDataBase 负责管理 DataTree,处理最基本的增删改查的动作,执行 DataTree 的相关快照和恢复的操作。
API 介绍
第一组:主要是用来操作日志的(如果客户端往 ZooKeeper 中写入一条数据,则记录一条日志)
TxnLog,接口,读取事务性日志的接口
FileTxnLog,实现 TxnLog 接口,添加了访问该事务性日志的 API
第二组:拍摄快照(当内存数据持久化到磁盘)
Snapshot,接口类型,持久层快照接口
FileSnap,实现 Snapshot 接口,负责存储、序列化、反序列化、访问快照
第三组;两个成员变量:TxnLog 和 SnapShot
FileTxnSnapLog,封装了 TxnLog 和 SnapShot
第四组:工具类
Util,工具类,提供持久化所需的API
伪代码 Demo
class ZKDataBase{
protected DataTree dataTree;
protected FileTxnSnapLog snapLog;
}
class DataTree{
//根节点
private static final String rootZookeeper = "/";
// 所有节点的 路径 和 节点抽象的 映射
private final NodeHashMap nodes = new NodeHashMapImpl(digestCalculator){
private final ConcurrentHashMap<String, DataNode> nodes;
}
}
public class DataNode implements Record {
byte[] data;
private Set<String> children = null;
}
class FileTxnSnapLog{
TxnLog txnLog;
SnapShot snapLog;
}
// 实现类:
interface TxnLog{
void rollLog() throws IOException;
boolean append(TxnHeader hdr, Record r) throws IOException;
boolean truncate(long zxid) throws IOException;
void commit() throws IOException;
}
// 实现类:
interface SnapShot{
long deserialize(DataTree dt, Map<Long, Integer> sessions) throws IOException;
void serialize(DataTree dt, Map<Long, Integer> sessions, File name, boolean fsync) throws IOException;
}
Zookeeper 网络通信机制

建立连接时,只允许服务器ID较大者去连服务器ID较小者,小ID服务器去连大ID服务器会被拒绝。
ZooKeeper 源码阅读大纲
Zookeeper 节点类型

ZooKeeper 服务节点启动
1、集群启动脚本:zkServer.sh start
2、集群启动的启动类的代码执行:QuorumPeerMain.main()
3、冷启动数据恢复,从磁盘恢复数据到内存:zkDatabase.loadDatabase()
4、选举:startLeaderElection() + QuorumPeer.lookForLeader()
5、同步:follower.followLeader() + observer.observerLeader()
QuorumPeerMain 结构简图

ZooKeeper QuorumPeerMain 启动
启动过程概览
入口:QuorumPeerMain 的 main 方法
- 解析配置
- 读取 zoo.cfg 得到 Properties 对象,解析这个对象,得到各种配置,设置到 QuorumPeerConfig
- 解析 server. 开头的各项配置,获取 allMembers, votingMembers, observerMembers 集合,然后构建 QruoumMaj 实例
- 解析 myid
- 启动删除旧快照文件的定时任务
- 启动 QuorumPeer
- 创建 NIO 服务端相关组件和线程
- 创建 QuorumPeer 实例,然后把 QuorumPeerConfig 中的各种配置,设置到 QuorumPeer
- 调用 start 方法启动
- 冷启动数据恢复
- 启动 NIO 服务端
- 启动 AdminServer
- startLeaderElection 为选举做准备
- 启动 JVM 监视器
- 启动 QuorumPeer 线程进入 ZAB 工作模式
- QuorumPeer.run()
- quorumPeers 变量被一分为三,存储在 QuorumMaj 的内部(allMembers, votingMembers, observingMembers)
loadDataBase
// 入口方法
QuorumPeer.loadDataBase(){
zkDb.loadDataBase(){
// 冷启动的时候,从磁盘恢复数据到内存
snapLog.restore(dataTree,...){
// 第一件事:从快照恢复
snapLog.deserialize(dt, sessions){
deserialize(dt, sessions, ia){
SerializeUtils.deserializeSnapshot(dt, ia, sessions){
dt.deserialize(ia, "tree");
}
}
}
// 第二件事:从操作日志恢复
fastForwardFromEdits(dt, sessions, listener){
while(true) {
// 恢复执行一条事务
processTransaction(hdr, dt, sessions, itr.getTxn()){
// 恢复执行一条事务
dt.processTxn(hdr, txn){
// 创建一个znode
createNode 或者 deleteNode
}
}
}
}
}
}
}
ZooKeeper 选举算法 FastLeaderElection 实例化(难点)
背景知识
(1)所有的节点(有选举权和被选举权),一上线,就是 LOOKING 状态,当选举结束了之后,有选举权中的角色会变量另外两种:Leader, Follower,相应的状态变为 LEADING、FOLLOWING。
(2)需要发送选票,选票是 Vote 对象,广播到所有节点。事实上,关于选票和投票的类型有四种:
Vote 选票
Notificatioin 接收到的投票
Message 放入投票队列的选票
ToSend 待发送的选票
还有一个特殊的中间对象:ByteBuffer —— NIO 的一个 API
(3)当每个 zookeeper 服务器启动好了之后,第一件事就是发起投票,如果是第一次发起投票都是去找 leader,如果发现有其他 zookeeper 返回给我 leader 的信息,那么选举结束。
(4)在进行选票发送的时候,每个 zookeeper 都会为其他的 zookeeper 服务节点生成一个对应的 SendWorker 和一个 ArrayBlockingQueue,ArrayBlockingQueue 存放待发送的选票,SendWorker 从队列中,获取选票执行发送。还有一个线程叫做: ReceiveWorker 真正完整从其他节点接收发送过来的投票。
整个图总结一下,分成两个部分:
创建 QuorumCnxManager
创建了 recvQueue 队列
创建了 queueSendMap
创建了 senderWorkerMap
创建了 Listener 线程
创建 FastLeaderElection
创建了 sendqueue 队列
创建了 recvqueue 队列
创建了 WorkerSender 线程
创建了 WorkerReceiver 线程
终于启动了选举:入口方法 FastLeaderElection.lookForLeader();
选票交换
选举客户端入口方法:FastLeaderElection.lookForLeader() 中会调用 QuorumCnxManager 的 connectAll 方法,进而对每个节点调用 connectOne 方法。
选举服务端入口方法:QuorumCnxManager 内部类 ListenerHandler 的 ServerSocket.accept() 方法处理连接请求,校验 sid 是否满足大于本节点 sid,满足则创建对应的 SendWorker、RecvWorker、CircularBlockingQueue 用于发送和接受选票。
lookForLeader() 执行选举
QuorumPeer.run(){
while(true){
switch(getPeerState()) {
case LOOKING:
// 选举入口 makeLEStrategy() = FastLeaderElection
// 默认每间隔 2 秒 (tickTime) 执行一轮投票
setCurrentVote(makeLEStrategy().lookForLeader());
break;
case OBSERVING:
// 选举结束,observer 跟 leader 进行状态同步
setObserver(makeObserver(logFactory));
observer.observeLeader();
break;
case FOLLOWING:
// 选举结束,没有成为 leader 的服务器成为 follower,保持和 leader 的同步
setFollower(makeFollower(logFactory));
follower.followLeader();
break;
case LEADING:
// 选举结束,其中一个 participant 成为 leader,进入领导状态
setLeader(makeLeader(logFactory));
leader.lead();
break;
}
}
}
ZooKeeper 消息同步
ZAB 的四种工作状态
ELECTION:开始选举,当前 Server 进入找 Leader 状态:Vote currentVote = lookForLeader()
DISCOVERY:当选举得出了结果,开始进入发现认同阶段,当超过半数 Follower 认同该 Leader,意味着选举真正结束
SYNCHRONIZATION:经过确认,有超过半数节点都追随了刚推举出来的 Leader 节点
BROADCAST:当有超过半数的 Follower 完成了和 Leader 的状态同步之后进入消息广播状态,正常对外提供服务
ZooKeeper 的 Follower 和 Leader 的状态同步图解

右图详细架构如下:
关于同步过程中的两种方式
(1)快照同步:Leader 直接把最新的快照文件(这个快照文件必然包含了 Leader 的所有数据)直接通过网络发送给 Follower。
(2)差异化同步:在确认同步方式的时候,如果得到的结果不是快照同步,则同时把要同步的数据,变成(Proposal + Commit 消息放到 队列中),队列中的数据的形态:
DIFF + Proposal + Commit + Proposal + Commit + Proposal + Commit + Proposal + Commit + NEWLEADER
当 Follower 接收到 NEWLEADER 消息的时候,意味着 Follower 已经接收到了需要同步的所有数据。
标准的 10 步骤详细介绍
(1)Follower 发送 FOLLOWERINFO 消息给 Leader,信息中包含 Follower 的 AcceptedEpoch。
(2)Leader 在接收到 Follower 的 FOLLOWERINFO 消息的时候,返回一个 LEADERINFO 消息给 Follower,信息中包含 Leader 的 AcceptedEpoch。
(3)Follower 给 Leader 返回一个 ACKEPOCH 消息,表示已经接收到 Leader 的 AcceptedEpoch 了。Leader 需要等待有超过半数的 Follower 发送回 ACKEPOCH 消息;有超过半数节点在追随相同的 Leader 节点,则选举结束,开始进入同步阶段。
(4)Leader 根据 Follower 发送过来的 epoch 信息给 Follower 计算同步方式,同步方式有可能是 DIFF, SNAP, TRUNC 的其中之一。计算得到的同步方式消息放入到 LearnerHandler 的 queuedPackets 队列中,跟后面计算出来的待同步的分布式事务日志一起执行发送。同步方式的计算逻辑位于 LearnerHandler 的 syncFollower 方法中。
(5)如果同步方式是 DIFF,则获取到需要同步的分布式事务的 PROPOSAL 和 COMMIT 日志,也放入 LearnerHandler 的 queuedPackets 队列中,如果
同步方式是 SNAP,则先写入一个 SNAP 消息给 Follower,然后把快照文件发送过 Follower 进行快照同步
(6)通过 startSendingPackets() 方法启动一个匿名线程执行 LearnerHandler 的 queuedPackets 队列中的数据包发送。
(7)当该同步的数据(queuedPackets 队列中的 PROPOSAL 和 COMMIT 日志,或者 SNAP 方式的快照文件)都发送完毕之后,Leader 给 Follower 发送一个 NEWLEADER 消息表示所有待同步数据已经发送完毕。
(8)Follower 在接收到 Leader 发送过来的 NEWLEADER 消息,就必然得知,要和 Leader 进行同步的日志数据,都已经发送过来了,自己也都执行成功了,则可以给 Leader 发送过一个 ACK 反馈
(9)Leader 需要等待集群中,有超过半数的节点发送 ACK 反馈过来,如此,集群启动成功,Leader 给发送过了 ACK 的 Follower Server 发送一个 UPTODATE 的消息表示集群已经启动成功。Leader 和 Follower 都启动各自的一些必备基础服务可以开始对外提供服务了。
(10)Follower 接收到 Leader 的 UPTODATE 消息,即表示集群启动正常,Follower 可以正常对外提供服务,Follower 再给 Leader 返回一个 ACK。
注意 3 个细节
(1)Leader 和 Follower 之间是有心跳的。如果维持心跳的节点数不超过集群半数节点了,则集群不能正常对外提供服务了。全部进入 LOOKING 状态。
(2)Leader 通过 syncFollower() 方法来计算和 Follower 的同步方式。关于什么情况分析得到什么同步方式的细节需要了解清楚。
(3)Leader 和 Follower 在集群正常启动成功之后,需要启动一些基础服务,比如 SessionTracker 和 RequestProcessor 等。
Follower 的状态同步源码实现
大体分为三个大部分:
- 进入 DISCOVERY 状态,确认 Leader 并且建立和 Leader 的链接。
- 进入 SYNCHRONIZATION 状态,执行和 Leader 的状态同步。
- 进入 BROADCAST 状态,不停的接收 Leader 广播过来的 Proposal 执行。
Follower 的状态同步源码实现
基本上分为四个大步骤:
- Leader 进入 DISCOVERY 状态,首先加载数据,获取 Leader 的一些基本信息,并且拍摄一次快照。
- Leader 创建 LearnerCnxAcceptor,内部创建 BIO 服务端,用来接受 Follower 的链接请求用来执行同步。
(1)首先接收 Follower 的 ACKEPOCH 消息,如果接收超过集群半数,则 Leader 确认然后进入同步状态,等待有超过半数节点完成和 Leader 的状态同步
(2)Leader 在完成超过半数 Follower 节点的同步的时候,就开始启动 Leader 的一些基础服务了,也说明 ZooKeeper 集群完成正常启动成功了
(3)Leader 进入 BROADCAST 状态,QuorumPeer 线程维护和 Follower 的心跳(在 Leader 的 lead 方法最后),LearnerHandler 线程对对应的 Follower 提供服务。
ZooKeeper 服务启动
Leader 中的 ZooKeeperServer 启动
在 Leader 的 lead() 方法的最后,也就是 Leader 完成了和集群过半 Follower 的同步之后,就会调用 startZkServer() 来启动必要的服务,主要包括:
- SessionTracker
- RequestProcessor
- 更新 Leader ZooKeeperServer 的状态
Leader.lead(){
startZkServer(){
zk.startup(){
// ZooKeeperServer 启动
super.startup(){
startupWithServerState(State.RUNNING);
}
// ZK Container ZNode 定时清除任务
if(containerManager != null) {
containerManager.start();
}
}
}
}
注:Leader 中聚合了 ZooKeeperServer 的子类 LeaderZooKeeperServer。ZooKeeperServer 内部枚举类 State 共有 4 个实例:INITIAL, RUNNING, SHUTDOWN, ERROR。
Follow 中的 ZooKeeperServer 启动
Follower 也是一样的。在完成了和 Leader 的状态同步之后,也就是接收到 Leader 发送过来的 NEWLEADER 消息的时候,就会首先拍摄快照,然后调用 zk.startupWithoutServing() 来启动 Follower 必要的一些基础服务,包括:
- SessionTracker
- RequestProcessor
- 更新 Leader ZooKeeperServer 的状态
Learner.syncWithLeader(long newLeaderZxid){
// 创建 SessionTracker
zk.createSessionTracker();
// 启动一些各种服务
zk.startupWithoutServing(){
startupWithServerState(State.INITIAL);
}
}
Leader 中的 ZooKeeperServer 启动
ZooKeeperServer.startupWithServerState(State state){
// 创建和启动 SessionTracker
if(sessionTracker == null) {
createSessionTracker();
}
startSessionTracker();
// 初始化 RequestProcessor
setupRequestProcessors();
// 其他各项基础服务
startRequestThrottler();
registerJMX();
startJvmPauseMonitor();
registerMetrics();
// TODO_MA 注释: 更新状态为 RUNNING
setState(state);
// 解除其他线程的阻塞
notifyAll();
}
其中,最为重要的两件事有两件:
- 创建和启动 SessionTracker 会话管理器。
- 初始化各种 RequestProcessor。
ZooKeeper SessionTracker 启动和工作机制详解
在 Leader 启动的时候,Leader 会创建 LeaderSessionTracker,在 Follower 启动的时候,内部会创建一个 LearnerSessionTracker。SessionTracker 的内部都有 globalSessionTracker 和 localSessionTracker 之分,但是无论如何,都是通过 SessionTrackerImpl 和 ExpiryQueue 来完成 Session 管理的。
Leader 和 Follower 的 RequestProcessor 初始化
Leader 的 setupRequestProcessors() 方法的核心逻辑:
Leader RequestProcessor 详解:
- LeaderRequestProcessor:Leader 调用链开始, 这个处理器主要是处理本地 session 相关的请求。
PrepRequestProcessor:请求预处理器,能够识别出当前客户端请求是否是事务请求。对于事务请求,PrepRequestProcessor 处理器会对其进行一系列预处理,如创建请求事务头、事务体、会话检查、ACL 检查和版本检查等。 - ProposalRequestProcessor:事务投票处理器。Leader 服务器事务处理流程的发起者。接收到非事务请求不做什么处理,会直接将请求转发到 CommitProcessor,接收到事务请求,除了将请求转发到 CommitProcessor 外,还会根据请求类型创建对应的 Proposal 提议并广播给所有 Follower 进行投票。另外,它还会将事务请求交付给 SyncRequestProcessor 进行事务日志的记录。
- CommitProcessor:事务提交处理器。对于非事务请求,该处理器会直接将其交付给下一级处理器处理;对于事务请求,其会等待集群内针对 Proposal 的投票直到该 Proposal 可被提交,利用 CommitProcessor,每个服务器都可以很好地控制对事务请求的顺序处理。
- ToBeAppliedRequestProcessor:该处理器有一个 toBeApplied 队列,用来存储那些已经被 CommitProcessor 处理过的可被提交的 Proposal。其会将这些请求交付给 FinalRequestProcessor 处理器处理,待其处理完后,再将其从 toBeApplied 队列中移除。
- FinalRequestProcessor:FinalRequestProcessor 用来进行客户端请求返回之前的操作,包括创建客户端请求的响应,针对事务请求,该处理还会负责将事务应用到内存数据库中去
- SyncRequestProcessor:事务日志记录处理器。负责将事务持久化到磁盘上。实际上就是将事务数据按顺序追加到事务日志中,同时会触发 ZooKeeper 进行数据快照。
- AckRequestProcessor:负责在 SyncRequestProcessor 完成事务日志记录后,向 Proposal 的投票收集器发送 ACK 反馈,以通知投票收集器当前服务器已经完成了对该 Proposal 的事务日志记录。
Follower 的 RequestProcessor 初始化
不管是 follower 还是 leader, 不管是读请求,还是写请求, RP 处理链的入口,都是 firstProcessor。
Follower 的 setupRequestProcessors() 方法的核心逻辑:
Follower RequestProcessor 详解:
- FollowerRequestProcessor:识别当前请求是否是事务请求,若是,那么 Follower 就会将该请求转发给 Leader 服务器,Leader 服务器是在接收到这个事务请求后,就会将其提交到请求处理链,按照正常事务请求进行处理。
- CommitProcessor:同 Leader 的 CommitProcessor
- FinalRequestProcessor:同 Leader 的 FinalRequestProcessor
- SyncRequestProcessor:同 Leader 的 SyncRequestProcessor
- SendAckRequestProcessor:其承担了事务日志记录反馈的角色,在完成事务日志记录后会向 Leader 服务器发送 ACK 消息以表明自身完成了事务日志的记录工作。当 Leader 服务器接收到足够确认消息来提交这个提议时,Leader 就会发送提交事务消息给追随者(同时也会发送 INFORM 消息给观察者服务器)。当接收到提交事务消息时,追随者就通过 CommitProcessor 处理器进行处理。
ZooKeeper 客户端初始化

- SendThread 内部保存了一个 ClientCnxnSocketNIO,相当于一个 NIO 的客户端,负责和 ZooKeeper 的 ServerCnxnFactory 中启动的服务端建立连接,然后负责消费 outgoingQueue 中的消息,执行请求发送。
- EventThread 线程消费 waitingEvents 队列,调用 processEvent(event) 负责处理服务端返回回来的消息,事件,异步回调等。
- 客户端状态枚举类实例
public enum States {
CONNECTING,
ASSOCIATING,
CONNECTED,
CONNECTEDREADONLY,
CLOSED,
AUTH_FAILED,
NOT_CONNECTED;
}
- 客户端实际请求地址方式:random —— 打乱随机获取。
ZooKeeper 服务端初始化
NIOServerCnxnFacotry 内部首先启动(一个 AcceptorThread, 多个 SelectorThread,一个线程池(WorkerThread))。每次接收到一个客户端链接请求,在服务端会生成一个 ServerCnxn 的组件,这个对象的内部就是封装了一个 SocketChannel,专门对某个 client 执行服务。
在 ZooKeeper 的客户端 ClientCnxn 初始化的时候,是由内部的 SendThread 发起连接请求给服务端建立连接,然后服务端的会给当前的客户端生成一个 ServerCnxn,一个客户端就会有一个对应的 ServerCnxn,相当于 ServerCnxn 和 ClientCnxn 是一一对应的关系。而且当服务端 生成好了 ServerCnxn 之后,还会给当前这个连接创建一个 Session,通过 Session 来管理这个链接。
默认 selector 线程个数:处理器个数/ 2 开根号 跟1 求最大值
默认 worker 线程个数:处理器个数 * 2
默认 worker 线程超时时间:5s
启动过程:
- 第一步:创建服务端 NIOServerCnxnFactory
- 第二步:对 NIOServerCnxnFactory 进行初始化
- 第三步:启动 NIOServerCnxnFactory 内部的各种工作线程
- AcceptThread 负责接受链接请求,建立连接
- SelectorThread 负责 IO 读写
- WorkerService 负责请求处理
- ConnectionExpirerThread 线程负责链接超时管理
客户端和服务端链接建立全流程分析

小结
关于 ZooKeeper 的会话创建流程:文章来源:https://www.toymoban.com/news/detail-795560.html
- 第一步:ZooKeeper 对象内部的 ClientCnxn 内部的 HostProvider 会随机选一个我们提供的地址,然后委托给 ClientCnxnSocket 去建立和 ZooKeeper 服务端之间的 TCP 链接。
- 第二步:SendThread(Client 的网络发送线程)构造出一个 ConnectRequest 请求(代表客户端与服务器创建一个会话)。同时,Zookeeper 客户端还会进一步将请求包装成网络 IO 的 Packet 对象,放入请求发送队列 outgoingQueue 中去等待发送。
- ClientCnxnSocket 从 outgoingQueue 中取出 Packet 对象,将其序列化成 ByteBuffer 后,向服务器进行发送。
- 服务端的 SessionTracker 为该会话分配一个 sessionId,并发送响应。
- Client 收到响应后,此时此刻便明白自己没有初始化,因此会用 readConnectResult 方法来处理请求。
- ServerCnxnSocket 会对接受到的服务端响应进行反序列化,得到 ConnectResponse 对象,并从中获取到 Zookeeper 服务端分配的会话 SessionId。
- 通知 SendThread,更新 Client 会话参数(比如重要的 connectTimeout ),并更新 Client 状态;另外,通知地址管理器 HostProvider 当前成功链接的服务器地址。
- 注意点:
对于 Leader-Follower 通信,心跳消息由 Leader 发送给 Follower;
对于 Server-Client 通信,心跳消息由 Client 发送给 Server。
zookeeper 中的设计模式
watcher => 模板方法模式
requestProcessors =>职责链模式(netty 的 pipeline 也用到了类似的思想)
zookeeper => ZKDataBase 用到了 外观模式(能力增强)、组合模式(子节点管理)文章来源地址https://www.toymoban.com/news/detail-795560.html
到了这里,关于Zookeeper设计理念与源码剖析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!