目录
介绍
实现过程
模板
例题详解
1.枚举排列
2.迷宫寻路
3.八皇后
剪枝与优化
作业
今天我们来学习一个极其重要的算法:深度优先搜索。
介绍
深度优先搜索,又叫DFS,是遍历图或者数的一种算法,本质就是递归。具体方法:先以一个节点为起点,向一个方向扩展,再以新的节点为起点,向一个方向扩展,直到这个方向不满足条件,或者到达这个方向的最深,再往回走,叫做回溯。然后扩展另一个方向,知道整个图都遍历完成。所以叫做深度优先搜索。
这种算法极其重要,是每一个会编程的人都必须掌握的一种算法。因为许多东西都可以用它来实现。比如树的遍历,图的遍历,全排列。而且很多题目,如果你不会或者想不出正解,就可以用深搜暴力一下,也能骗得部分分。而且加上一定的优化和剪枝,通常能得不少分。
实现过程
深搜就是每次从一个点开始,枚举下一个节点,如果合法就深搜下一个点,并将深度加一。如果深度超出范围,就保存答案,并返回。每次搜下一个点时需要打上访问标记,防止在这一条路上再次访问这个点。注意,是在这条路上!今后在别的路上还是可以访问这个点的,所以搜完这条路需要删除访问标记,让从另一条路来的时候还可以访问这个点,这就是回溯。问了方便理解,我配了几张图来辅助解释。
首先,我们从A点开始,A点可以向下访问F、G两个点。

发现F点合法,我们先访问F点。

然后从F点开始,可以访问D、E点,我们先访问E点。

同样,E可以走到D、C、G,但是F已经访问过,有了访问标记,就不能走了。所以我们走C点

C点只与A、D、E相连,我们一个一个去试,如果合法就访问。

发现A点有了访问标记,所以不能走,返回,找下一个点。

还剩下D,就访问他了。 但是D点只与C、E、F相连,而他们都有了访问标记,所以D这个点走不通,只好回头。

现在回到了C点,发现C点也无路可走,因为D点刚刚试过走不通,其他点又都有访问标记,这就证明C点也走不通,只好返回E点。

再从E点访问其他的点。
后面就是按照前面的进行一步步模拟,然后访问完所有的点。知道了实现过程,我们就结合具体的题目详细讲解吧!
模板
在讲题目之前,我先把深搜的模板列出,方便大家进一步理解,并将思路转化成代码。下面是深搜的模板:
void dfs(int num, int deep){//num为遍历的节点,deep为节点深度。
if(deep > max_deep){//超出最大深度。
保存答案。
return;
}
枚举下一个节点 i ,i满足未访问并且满足特定条件。
v[i] = 1;//i节点标记为已访问。
dfs(i, deep + 1);
v[i] = 1;//回溯,下一次从不同的路来还能访问。这一步看具体题目,有些题目就无需回溯。
}其中回溯有部分题目不需要,因为回溯就是为了下一次还能从不同的道路访问这个点,而有些情况下一个点可能只访问一次。所以回溯与否需要自己判断,不过大部分题目都是需要回溯的。这u需要自己判断,而理解了回溯后你基本就理解了深搜了。
例题详解
1.枚举排列
题目描述
今有 nn 名学生,要从中选出 kk 人排成一列拍照。
请按字典序输出所有可能的排列方式。
输入格式
仅一行,两个正整数 n, kn,k。
输出格式
若干行,每行 kk 个正整数,表示一种可能的队伍顺序。
输入输出样例
输入 #1
3 2
输出 #1
1 2 1 3 2 1 2 3 3 1 3 2
说明/提示
对于 100% 的数据,1≤k≤n≤10。
看到这一题,我们先想要哪些参数。其实只要一个,就是当前搜到的位数。
只要一位一位得搜,当位数超出了 k 时,就代表搜到了答案。每次搜将这一位的结果保存到数组里,搜完输出数组结果。当然,要将每一位用到的数加上访问标记,然后回溯。
一下是遮体的代码:
#include<bits/stdc++.h>
using namespace std;
int n, k, p = 1;
int ch[1005];
bool use[1005];
void dfs(int pos){
if(pos == k + 1){
for(int i = 1; i <= p - 1; i++){
cout << ch[i] << " ";
}
cout << endl;
return;
}
for(int i = 1; i <= n; i++){
if(!use[i]){
ch[p++] = i;
use[i] = 1;
dfs(pos + 1);
p--;
use[i] = 0;
}
}
return;
}
int main(){
cin >> n >> k;
dfs(1);
return 0;
}可以看到,回溯不仅仅是去除访问标记,还将存储答案的数组也回溯了。这是因为这次搜到的答案不能对下次有影响,就相当于清空了数组,只不过回溯是只清除了当前这一位。
2.迷宫寻路
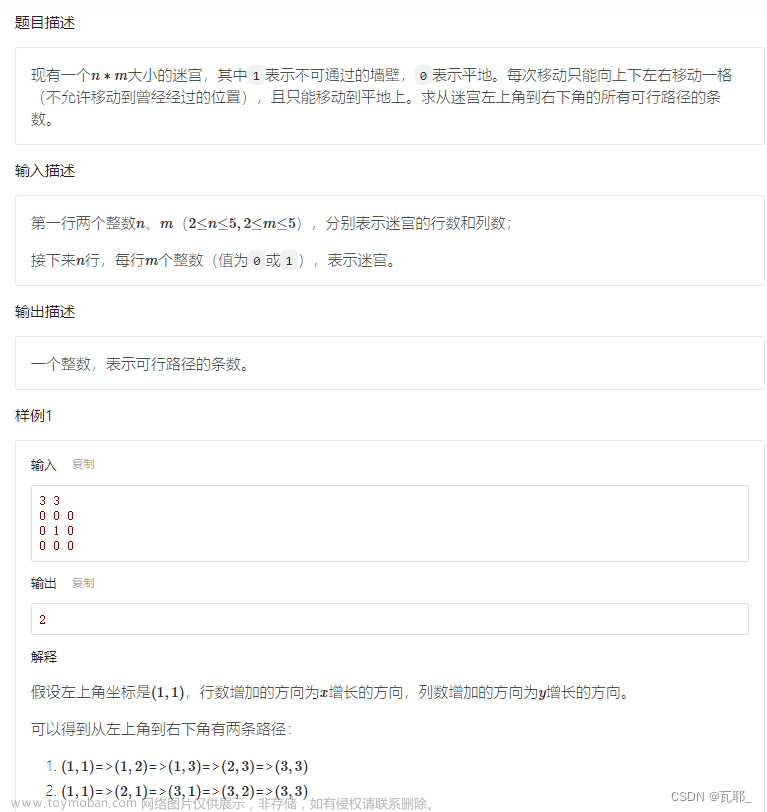
题目描述
机器猫被困在一个矩形迷宫里。
迷宫可以视为一个 n×m 矩阵,每个位置要么是空地,要么是墙。机器猫只能从一个空地走到其上、下、左、右的空地。
机器猫初始时位于(1,1) 的位置,问能否走到 (n,m) 位置。
输入格式
第一行,两个正整数 n,m。
接下来 n 行,输入这个迷宫。每行输入一个长为 m 的字符串,# 表示墙,. 表示空地。
输出格式
仅一行,一个字符串。如果机器猫能走到 (n,m),则输出 Yes;否则输出 No。
输入输出样例
输入 #1
3 5 .##.# .#... ...#.
输出 #1
Yes
说明/提示
样例解释
路线如下:(1,1)→(2,1)→(3,1)→(3,2)→(3,3)→(2,3)→(2,4)→(2,5)→(3,5)。
数据规模与约定
对于 100% 的数据,保证 1≤n,m≤100,且 (1,1) 和 (n,m) 均为空地。
这一题是比较经典的深搜了。而且还有一个坑点。我们先思考搜索函数有拿哪些参数。就是 x 和 y ,表示当前搜到的横、纵坐标。
然后我们判断当前点是否是终点,如果是,就将 flag 设为1,代表这个地图可以走通。如果不是重点,那我们就枚举下一个点并搜索。怎么枚举下一个点呢?如果我们规定向上纵坐标减一,向下加一,向左横坐标减一,向右加一。那我们就可以用一个数字来表示横、纵坐标的加减情况。
int dx[] = {-1, 0, 1, 0},
dy[] = {0, -1, 0, 1};每次用当前的坐标加上 dx[i], dy[i],就获得了向左、上、右、下的点的坐标。
然后我们判断当前点是否合法。就是判断点是否超出了地图,是否是‘.’,也就是能走,是否被走过了。这样我们就得到了一个 check() 函数:
bool check(int x, int y){
return (!u[x][y] && ch[x][y] == '.' && x > 0 && y > 0 && x <= n && y <= m);
}如果当前点 check 合法,就将这个点标记为访问,并搜索这个点。
最后我们判断 flag 的情况,如果为1,就说明走到过终点,输出 Yes ,否则输出 No 。这样我们就得到了一个最初版的代码:
#include<bits/stdc++.h>
using namespace std;
int dx[] = {-1, 0, 1, 0},
dy[] = {0, -1, 0, 1};
int n, m;
bool u[105][105], flag;
char ch[105][105];
bool check(int x, int y){
return (!u[x][y] && ch[x][y] == '.' && x > 0 && y > 0 && x <= n && y <= m);
}
void dfs(int x, int y){
if(x == n && y == m){
flag = 1;
return;
}
for(int i = 0; i < 4; i++){
int xx = dx[i] + x;
int yy = dy[i] + y;
if(check(xx, yy)){
u[xx][yy] = 1;
dfs(xx, yy);
u[xx][yy] = 0;
}
}
}
int main(){
cin >> n >> m;
for(int i = 1; i <= n; i++){
for(int j = 1; j <= m; j++){
cin >> ch[i][j];
}
}
dfs(1, 1);
if(flag){
cout << "Yes" << endl;
return 0;
}
cout << "No" << endl;
return 0;
}为什么说是最初版呢?因为

啊这,很明显,朴素的算法不能通过,我们需要优化。
大家可以先想一下怎么优化。
1. 第一个优化比较好想到,就是我们每次搜索时判断是否到过终点。如果已经到过终点,也就是 flag = 1,那么就不需要搜下去了,直接返回。因为再搜下去也不会对结果产生影响。
基于这个思路,我们再提交一次代码:
#include<bits/stdc++.h>
using namespace std;
int dx[] = {-1, 0, 1, 0},
dy[] = {0, -1, 0, 1};
int n, m;
bool u[105][105], flag;
char ch[105][105];
bool check(int x, int y){
return (!u[x][y] && ch[x][y] == '.' && x > 0 && y > 0 && x <= n && y <= m);
}
void dfs(int x, int y){
if(flag) return;
if(x == n && y == m){
flag = 1;
return;
}
for(int i = 0; i < 4; i++){
int xx = dx[i] + x;
int yy = dy[i] + y;
if(check(xx, yy)){
u[xx][yy] = 1;
dfs(xx, yy);
u[xx][yy] = 0;
}
}
}
int main(){
cin >> n >> m;
for(int i = 1; i <= n; i++){
for(int j = 1; j <= m; j++){
cin >> ch[i][j];
}
}
dfs(1, 1);
if(flag){
cout << "Yes" << endl;
return 0;
}
cout << "No" << endl;
return 0;
}结果:

哇,没错,我们就加上了一行代码,就从10pts到了20pts。别小瞧这10分,考场上能救你命(doge)。
所以我们还要优化。
2.这次的优化有点伤脑筋,希望大家好好想一想再看下去。
好的,其实我们可以在回溯上面动手脚(bushi)。我们再想一想回溯的作用:让下一次从别的路径过来时还能访问这个点。那我们这次还需要再次访问这个点吗?答案是否定的,因为如果我们访问了这个点,也就能确定从这个点能不能走向终点,不管从哪条路走到这个点,都不能改变这个点能走向终点或是不能。所以我们就可以去掉回溯!
所以程序3.0版本就有了
#include<bits/stdc++.h>
using namespace std;
int dx[] = {-1, 0, 1, 0},
dy[] = {0, -1, 0, 1};
int n, m;
bool u[105][105], flag;
char ch[105][105];
bool check(int x, int y){
return (!u[x][y] && ch[x][y] == '.' && x > 0 && y > 0 && x <= n && y <= m);
}
void dfs(int x, int y){
if(flag) return;
if(x == n && y == m){
flag = 1;
return;
}
for(int i = 0; i < 4; i++){
int xx = dx[i] + x;
int yy = dy[i] + y;
if(check(xx, yy)){
u[xx][yy] = 1;
dfs(xx, yy);
}
}
}
int main(){
cin >> n >> m;
for(int i = 1; i <= n; i++){
for(int j = 1; j <= m; j++){
cin >> ch[i][j];
}
}
dfs(1, 1);
if(flag){
cout << "Yes" << endl;
return 0;
}
cout << "No" << endl;
return 0;
} 这次终于如愿以偿:
看到一片绿我就兴奋(doge)。
我们再想一下,为什么其它的搜索需要回溯呢?其实因为我们搜索的目的不同,这一题我们只需要知道是否能到达终点,所以从哪个点过来结果都是一样的。但是有些题目如果求的是最短路,那么从不同的点过来的结果就可能不同,所以我们需要回溯。
3.八皇后
题目描述
一个如下的 6×6 的跳棋棋盘,有六个棋子被放置在棋盘上,使得每行、每列有且只有一个,每条对角线(包括两条主对角线的所有平行线)上至多有一个棋子。

上面的布局可以用序列 2 4 6 1 3 5 来描述,第 i 个数字表示在第 i 行的相应位置有一个棋子,如下:
行号 1 2 3 4 5 6
列号 2 4 6 1 3 5
这只是棋子放置的一个解。请编一个程序找出所有棋子放置的解。
并把它们以上面的序列方法输出,解按字典顺序排列。
请输出前 3 个解。最后一行是解的总个数。
输入格式
一行一个正整数 n,表示棋盘是 n×n 大小的。
输出格式
前三行为前三个解,每个解的两个数字之间用一个空格隔开。第四行只有一个数字,表示解的总数。
输入输出样例
输入 #1
6
输出 #1
2 4 6 1 3 5 3 6 2 5 1 4 4 1 5 2 6 3 4
说明/提示
【数据范围】
对于 100% 的数据,6≤n≤13。
题目翻译来自NOCOW。
USACO Training Section 1.5
这是一道很经典的深搜题,可以说会深搜都掌握了这道题。我们也从这道题向难题进发。
首先还是思考搜索函数有哪些参数,我们只需要一个 pos ,代表我们搜到了哪一行。所以结束条件就是行号 = n + 1。然后我们需要注意,这一题的访问标记不是简简单单的将这个点的坐标存起来,因为每一行、每一列、每一对角线都不能有超过一个棋子。也就是我们要用三个数组,来记录每一行、每一列、每一对角线是否有棋子。
然后就是怎么存储答案了。我们枚举的时候就把行号作为下标,列号作为值,存在一个数组里。这样只要输出数组里得知就可以了。
这一题没什么坑点,主要是熟练掌握深搜模板。下面是代码:
#include<bits/stdc++.h>
using namespace std;
int n, sum, a[105], b[105], c[105], d[105];
void dfs(int pos){
if(pos == n + 1){
sum++;
if(sum <= 3){
for(int j = 1; j <= n; j++){
cout << a[j] << " ";
}
cout << endl;
}
return;
}
for(int i = 1; i <= n; i++){
if(!b[i] && !c[pos + i] && !d[pos - i + n]){
a[pos] = i;
b[i] = c[pos + i] = d[pos - i + n] = 1;
dfs(pos + 1);
b[i] = c[pos + i] = d[pos - i + n] = 0;
}
}
return;
}
int main(){
cin >> n;
dfs(1);
cout << sum << endl;
return 0;
}剪枝与优化
剪枝就是对深搜的优化。在有些图中搜索完整个图会有很多很多冗余,比如在找最短路径时,我们每次在到达终点时记录最短距离,然后以后搜索时如果当前点到终点的距离加上已经走的距离已经超过最短的距离了,那么无论如何这条路也不会成为最短路径。我们直接 return 就好了。以上是一个比较简单的剪枝思路。
而优化主要就是记忆化搜索。我们把搜索函数中的某个参数存在数组里,比如你已经搜索得知了这个点到终点的最短距离,就无需再搜索下去,直接返回保存过的这个点到终点的距离就好了。
以上只是很简单的思路,真正的优化是很复杂的,以后会专门为这个写一篇文章。
作业
我搜集了几道比较好的搜索题,大家可以自己练习巩固。难度由易到难
- p1135奇怪的电梯。
- p1562还是n皇后。
- p1074靶形数独
以及一个无需回溯的搜索:p1331海战文章来源:https://www.toymoban.com/news/detail-795592.html
以上这几题如果你能独立做出来,并且每题控制在一小时以内,那么你的深搜就完结~撒花。文章来源地址https://www.toymoban.com/news/detail-795592.html
到了这里,关于c++深度优先搜索DFS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!