机器学习 | 卷积神经网络
实验目的
采用任意一种课程中介绍过的或者其它卷积神经网络模型(例如LeNet-5、AlexNet等)用于解决某种媒体类型的模式识别问题。
实验内容
- 卷积神经网络可以基于现有框架如TensorFlow、Pytorch或者Mindspore等构建,也可以自行设计实现。
- 数据集可以使用手写体数字图像标准数据集,也可以自行构建。预测问题可以包括分类或者回归等。实验工作还需要对激活函数的选择、dropout等技巧的使用做实验分析。必要时上网查找有关参考文献。
- 用不同数据量,不同超参数,比较实验效果,并给出截图和分析
实验环境
Windows11; Anaconda+python3.11; VS Code
实验过程、结果及分析(包括代码截图、运行结果截图及必要的理论支撑等)
4.1 算法理论支撑
4.1.1 卷积神经网络(CNN)的基本原理

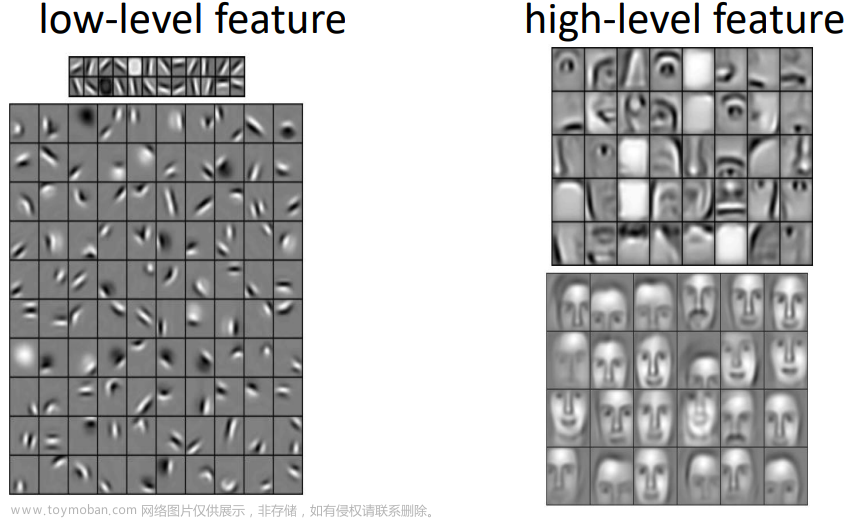
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,特别设计用于处理和分析具有网格结构的数据,如图像和视频。它能够自动学习图像中的特征并进行高效的图像分类、对象检测、图像生成和分割等任务,其模型结构主要包含以下部分:
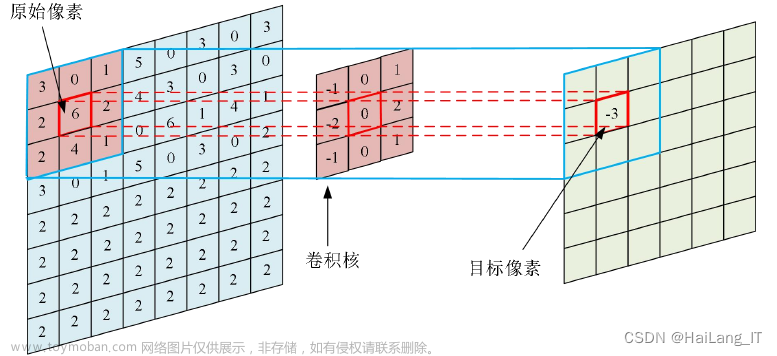
- 卷积层: 卷积层负责从图像中提取特征,如边缘和纹理。它们通过应用过滤器来捕捉这些特征,逐渐形成更复杂的视觉模式。
- 池化层: 池化层在保留基本信息的同时减小了特征图的大小。最常见的方法是最大池化,它有助于缩小图像,同时保持关键特征并增强鲁棒性。
- 全连接层: 全连接层结合从前一层提取的特征进行分类和决策。他们将这些特征映射到不同的类别,识别图像中的内容。
4.1.2 AlexNet的基本结构
AlexNet网络结构相对简单,使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层,具体如下图2所示。

与原始的LeNet相比,AlexNet网络结构更深,同时还包括以下特点:
- ReLU激活函数的引入:采用修正线性单元(ReLU)的深度卷积神经网络能够大幅提高训练速度,同时能够有效防止过拟合现象的出现。
- 层叠池化操作:AlexNet中池化层采用了层叠池化操作,即池化大小>
 步长,这种类卷积操作可以使相邻像素间产生信息交互和保留必要的联系。
步长,这种类卷积操作可以使相邻像素间产生信息交互和保留必要的联系。 - Dropout操作:Dropout操作会将概率小于0.5的每个隐层神经元的输出设为0,即去掉一些神经节点,能够有效防止过拟合现象的出现。
4.2 实验设计
4.2.1 实验数据集及数据预处理
MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据集,包含60,000个样本的训练集以及10,000个样本的测试集。其中包括0到9的数字。

在本实验中,使用torchvision自带的数据集加载MNIST和CIFAR-10数据集,并使用transforms.ToTensor方法加载为Tensor张量,最后通过DataLoader加载进GPU进行运算。

4.2.2 模型设计
在本次实验中,仿照AlexNet,实现了包含五个卷积层和三个全连接层构建一个深度卷积神经网络,网络的定义是重写nn.Module实现的,卷积层和全连接层之间将数据通过view拉平,同时可选择加入Dropout层防止数据过拟合。
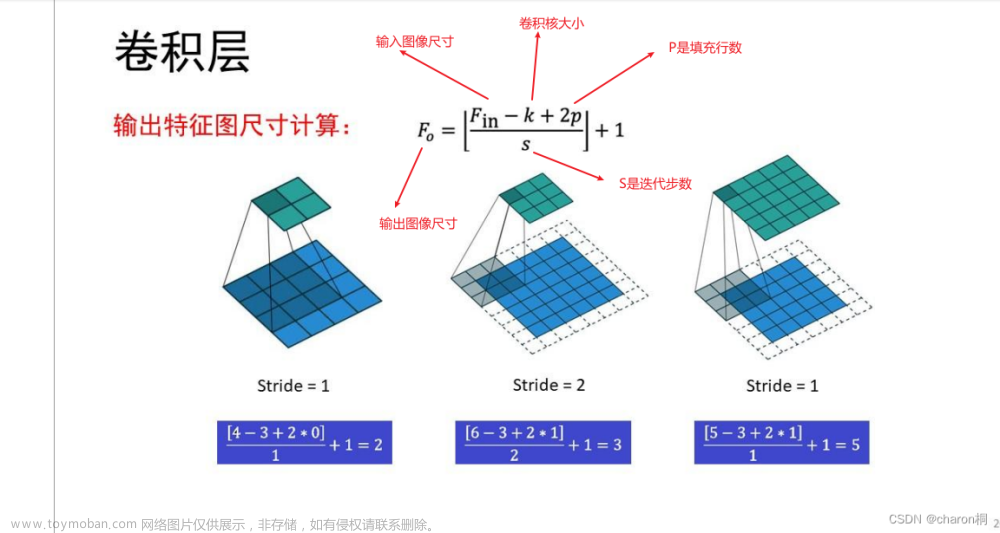
Feature map数变化:1→32→64→128→256,卷积核kernel size均为3,同时在边缘填充单位长度的0,步幅均为1。
MaxPooling核大小为2×2,每次将特征图大小缩为原来的一半。

4.3 实验结果及分析
4.3.1 实验结果
在本次实验中,使用交叉熵损失函数和SGD优化器,激活函数采用ReLU,将模型输入通道根据数据集设为1 ,并设置训练超参数epoch为10,batch size为128,学习率learning rate为0.01。训练过程中损失函数loss的值和在测试集上的准确率变化如下图所示。
,并设置训练超参数epoch为10,batch size为128,学习率learning rate为0.01。训练过程中损失函数loss的值和在测试集上的准确率变化如下图所示。
实验发现,随训练过程的进行,损失函数不断降低,在测试集上准确率逐渐升高,最终测试正确率最高能够达到约98.94%。损失函数和测试准确率在训练最后阶段呈现波动态,可能原因是在局部最优点附近振荡。

而后通过torch.load方法加载模型对测试集进行直观展示,模型能够对手写数字作出较为准确的分类,具有一定的泛化能力。
4.3.2 不同激活函数的比较
将所有激活函数换为Sigmoid函数,发现结果很差,损失函数强烈震荡,几乎毫无效果。分析原因可能为:
- 梯度消失:Sigmoid在输入极值附近的梯度接近于零,这可能导致梯度消失问题,特别是在深层网络中。这可能会影响网络的训练效率和能力。
- 输出偏移:Sigmoid函数的输出在0到1之间,这意味着它倾向于产生偏向于0或1的输出,这可能在梯度下降过程中导致网络权重的不稳定更新。
- 非稀疏性:与ReLU不同,Sigmoid的输出不稀疏,因为它在整个输入范围内都有非零输出。这可能导致网络的表示能力受到限制。

而将所有激活函数换为LeakyReLU函数,发现结果有一定提升,最高能够达到99.13% 左右,且收敛速度较快,原因可能为:
左右,且收敛速度较快,原因可能为:
传统的 ReLU 在负数输入时输出为零,这可能导致梯度在训练过程中变得非常小或者为零,称为梯度消失。Leaky ReLU 引入了一个小的负数斜率,使得梯度在负数输入时仍然存在,从而导致更均匀的梯度分布,可以减少训练过程中的梯度爆炸问题,并使权重更新更加平滑。

实验结论
卷积神经网络使用卷积操作,相较于全连接,其网络层与层之间的连接是稀疏的。其次同一层的卷积的参数是共享的,且每一层的卷积运算可以并行处理,具有较快的学习和推理速度,同时也具有较强的表示和学习能力,在图像分类领域具有较为广泛的应用。
同时,需要针对数据集和具体任务选择合理的超参数,采用合适的权重初始化方法,能够有效提高模型的性能。同时,适时的引入Dropout操作,可以通过随机断开神经元的连接,使模型更具鲁棒性,降低模型过拟合风险。文章来源:https://www.toymoban.com/news/detail-795821.html
此外,CNN 还可用作其他任务的基础模型,如生成对抗网络(GAN),作为其backbone模型来辅助生成高质量的图像。文章来源地址https://www.toymoban.com/news/detail-795821.html
到了这里,关于机器学习 | 卷积神经网络的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!