本次抓取的是百傲瑞达的考勤机系统的数据。地址为内网地址172.200.0.200:8098
先简单介绍下系统页面及想要抓取数据的页面

登录页面输入用户名密码会跳转到一个统计的黑板页面

想要抓取的数据页面如下

解析下网站登录请求和打卡详情请求
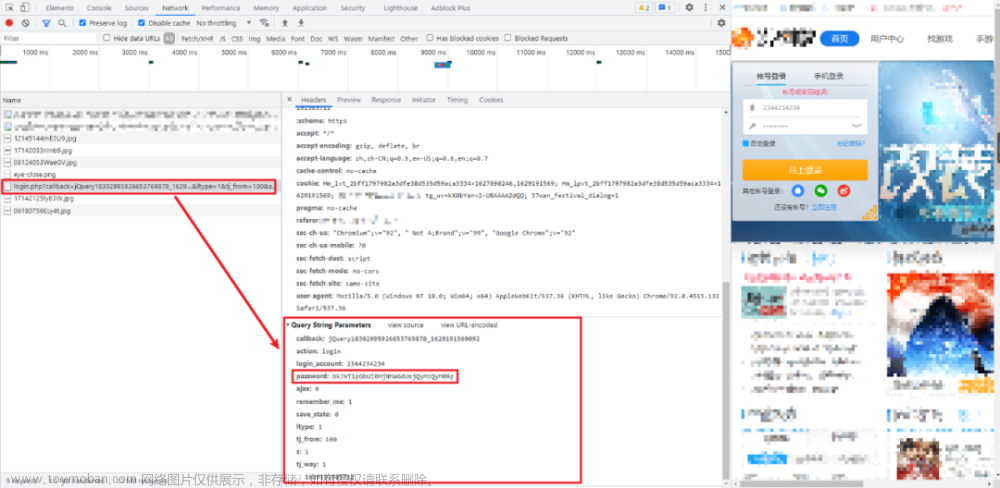
页面登录会出现跳转,f12无法定位到发送的请求记录,使用fiddler进行数据抓包

可以看到登录请求的地址,请求数据的格式content-type:application/x-www-form-urlencoded

请求的参数username,password,loginType,checkCode其中password的值与我们输入的值是不同的,存在某种加密。不必考虑这个数据是通过什么加密方式进行加密的,在请求的时候直接传递这个值即可。

请求后返回的content内容,说明请求成功。

cookies中也有服务器返回的cookie数据,从返回头中我们也可以看到相关的数据。cookie数据是我们请求该网站别的地址必须的参数。

使用postcat工具(postman等都可)测试下登录操作

可以验证登录操作是能正常返回数值的。

返回头的数据也包含了我们需要的cookie数据。
接下来看下我们需要的获取的数据是如何请求到的。

可知是通过这个地址的请求获取到的数据

请求头中数据的类型,请求头的值

传递的参数及值。
然后使用postcat进行验证下想法是否正确


请求结果如下:

进行第二页请求的时候,发现参数变了,增加了几个参数,没必要再次测试加参后的调用了。

接下来进行代码实现
import requests
url = 'http://172.200.0.200:8098/login.do'
data = {
'username': 'admin',
'password': '21232f297a57a5a743894a0e4a801fc3',
'loginType': 'NORMAL'
}
#该网站没有拦截非浏览器的请求,因此没有定义header,也可定义个header,post操作的时候将header参数带上
response = requests.post(url, data=data)
print(response.content.decode("utf-8"))
headers = response.headers
print(headers.get('Set-Cookie'))
请求打卡记录信息
temp_session=headers.get('Set-Cookie')
cookies = {
'SESSION': temp_session
}
data_daka=MultipartEncoder(
fields={
'list':'',
'pageSize':'50',
'startApplyDateTime': '2022-05-25 00:00:00',
'endApplyDateTime': '2022-08-25 23:59:59'
}
)
header = {
'Cookie': 'SESSION=' + temp_session,
'Content-Type': data_daka.content_type,
# 'Content-Type': mk.content_type,
'X-Requested-With': 'XMLHttpRequest'
}
# daka_url='http://172.200.0.200:8098/attLeave.do'
daka_url='http://172.200.0.200:8098/attDayCardDetailReport.do'
response2 = requests.post(daka_url, data=data_daka,headers=header)
print(response2.content.decode(encoding="utf-8"))发现print一下,发现打印出来的是登录页的信息,,这表示我们登录是失败的,此时我们重新分析下造成没有登录成功的原因。
仔细研究下fiddler捕获的数据,发现在login.do之前还有两个请求。并没有搞明白这两个请求是什么意思,不过可以实验下,大概就是一些验证的一些手段。接下来做个测试来看下。

先进行portalPwdEffectiveCheck,接下来的请求所用的session要保持一致,请求数据的值不清楚是什么意思,直接使用fiddler捕获的这个数据。
接下来portalCheckStrength操作

然后再进行login操作

接下来验证下这次获取的session是否正确

bingo!验证了猜想,确实是通过这种方式进行验证信息的,接下来直接上代码!
import requests
from requests_toolbelt import MultipartEncoder
import uuid
etoken=str(uuid.uuid4())
# portalPwdEffectiveCheck
url_check = "http://172.200.0.200:8098/portalPwdEffectiveCheck.do"
payload = "content=oVxLMq8Ye7UkQ.2FZdY0.2F5PqBU9mi3CWlLYkG6mM013J1BJuxzJyVhQMTqDrx6cXaq.2FpfS4ftO6g0QoDhdJripOXsklVC.2BpZSyI9GXuzcr7VHArOJkJZetZ.2BhOF1SQMYIU"
headers = {
'Content-Type': 'text/html',
'eo-token':etoken
}
check_response = requests.post(url_check, data=payload, headers=headers)
temp_cookie = check_response.headers.get('Set-Cookie').split(';')[0]
nologin_cookie = check_response.cookies
print("请求的:"+temp_cookie)
print("请求代码获取的"+str(nologin_cookie.items()))
ectoken=check_response.headers.get('eo-token')
# portalCheckStrength
url_strength='http://172.200.0.200:8098/portalCheckStrength.do'
strength_payload="strength=-1"
headers = {
'Content-Type': 'text/html',
'cookie':temp_cookie,
'eo-token':etoken
}
strength_response=requests.post(url_strength,data=strength_payload,headers=headers)
print(strength_response.content.decode('utf-8'))
# login
login_url='http://172.200.0.200:8098/login.do'
login_data = {
'username': 'admin',
'password': '21232f297a57a5a743894a0e4a801fc3',
'loginType': 'NORMAL'
}
login_headers={
'cookie':temp_cookie
}
response = requests.post(login_url, data=login_data,headers=login_headers)
print("login的cookie:"+str(response.cookies.items()))
login_session=response.headers.get('Set-Cookie').split(';')[0]
print("登陆后的session"+login_session)
#数据获取测试
daka_data=MultipartEncoder(
fields={
'list':'',
'pageSize':'50',
'startApplyDateTime': '2022-05-25 00:00:00',
'endApplyDateTime': '2022-08-25 23:59:59'
}
)
header = {
'Cookie': login_session,
'Content-Type': daka_data.content_type,
'X-Requested-With': 'XMLHttpRequest'
}
# daka_url='http://172.200.0.200:8098/attLeave.do'
daka_url='http://172.200.0.200:8098/attDayCardDetailReport.do'
response2 = requests.post(daka_url, data=daka_data,headers=header)
print(response2.content.decode(encoding="utf-8"))运行代码,完美解决该问题!

其实这种登录页面直接使用requests进行操作比较麻烦,我们可以使用selenium进行登录,获取登录后的cookie值,然后就可以进行个人操作了,这里需要使用到webdriver,建议使用chromedriver,由于本人的chrome版本太高了,官方没有给出这个版本的driver,因此使用了edgedriver,话不多说,直接上代码!文章来源:https://www.toymoban.com/news/detail-796295.html
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
from requests_toolbelt import MultipartEncoder
import json
import time
# options=option,executable_path='path_to_edge_driver', service_args=["--verbose"], service_log_path="NUL",
option = webdriver.EdgeOptions()
option.add_argument("headless")
driver = webdriver.Edge(option)
# option=webdriver.EdgeOptions()
# option.add_argument("headless")
# driver = webdriver.Edge()
driver.get('http://172.200.0.200:8098/')
time.sleep(2)
driver.find_element(By.CSS_SELECTOR, '#username').send_keys('admin')
driver.find_element(By.CSS_SELECTOR, '#password').send_keys('admin')
driver.find_element(By.CSS_SELECTOR, '#test').click()
cookie=driver.get_cookies()
print(cookie[0]['value'])
qj_url='http://172.200.0.200:8098/attLeave.do'
mk = MultipartEncoder(
fields={
'list': '',
'pageSize': '800',
'startApplyDateTime': '2022-05-25 00:00:00',
'endApplyDateTime': '2022-08-25 23:59:59'
}
)
pheader = {
'Cookie': 'SESSION=' + cookie[0]['value'],
'Content-Type': mk.content_type,
'X-Requested-With': 'XMLHttpRequest'
}
r=requests.post(qj_url,data=mk,headers=pheader)
rows = json.loads(r.content.decode(encoding="utf-8"))
print(rows)
这里有个坑,就是sleep这个位置,不解释了文章来源地址https://www.toymoban.com/news/detail-796295.html
到了这里,关于python使用requests进行登录操作,抓取所需信息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!