什么是网络爬虫
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
优先申明:我们使用的python编译环境为PyCharm
一、首先一个网络爬虫的组成结构:
爬虫调度程序(程序的入口,用于启动整个程序)
url管理器(用于管理未爬取得url及已经爬取过的url)
网页下载器(用于下载网页内容用于分析)
网页解析器(用于解析下载的网页,获取新的url和所需内容)
网页输出器(用于把获取到的内容以文件的形式输出)
二、编写网络爬虫
(1)准备所需库
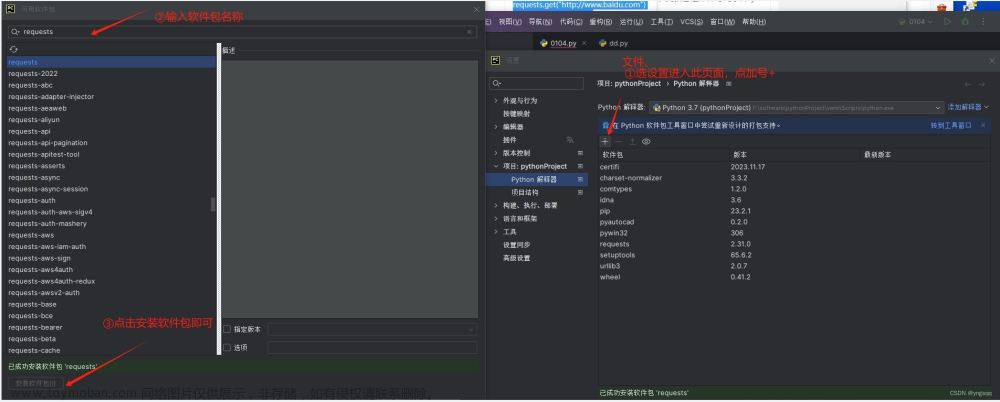
我们需要准备一款名为BeautifulSoup(网页解析)的开源库,用于对下载的网页进行解析,我们是用的是PyCharm编译环境所以可以直接下载该开源库。
步骤如下:
选择File->Settings

打开Project:PythonProject下的Project interpreter
点击加号添加新的库
输入bs4选择bs4点击Install Packge进行下载

(2)编写爬虫调度程序文章来源:https://www.toymoban.com/news/detail-796463.html
这里的bike_spider是文章来源地址https://www.toymoban.com/news/detail-796463.html
到了这里,关于Python 网络爬虫入门详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!