深入了解Transformer:从编码器到解码器的神经网络之旅
0.引言
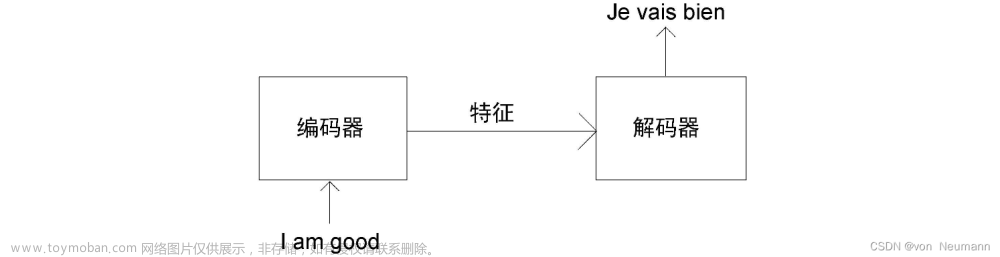
自2017年问世以来,Transformer模型在自然语言处理(NLP)领域引发了一场革命。它的独特设计和高效性能使其成为了解决复杂语言任务的关键工具。
1.Transformer的核心构成
(1)自注意力机制
Transformer的核心在于自注意力机制。它允许模型在处理每个词时考虑句子中的所有其他词,从而有效捕获长距离依赖关系。这是通过计算查询(Q)、键(K)和值(V)之间的关系实现的,其中注意力分数是通过以下公式计算得出的:
Attention(Q, K, V)
=
softmax
(
QK
T
d
k
)
V
\text{Attention(Q, K, V)} = \text{softmax}\left(\frac{\text{QK}^T}{\sqrt{d_k}}\right)\text{V}
Attention(Q, K, V)=softmax(dkQKT)V
(2)多头注意力
Transformer采用多头注意力机制,将注意力分散到不同的表示子空间,允许模型同时从多个角度理解信息。这种机制通过以下方式实现:
MultiHead(Q, K, V)
=
Concat
(
head
1
,
.
.
.
,
head
h
)
W
O
\text{MultiHead(Q, K, V)} = \text{Concat}(\text{head}_1, ..., \text{head}_h)\text{W}^O
MultiHead(Q, K, V)=Concat(head1,...,headh)WO
其中每个头部是独立的注意力计算:
head
i
=
Attention
(
QW
i
Q
,
KW
i
K
,
VW
i
V
)
\text{head}_i = \text{Attention}(\text{QW}_i^Q, \text{KW}_i^K, \text{VW}_i^V)
headi=Attention(QWiQ,KWiK,VWiV)

(3)位置编码
由于Transformer缺乏对输入序列顺序的处理能力,引入位置编码以赋予模型顺序感知能力。位置编码使用正弦和余弦函数的变化频率来编码不同位置的信息:
PE
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
1000
0
2
i
/
d
model
)
\text{PE}_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)
PE(pos,2i)=sin(100002i/dmodelpos)
PE ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) \text{PE}_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
2.Transformer的内部机制

(1)编码器和解码器层
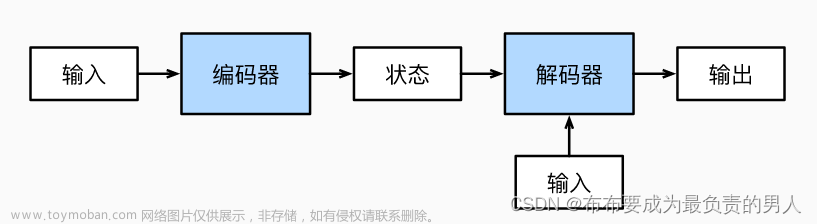
Transformer的架构分为编码器和解码器。
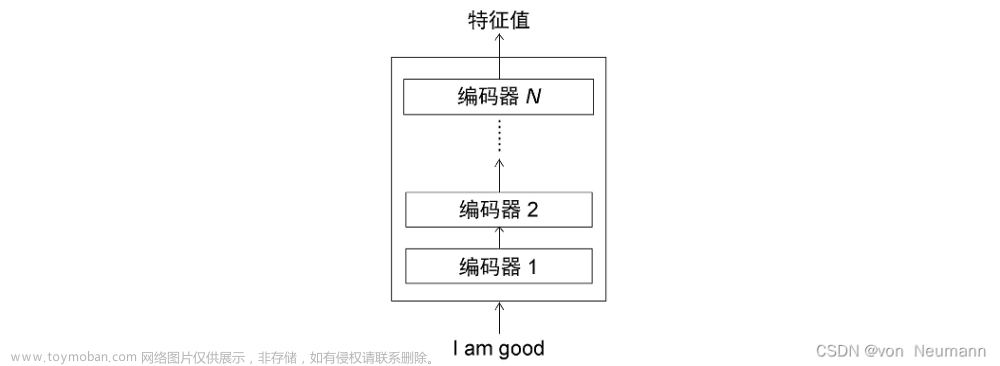
Transformer的编码器由N个相同的层堆叠而成,每层有两个子层。第一个子层是多头自注意力机制,第二个子层是简单的位置全连接前馈网络。每个子层周围有一个残差连接(residual connection),然后进行层归一化(layer normalization)。残差连接帮助避免在深层网络中出现梯度消失的问题。层归一化则是对每个子层的输出进行标准化处理,有助于稳定训练过程。
解码器部分也由N个相同的层构成。除了每层中的两个子层(多头自注意力层和前馈网络),解码器的每一层还包含第三个子层,该子层对编码器的输出执行多头注意力操作。
(2)前馈神经网络
编码器和解码器的每个层中都包含一个前馈神经网络,这是一个两层的线性变换过程,中间通过ReLU激活函数连接:
FFN
(
x
)
=
max
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
\text{FFN}(x) = \text{max}(0, x\text{W}_1 + b_1)\text{W}_2 + b_2
FFN(x)=max(0,xW1+b1)W2+b2
其中, W 1 W_1 W1, W 2 W_2 W2, b 1 b_1 b1, b 2 b_2 b2是网络参数。
(3)残差连接和层归一化
为了提高训练的稳定性和效率,Transformer采用了残差连接和层归一化。残差连接帮助模型在深层次中有效地传递梯度,而层归一化则保持了数据在网络中的平稳流动。文章来源:https://www.toymoban.com/news/detail-796618.html
3.Transformer的特点和优势
- 并行化能力:由于其非递归特性,Transformer在处理序列数据时实现了高效的并行处理。
- 长距离依赖处理:自注意力机制使Transformer能够有效地处理长距离的依赖,解决了传统RNN和LSTM在这方面的限制。
- 灵活性与通用性:Transformer适用于各种不同的任务,从文本翻译到内容生成,显示出极大的灵活性和广泛的适用性。
4.结语
Transformer的设计不仅是自然语言处理领域的一个重大突破,也为机器学习和人工智能的未来发展提供了新的视角。其强大的性能和广泛的应用潜力使其成为当前和未来技术进步的关键因素之一。文章来源地址https://www.toymoban.com/news/detail-796618.html
到了这里,关于深入了解Transformer:从编码器到解码器的神经网络之旅的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!