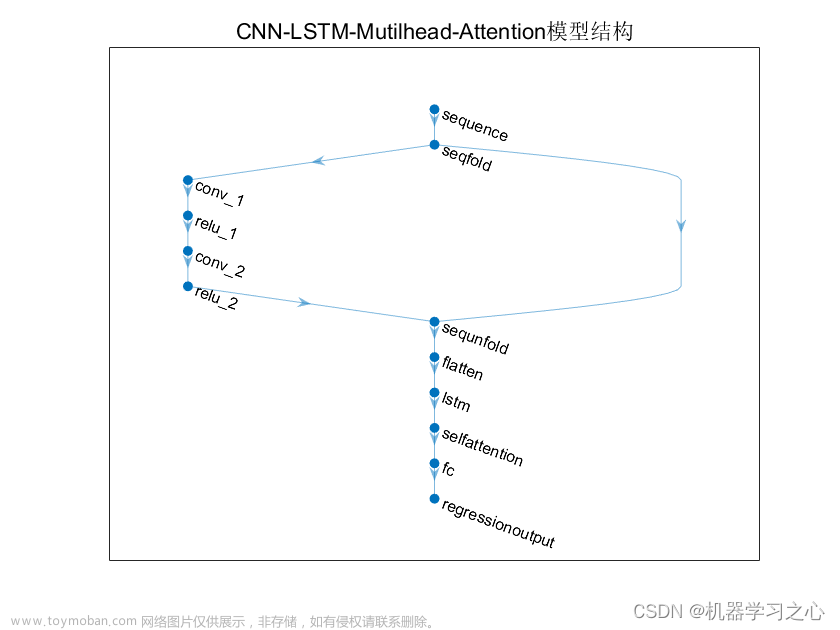
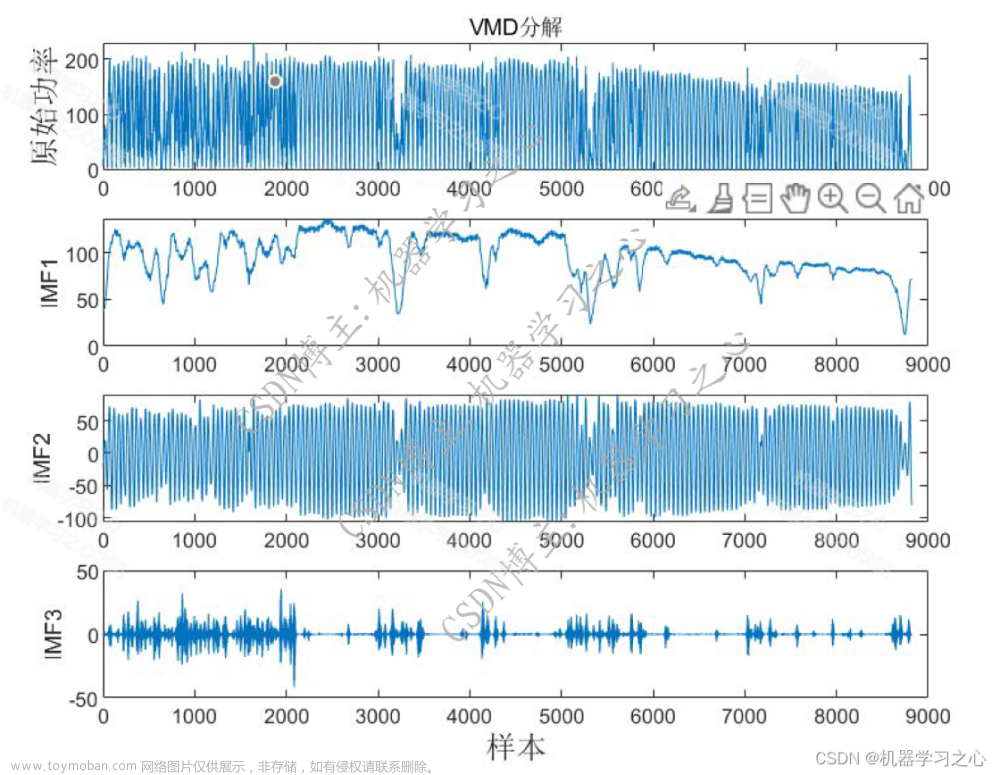
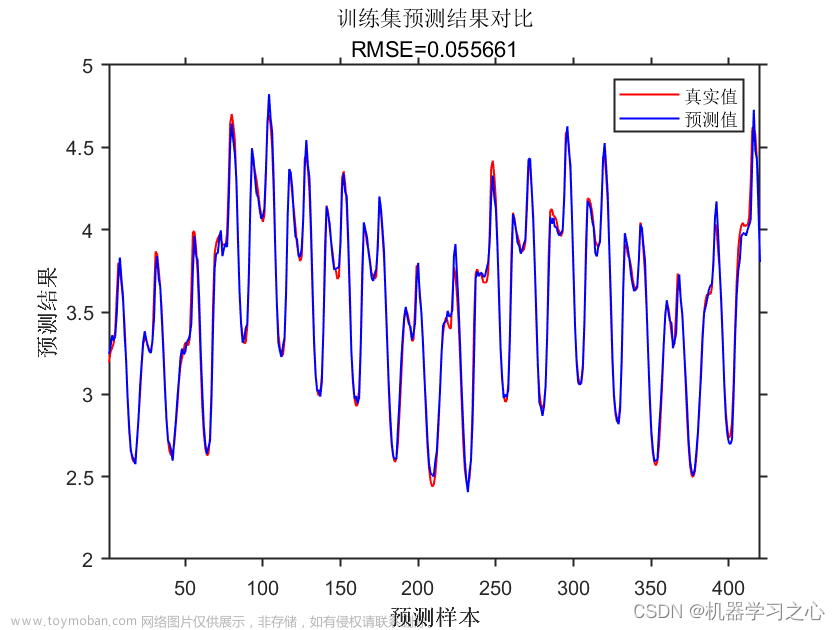
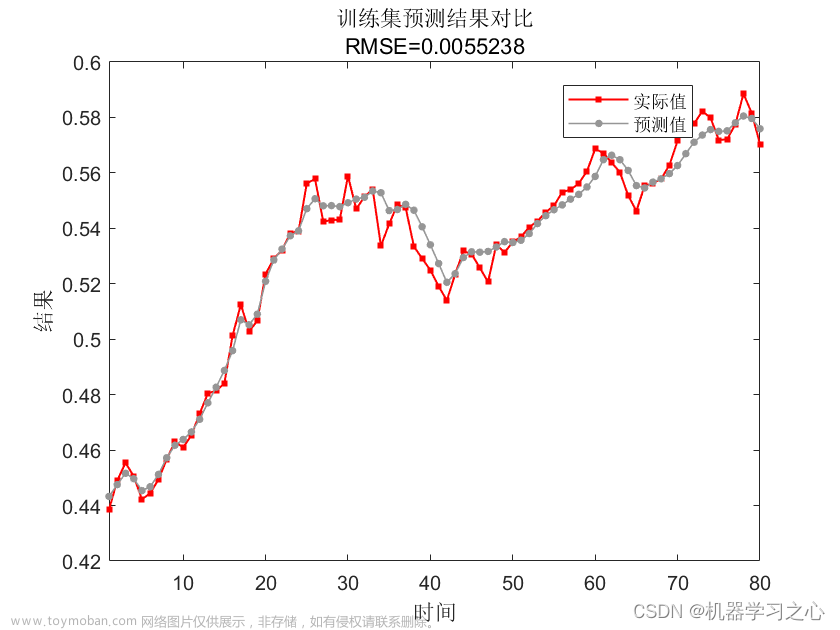
参考博客
(1)导入所需要的包
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
(2)读取数据并展示
data_csv =pd.read_csv("data/data.csv", usecols=[1])
plt.plot(data_csv)
print(data_csv.shape)

(3)数据预处理
缺失值,转化成numpy.ndarray类型,转化成float类型,归一化处理
data_csv = data_csv.dropna()
dataset = data_csv.values
dataset = dataset.astype("float32")
scaler = MinMaxScaler()
dataset = scaler.fit_transform(dataset)
(4)划分训练集和测试集
用30个预测一个
1-30:31
2-31:32
…
94-143:144
需要注意a = [dataset[i: (i + look_back)]],而不是a = dataset[i: (i + look_back)]
look_back = 30
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back):
a = [dataset[i: (i + look_back)]]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
dataX, dataY = create_dataset(dataset, look_back)
dataX.shape,dataY.shape,type(dataX),type(dataY),dataX.dtype,dataY.dtype
 对于 dataX,它的形状为 (114, 1, 30, 1)。其中 114 表示样本数量,1 表示特征数量,30 表示历史时间步的数量,1 表示每个时间步的特征数量。
对于 dataX,它的形状为 (114, 1, 30, 1)。其中 114 表示样本数量,1 表示特征数量,30 表示历史时间步的数量,1 表示每个时间步的特征数量。
输出部分dataX和dataY的值
print(dataX[:2],dataY[:2])

数据集搭好之后,对数据集进行7:3的划分
train_size=int(len(dataX)*0.7)
test_size=len(dataX)-train_size
train_x=dataX[:train_size]
train_y=dataY[:train_size]
test_x=dataX[train_size:]
test_y=dataY[train_size:]
print(train_size)

train_x=torch.from_numpy(train_x)
train_x=train_x.squeeze(3)
train_y=torch.from_numpy(train_y)
test_x=torch.from_numpy(test_x)
test_y=torch.from_numpy(test_y)
print(train_x.shape,test_x.shape)

对以上代码进行解释:
- 将
numpy.ndarray类型的转化成Tensor类型 - 即将 NumPy 数组 train_x 转换为 PyTorch 张量
- 转换之后神经网络才能计算
-
sequeeze(3)是将train_x从([79,1,30,1])变为([79,1,30]) -
test_x不需要sequeeze(3)的原因是:在pytorch中,卷积池化等操作需要输入的是四维张量(样本数,时间步长,特征数,1)**(有待考究)**test在后面没用到
(5)构建RNN回归模型
class rnn_reg(torch.nn.Module):
def __init__(self,input_size,hidden_size,out_size=1,num_layers=2)->None:
super(rnn_reg,self).__init__()
self.rnn=torch.nn.RNN(input_size,hidden_size,num_layers)
self.reg=torch.nn.Linear(hidden_size,out_size)
def forward(self,x):
x,_=self.rnn(x)
seq,batch_size,hidden_size=x.shape
x=x.reshape(seq*batch_size,hidden_size)
x=self.reg(x)
x.reshape(seq,batch_size,-1)
return x
net=rnn_reg(look_back,16)
criterion=torch.nn.MSELoss()
optimizer=torch.optim.Adam(net.parameters(),lr=1e-2)
对以上代码进行解释:
-
rnn_reg 的子类,继承torch.nn.Module,用于创建自定义的神经网络模型
-
__ init__是rnn_reg 类构造函数,用于初始化模型的参数

-
super(rnn_reg, self).__init__():调用父类 torch.nn.Module 的构造函数 -
self.rnn = torch.nn.RNN(input_size, hidden_size, num_layers):创建了一个 RNN 层。input_size 表示输入特征的维度,hidden_size 表示隐藏状态的维度,num_layers 表示 RNN 的层数。 -
self.reg = torch.nn.Linear(hidden_size, out_size):创建了一个线性层(全连接层),用于将 RNN 的隐藏状态映射到输出特征维度。 -
def forward(self, x):这是 rnn_reg 类的前向传播方法。它接受输入 x,并定义了模型的前向计算过程。
-
-
x, _ = self.rnn(x):将输入 x 传递给 RNN 层进行前向计算。_ 表示隐藏状态,由于这里不需要使用隐藏状态,所以用下划线 _ 进行占位。 -
seq, batch_size, hidden_size = x.shape:获取 RNN 输出 x 的形状信息,其中 seq 表示序列长度,batch_size 表示批次大小,hidden_size 表示隐藏状态的维度。 -
x = x.reshape(seq * batch_size, hidden_size): 将 x 重塑为形状 (seq * batch_size, hidden_size),以便通过线性层进行映射。 -
x = self.reg(x):将重塑后的 x 传递给线性层 self.reg 进行映射操作。 -
x.reshape(seq, batch_size, -1):将输出 x 重塑为形状 (seq, batch_size, -1),以便与输入保持相同的维度。 -
return x:返回最终的输出 x。 -
net = rnn_reg(look_back, 16):创建了一个 rnn_reg 类的实例 net。look_back 表示输入特征的维度,16 表示隐藏状态的维度。 -
criterion = torch.nn.MSELoss():定义了损失函数,使用均方误差(MSE)作为损失函数。 -
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2):定义了优化器,使用 Adam 优化算法来更新模型的参数,学习率为 1e-2。
输出一下设置的模型内的一些层数的维度:
for param_tensor in net.state_dict():
print(param_tensor,'\t',net.state_dict()[param_tensor].size())

(6)构造训练函数
设置训练1000次,每100次输出一次损失
running_loss=0.0
for epoch in range(1000):
var_x=train_x
var_y=train_y
out=net(var_x)
loss=criterion(out,var_y)
running_loss+=loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if(epoch+1)%100==0:
print('Epoch:{},loss:{:.5f}'.format(epoch+1,running_loss/100))
running_loss=0.0

对以上代码进行解释:
-
running_loss,用于记录每个训练周期的累计损失。 -
out=net(var_x)这个out就是红框标出的需要预测的预测值,即将输入数据 var_x 通过神经网络模型 net 进行前向传播,得到输出 out。
-
loss = criterion(out, var_y):计算模型输出 out 和目标标签 var_y 之间的损失,使用预先定义的损失函数 criterion(在代码中是均方误差)。 -
loss.item()方法用于获取 loss 的数值(标量),然后将其加到 running_loss 上。 -
optimizer.zero_grad():清空优化器中之前的梯度信息,以便进行下一次的反向传播。 -
loss.backward():执行反向传播,计算损失函数关于模型参数的梯度。 -
optimizer.step():这行代码根据计算得到的梯度更新模型参数,使用优化器中定义的Adam优化算法 - print输出平均损失
(7)对整个数据集进行预测
net = net.eval() # 转换成测试模式
data_x = dataX.reshape(-1, 1, look_back)
data_x = torch.from_numpy(data_x).to(torch.float32)
var_data = data_x
pred_test = net(var_data) # 测试集的预测结果
pred_test = pred_test.view(-1).data.numpy()
对上述代码解释:

-
data_x = torch.from_numpy(data_x).to(torch.float32): 这行代码将 NumPy 数组 data_x 转换为 PyTorch 的 Tensor 对象,并将数据类型设置为 torch.float32。这是为了与神经网络模型的数据类型匹配。 -
pred_test = pred_test.view(-1).data.numpy(): 这行代码对预测结果进行处理,首先使用 view(-1) 将输出结果展平为一维张量,然后使用 data.numpy() 将结果转换为 NumPy 数组,以便后续的分析和可视化。
(8)可视化展示
这里因为用30个预测1个,所以dataset进行了切片(总共114)
plt.plot(pred_test, 'deeppink', label='prediction')
plt.plot(dataset[look_back:], 'green', label='real')
plt.legend(loc='best')

(9)MSE为评价指标
这里因为用30个预测1个,所以计算MSE的也不包括前30个数据,否则没法去计算文章来源:https://www.toymoban.com/news/detail-796749.html
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(dataset[look_back:], pred_test)
print(MSE)
 文章来源地址https://www.toymoban.com/news/detail-796749.html
文章来源地址https://www.toymoban.com/news/detail-796749.html
到了这里,关于循环神经网络-单变量序列预测详解(pytorch)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!